Администрирование кластера
Lower-level detail relevant to creating or administering a Kubernetes cluster.
Обзор администрирования кластера предназначен для всех, кто создает или администрирует кластер Kubernetes. Это предполагает некоторое знакомство с основными концепциями Kubernetes.
Планирование кластера
См. Руководства в разделе настройка для получения примеров того, как планировать, устанавливать и настраивать кластеры Kubernetes. Решения, перечисленные в этой статье, называются distros.
Примечание:
не все дистрибутивы активно поддерживаются. Выбирайте дистрибутивы, протестированные с последней версией Kubernetes.
Прежде чем выбрать руководство, вот некоторые соображения:
- Вы хотите опробовать Kubernetes на вашем компьютере или собрать много узловой кластер высокой доступности? Выбирайте дистрибутивы, наиболее подходящие для ваших нужд.
- Будете ли вы использовать размещенный кластер Kubernetes, такой, как Google Kubernetes Engine или разместите собственный кластер?
- Будет ли ваш кластер в помещении или в облаке (IaaS)? Kubernetes не поддерживает напрямую гибридные кластеры. Вместо этого вы можете настроить несколько кластеров.
- Если вы будете настраивать Kubernetes в помещении (локально), подумайте, какая сетевая модель подходит лучше всего.
- Будете ли вы запускать Kubernetes на оборудований "bare metal" или на виртуальных машинах (VMs)?
- Вы хотите запустить кластер или планируете активно разворачивать код проекта Kubernetes? В последнем случае выберите активно разрабатываемый дистрибутив. Некоторые дистрибутивы используют только двоичные выпуски, но предлагают более широкий выбор.
- Ознакомьтесь с компонентами необходимые для запуска кластера.
Управление кластером
Обеспечение безопасности кластера
Обеспечение безопасности kubelet
Дополнительные кластерные услуги
1 - Сертификаты
Чтобы узнать, как генерировать сертификаты для кластера, см. раздел Сертификаты.
2 - Управление ресурсами
Итак, вы развернули приложение и настроили доступ к нему с помощью сервиса. Что дальше? Kubernetes предоставляет ряд инструментов, помогающих управлять развертыванием приложений, включая их масштабирование и обновление. Среди особенностей, которые мы обсудим более подробно, — конфигурационные файлы и лейблы.
Организация конфигураций ресурсов
Многие приложения требуют создания нескольких ресурсов типа Deployment и Service. Управление ими можно упростить, сгруппировав в один YAML-файл (со строкой "---" в качестве разделителя). Например:
apiVersion: v1
kind: Service
metadata:
name: my-nginx-svc
labels:
app: nginx
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Можно создавать сразу несколько ресурсов:
kubectl apply -f https://k8s.io/examples/application/nginx-app.yaml
service/my-nginx-svc created
deployment.apps/my-nginx created
Ресурсы будут создаваться в порядке, в котором они описаны в файле. Таким образом, первым лучше всего описать сервис — это позволит планировщику распределять Pod'ы этого сервиса по мере их создания контроллером (контроллерами), например, Deployment'ом.
kubectl apply также может принимать сразу несколько аргументов -f:
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-svc.yaml -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
Кроме того, можно указывать директории вместо отдельных файлов или в дополнение ним:
kubectl apply -f https://k8s.io/examples/application/nginx/
kubectl прочитает все файлы с расширениями .yaml, .yml или .json.
Рекомендуется размещать ресурсы, имеющие отношение к одному микросервису или уровню приложения, в одном файле, а также группировать все файлы, связанные с приложением, в одной директории. Если уровни вашего приложения связываются друг с другом через DNS, можно развернуть все компоненты стека совместно.
Также в качестве источника конфигурации можно указать URL — это удобно при создании/настройке с использованием конфигурационных файлов, размещенных на GitHub:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/website/main/content/en/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx created
Пакетные операции в kubectl
Создание ресурсов — не единственная операция, которую kubectl может выполнять в рамках одной команды. Этот инструмент также способен извлекать имена ресурсов из конфигурационных файлов для выполнения других операций, в частности, для удаления созданных ресурсов:
kubectl delete -f https://k8s.io/examples/application/nginx-app.yaml
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
В случае двух ресурсов их можно перечислить в командной строке, используя синтаксис вида resource/name:
kubectl delete deployments/my-nginx services/my-nginx-svc
При большем количестве ресурсов удобнее указать селектор (запрос по лейблу) с помощью -l или --selector, который отфильтрует ресурсы по их лейблам:
kubectl delete deployment,services -l app=nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
Поскольку kubectl выводит имена ресурсов в том же синтаксисе, что и получает, можно выстраивать цепочки операций с помощью $() или xargs:
kubectl get $(kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service)
kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service | xargs -i kubectl get {}
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
Приведенные выше команды сначала создают ресурсы в разделе examples/application/nginx/, выводят о них информацию в формате -o name (то есть в виде пары resource/name). Затем в результатах производится поиск по "service" (grep), и информация о найденных ресурсах выводится с помощью kubectl get.
Если ресурсы хранятся в нескольких поддиректориях в пределах одной директории, можно рекурсивно выполнять операции и в этих поддиректориях, указав --recursive или -R наряду с флагом --filename, -f.
Предположим, что существует директория project/k8s/development, в которой хранятся все манифесты, необходимые для dev-окружения, организованные по типу ресурсов:
project/k8s/development
├── configmap
│ └── my-configmap.yaml
├── deployment
│ └── my-deployment.yaml
└── pvc
└── my-pvc.yaml
По умолчанию при выполнении массовых операций над project/k8s/development команда остановится на первом уровне, не обрабатывая поддиректории. К примеру, попытка создать ресурсы, описанные в этой директории, приведет к ошибке:
kubectl apply -f project/k8s/development
error: you must provide one or more resources by argument or filename (.json|.yaml|.yml|stdin)
Вместо этого следует указать флаг --recursive или -R с флагом --filename, -f:
kubectl apply -f project/k8s/development --recursive
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
Флаг --recursive работает с любыми операциями, принимающими флаг --filename, -f, например: kubectl {create, get, delete, describe, rollout} и т.д.
Флаг --recursive также работает для нескольких аргументов -f:
kubectl apply -f project/k8s/namespaces -f project/k8s/development --recursive
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
В разделе Инструмент командной строки kubectl доступна дополнительная информация о kubectl.
Эффективное использование лейблов
Во всех примерах, рассмотренных до этого момента, к ресурсам прикреплялся лишь один лейбл. Однако существуют сценарии, когда необходимо использовать несколько лейблов, чтобы отличить наборы ресурсов друг от друга.
Например, разные приложения могут использовать разные значения для лейбла app, а в случае многоуровневого приложения вроде гостевой книги лейблы могут указывать на соответствующий уровень. Например, у фронтенда могут быть следующие лейблы:
labels:
app: guestbook
tier: frontend
в то время как у master'а и slave'а Redis будут лейблы tier и, возможно, даже дополнительный лейбл role:
labels:
app: guestbook
tier: backend
role: master
и
labels:
app: guestbook
tier: backend
role: slave
Лейблы позволяют группировать ресурсы по любому параметру с соответствующим лейблом:
kubectl apply -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE APP TIER ROLE
guestbook-fe-4nlpb 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-ght6d 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-jpy62 1/1 Running 0 1m guestbook frontend <none>
guestbook-redis-master-5pg3b 1/1 Running 0 1m guestbook backend master
guestbook-redis-slave-2q2yf 1/1 Running 0 1m guestbook backend slave
guestbook-redis-slave-qgazl 1/1 Running 0 1m guestbook backend slave
my-nginx-divi2 1/1 Running 0 29m nginx <none> <none>
my-nginx-o0ef1 1/1 Running 0 29m nginx <none> <none>
kubectl get pods -lapp=guestbook,role=slave
NAME READY STATUS RESTARTS AGE
guestbook-redis-slave-2q2yf 1/1 Running 0 3m
guestbook-redis-slave-qgazl 1/1 Running 0 3m
Канареечные развертывания
Еще один сценарий, в котором применение нескольких лейблов как нельзя кстати, — дифференциация развертываний отдельных релизов или конфигураций одного и того же компонента. Как правило, новая версия приложения (указанная с помощью тега образа в шаблоне Pod'а) запускается в так называемом канареечном (canary) развертывании параллельно с предыдущей версией. Далее на нее направляется часть реального production-трафика.
В примере ниже лейбл track помогает различить релизы.
У основного, стабильного релиза он будет иметь значение stable:
name: frontend
replicas: 3
...
labels:
app: guestbook
tier: frontend
track: stable
...
image: gb-frontend:v3
У нового релиза фронтенда гостевой книги значение этого лейбла будет другим (canary), чтобы два набора Pod'ов не пересекались:
name: frontend-canary
replicas: 1
...
labels:
app: guestbook
tier: frontend
track: canary
...
image: gb-frontend:v4
Чтобы охватить оба набора реплик, сервис фронтенда следует настроить на выбор общего подмножества их лейблов (т.е. опустить лейбл track). В результате трафик будет поступать на обе версии приложения:
selector:
app: guestbook
tier: frontend
При этом число стабильных и канареечных реплик можно менять, регулируя долю production-трафика, которую будет получать каждая версия приложения (три к одному в нашем случае). Убедившись в стабильности новой версии, можно поменять значение ее лейбла track с canary на stable.
Более подробный пример доступен в руководстве по развертыванию Ghost.
Обновление лейблов
Иногда возникает необходимость поменять лейблы у существующих Pod'ов и других ресурсов перед созданием новых. Сделать это можно с помощью команды kubectl label. Например, чтобы промаркировать все Pod'ы NGINX как имеющие отношение к фронтенду, выполните следующую команду:
kubectl label pods -l app=nginx tier=fe
pod/my-nginx-2035384211-j5fhi labeled
pod/my-nginx-2035384211-u2c7e labeled
pod/my-nginx-2035384211-u3t6x labeled
Сначала она выберет все Pod'ы с лейблом app=nginx, а затем пометит их лейблом tier=fe. Чтобы просмотреть список этих Pod'ов, выполните:
kubectl get pods -l app=nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
Будут выведены все Pod'ы app=nginx с дополнительным столбцом tier (задается с помощью -L или --label-columns).
Дополнительную информацию можно найти в разделах Лейблы и kubectl label.
Обновление аннотаций
Иногда возникает потребность навесить на ресурсы аннотации. Аннотации — это произвольные неидентифицирующие метаданные для извлечения клиентами API (инструментами, библиотеками и т.п.). Добавить аннотацию можно с помощью команды kubectl annotate. Например:
kubectl annotate pods my-nginx-v4-9gw19 description='my frontend running nginx'
kubectl get pods my-nginx-v4-9gw19 -o yaml
apiVersion: v1
kind: pod
metadata:
annotations:
description: my frontend running nginx
...
Для получения дополнительной информации обратитесь к разделу Аннотации и описанию команды kubectl annotate.
Масштабирование приложения
Для масштабирования приложения можно воспользоваться инструментом kubectl. Например, следующая команда уменьшит число реплик с 3 до 1:
kubectl scale deployment/my-nginx --replicas=1
deployment.apps/my-nginx scaled
После ее применения количество Pod'ов под управлением соответствующего объекта Deployment сократится до одного:
kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
Чтобы система автоматически выбирала необходимое количество реплик NGINX в диапазоне от 1 до 3, выполните следующую команду:
kubectl autoscale deployment/my-nginx --min=1 --max=3
horizontalpodautoscaler.autoscaling/my-nginx autoscaled
Теперь количество реплик NGINX будет автоматически увеличиваться и уменьшаться по мере необходимости.
Для получения дополнительной информации см. разделы kubectl scale, kubectl autoscale и horizontal pod autoscaler.
Обновление ресурсов "на месте"
Иногда возникает необходимость внести мелкие обновления в созданные ресурсы, не требующие их пересоздания.
kubectl apply
Хранить конфигурационные файлы рекомендуемтся в системе контроля версий (см. конфигурация как код). В этом случае их можно будет поддерживать и версионировать вместе с кодом ресурсов, которые те конфигурируют. Далее с помощью команды kubectl apply изменения, внесенные в конфигурацию, можно применить к кластеру.
Она сравнит новую версию конфигурации с предыдущей и применит внесенные изменения, не меняя параметры, установленные автоматически, не затронутые новой редакцией конфигурации.
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx configured
Обратите внимание, что kubectl apply добавляет к ресурсу аннотацию, помогающую отслеживать изменения в конфигурации с момента предыдущего вызова. При вызове kubectl apply проводит трехстороннее сравнение (three-way diff) предыдущей конфигурации, ее текущей и новой версий, которое определяет, какие правки следует внести в ресурс.
На данный момент ресурсы в Kubernetes создаются без данной аннотации, поэтому при первом вызове kubectl apply проведет двустороннее сравнение входных данных и текущей конфигурации ресурса. Кроме того, она не cможет определить, какие свойства, заданные при создании ресурса, требуют удаления (соответственно, не будет их удалять).
При всех последующих вызовах kubectl apply и других команд, меняющих конфигурацию, таких как kubectl replace и kubectl edit, аннотация будет обновляться. В результате kubectl apply сможет проводить трехстороннее сравнение (three-way diff), определяя, какие свойства требуют удаления, и удалять их.
kubectl edit
Ресурсы также можно обновлять с помощью команды kubectl edit:
kubectl edit deployment/my-nginx
По сути, kubectl edit объединяет в себе логику нескольких команд, упрощая жизнь пользователям: сначала она получает (get) ресурс, вызывает текстовый редактор, а затем применяет (apply) обновленную конфигурацию:
kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
vi /tmp/nginx.yaml
# внесите правки и сохраните файл
kubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
rm /tmp/nginx.yaml
Обратите внимание, что задать предпочитаемый текстовый редактор можно с помощью переменных окружения EDITOR или KUBE_EDITOR.
За дополнительной информацией обратитесь к разделу kubectl edit.
kubectl patch
Команда kubectl patch обновляет объекты API "на месте". Она поддерживает форматы JSON patch, JSON merge patch и strategic merge patch. См. разделы Обновление объектов API "на месте" с помощью kubectl patch и kubectl patch.
Обновления, требующие перерыва в работе
Иногда может понадобиться обновить поля ресурса, которые нельзя изменить после инициализации, или возникнет необходимость немедленно внести рекурсивные изменения, например, "починить" сбойные Pod'ы, созданные Deployment'ом. Для этого можно воспользоваться командой replace --force, которая удалит и пересоздаст ресурс. Вот как можно внести правки в исходный файл конфигурации в нашем примере:
kubectl replace -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml --force
deployment.apps/my-nginx deleted
deployment.apps/my-nginx replaced
Обновление приложения без перерыва в работе
В какой-то момент возникнет необходимость обновить развернутое приложение. Обычно это делают, указывая новый образ или тег образа, как в приведенном выше сценарии канареечного развертывания. kubectl поддерживает несколько видов обновлений, каждый из которых подходит для разных сценариев.
Ниже будет рассказано, как создавать и обновлять приложения с помощью объектов Deployment.
Предположим, что в кластере используется версия NGINX 1.14.2:
kubectl create deployment my-nginx --image=nginx:1.14.2
deployment.apps/my-nginx created
с тремя репликами (чтобы старые и новые ревизии могли сосуществовать):
kubectl scale deployment my-nginx --current-replicas=1 --replicas=3
deployment.apps/my-nginx scaled
Чтобы перейти на версию 1.16.1, измените значение параметра .spec.template.spec.containers[0].image с nginx:1.14.2 на nginx:1.16.1:
kubectl edit deployment/my-nginx
Вот и все! Deployment декларативно обновит развернутое приложение NGINX "за кулисами". При этом Kubernetes проследит, чтобы число недоступных реплик в каждый момент времени не превышало определенного значения, а также за тем, чтобы количество новых реплик не превышало определенного предела, установленного для желаемого числа Pod'ов. Более подробную информацию об этом можно получить в разделе Deployment.
Что дальше
3 - Сеть в кластере
Сеть — важная часть Kubernetes, но понять, как именно она работает, бывает непросто. Существует 4 уникальных сетевых проблемы, которые требуют внимнаия:
- Высокосвязанные коммуникации между контейнерами: решается организацией коммуникации между Pod'ами и
localhost.
- Связь Pod'ов друг с другом (Pod-to-Pod): именно ей уделяется основное внимание в этом документе.
- Связь Pod'ов с сервисами (Pod-to-Service): подробнее об этом можно почитать в разделе Сервисы.
- Связь внешних систем с сервисами (External-to-Service): информация о данных коммуникациях также приведена в разделе Сервисы.
Суть Kubernetes — в организации совместного использования хостов приложениями. Обычно совместное использование подразумевает, что два приложения не могут задействовать одни и те же порты. Создать единую глобальную схему использования портов очень сложно. В результате пользователи рискуют получить сложноустранимые проблемы на уровне кластера.
Динамическое распределение портов значительно усложняет систему: каждое приложение должно уметь принимать порты в виде флагов-параметров, серверы API должны уметь вставлять динамические номера портов в конфигурационные блоки, сервисы должны знать, как найти друг друга и т.п. Вместо того чтобы пытаться разобраться со всем этим, Kubernetes использует иной подход.
Больше узнать о сетевой модели Kubernetes можно в соответствующем разделе.
Реализация сетевой модели Kubernetes
Сетевая модель реализуется средой исполнения для контейнеров на узлах. Наиболее распространенные среды исполнения используют плагины Container Network Interface (CNI) для управления сетью и обеспечения безопаснояти коммуникаций. Существует множество различных плагинов CNI от разных разработчиков. Некоторые из них предлагают только базовые функции, такие как добавление и удаление сетевых интерфейсов. Другие позволяют проводить интеграцию с различныеми системами оркестрации контейнеров, поддерживают запуск нескольких CNI-плагинов/расширенные функции IPAM и т.д.
Неполный список сетевых аддонов, поддерживаемых Kubernetes, приведен на соответствующей странице в разделе "Сеть и сетевая политика".
Что дальше
Подробнее о разработке сетевой модели, принципах, лежащих в ее основе, и некоторых планах на будущее можно узнать из соответствующего документа.
4 - Архитектура для сбора логов
Логи помогают понять, что происходит внутри приложения. Они особенно полезны для отладки проблем и мониторинга деятельности кластера. У большинства современных приложений имеется тот или иной механизм сбора логов. Контейнерные движки в этом смысле не исключение. Самый простой и наиболее распространенный метод сбора логов для контейнерных приложений задействует потоки stdout и stderr.
Однако встроенной функциональности контейнерного движка или среды исполнения обычно недостаточно для организации полноценного решения по сбору логов.
Например, может возникнуть необходимость просмотреть логи приложения при аварийном завершении работы Pod'а, его вытеснении (eviction) или "падении" узла.
В кластере у логов должно быть отдельное хранилище и жизненный цикл, не зависящий от узлов, Pod'ов или контейнеров. Эта концепция называется сбор логов на уровне кластера.
Архитектуры для сбора логов на уровне кластера требуют отдельного бэкенда для их хранения, анализа и выполнения запросов. Kubernetes не имеет собственного решения для хранения такого типа данных. Вместо этого существует множество продуктов для сбора логов, которые прекрасно с ним интегрируются. В последующих разделах описано, как обрабатывать логи и хранить их на узлах.
Основы сбора логов в Kubernetes
В примере ниже используется спецификация Pod с контейнером для отправки текста в стандартный поток вывода раз в секунду.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Запустить его можно с помощью следующей команды:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
Результат будет таким:
Получить логи можно с помощью команды kubectl logs, как показано ниже:
Результат будет таким:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
Команда kubectl logs --previous позволяет извлечь логи из предыдущего воплощения контейнера. Если в Pod'е несколько контейнеров, выбрать нужный для извлечения логов можно с помощью флага -c:
kubectl logs counter -c count
Для получения дополнительной информации см. документацию по kubectl logs.
Сбор логов на уровне узла
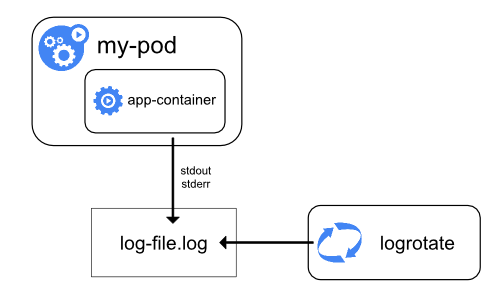
Среда исполнения для контейнера обрабатывает и перенаправляет любой вывод в потоки stdout и stderr приложения. Docker Engine, например, перенаправляет эти потоки драйверу журналирования, который в Kubernetes настроен на запись в файл в формате JSON.
Примечание:
JSON-драйвер Docker для сбора логов рассматривает каждую строку как отдельное сообщение. В данном случае поддержка многострочных сообщений отсутствует. Обработка многострочных сообщений должна выполняться на уровне лог-агента или выше.
По умолчанию, если контейнер перезапускается, kubelet сохраняет один завершенный контейнер с его логами. Если Pod вытесняется с узла, все соответствующие контейнеры также вытесняются вместе с их логами.
Важным моментом при сборе логов на уровне узла является их ротация, чтобы логи не занимали все доступное место на узле. Kubernetes не отвечает за ротацию логов, но способен развернуть инструмент для решения этой проблемы. Например, в кластерах Kubernetes, развертываемых с помощью скрипта kube-up.sh, имеется инструмент logrotate, настроенный на ежечасный запуск. Также можно настроить среду исполнения контейнера на автоматическую ротацию логов приложения.
Подробную информацию о том, как kube-up.sh настраивает логирование для образа COS на GCP, можно найти в соответствующем скрипте configure-helper.
При использовании среды исполнения контейнера CRI kubelet отвечает за ротацию логов и управление структурой их директории. kubelet передает данные среде исполнения контейнера CRI, а та сохраняет логи контейнера в указанное место. С помощью параметров containerLogMaxSize и containerLogMaxFiles в конфигурационном файле kubelet'а можно настроить максимальный размер каждого лог-файла и максимальное число таких файлов для каждого контейнера соответственно.
При выполнении команды kubectl logs (как в примере из раздела про основы сбора логов) kubelet на узле обрабатывает запрос и считывает данные непосредственно из файла журнала. Затем он возвращает его содержимое.
Примечание:
Если ротацию выполнила внешняя система или используется среда исполнения контейнера CRI, команде kubectl logs будет доступно содержимое только последнего лог-файла. Например, имеется файл размером 10 МБ, logrotate выполняет ротацию, и получается два файла: первый размером 10 МБ, второй - пустой. В этом случае kubectl logs вернет второй лог-файл (пустой).
Логи системных компонентов
Существует два типа системных компонентов: те, которые работают в контейнере, и те, которые работают за пределами контейнера. Например:
- планировщик Kubernetes и kube-proxy выполняются в контейнере;
- kubelet и среда исполнения контейнера работают за пределами контейнера.
На машинах с systemd среда исполнения и kubelet пишут в journald. Если systemd отсутствует, среда исполнения и kubelet пишут в файлы .log в директории /var/log. Системные компоненты внутри контейнеров всегда пишут в директорию /var/log, обходя механизм ведения логов по умолчанию. Они используют библиотеку для сбора логов klog. Правила сбора логов и рекомендации можно найти в соответствующей документации.
Как и логи контейнеров, логи системных компонентов в директории /var/log необходимо ротировать. В кластерах Kubernetes, созданных с помощью скрипта kube-up.sh, эти файлы настроены на ежедневную ротацию с помощью инструмента logrotate или при достижении 100 МБ.
Архитектуры для сбора логов на уровне кластера
Kubernetes не имеет собственного решения для сбора логов на уровне кластера, но есть общие подходы, которые можно рассмотреть. Вот некоторые из них:
- использовать агент на уровне узлов (запускается на каждом узле);
- внедрить в Pod с приложением специальный sidecar-контейнер для сбора логов;
- отправлять логи из приложения непосредственно в бэкенд.
Использование агента на уровне узлов
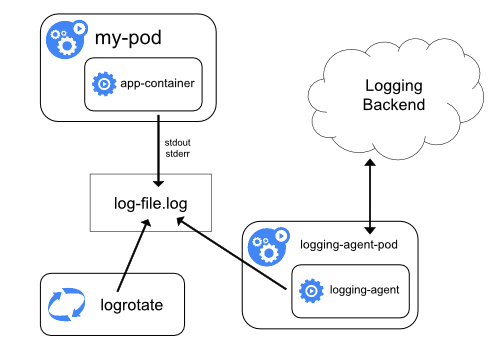
Сбор логов на уровне кластера можно реализовать, запустив node-level-агент на каждом узле. Лог-агент — это специальный инструмент, который предоставляет доступ к логам или передает их бэкенду. Как правило, лог-агент представляет собой контейнер с доступом к директории с файлами логов всех контейнеров приложений на этом узле.
Поскольку лог-агент должен работать на каждом узле, рекомендуется запускать его как DaemonSet.
Сбор логов на уровне узла предусматривает запуск одного агента на узел и не требует изменений в приложениях, работающих на узле.
Контейнеры пишут в stdout и stderr, но без согласованного формата. Агент на уровне узла собирает эти логи и направляет их на агрегацию.
Сбор логов с помощью sidecar-контейнера с лог-агентом
Sidecar-контейнер можно использовать одним из следующих способов:
- sidecar-контейнер транслирует логи приложений на свой собственный
stdout;
- в sidecar-контейнере работает агент, настроенный на сбор логов из контейнера приложения.
Транслирующий sidecar-контейнер
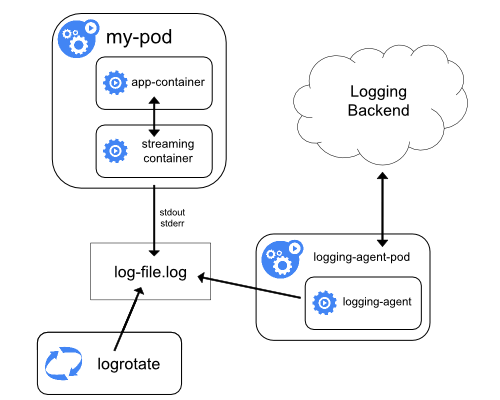
Настроив sidecar-контейнеры на вывод в их собственные потоки stdout и stderr, можно воспользоваться преимуществами kubelet и лог-агента, которые уже работают на каждом узле. Sidecar-контейнеры считывают логи из файла, сокета или journald. Затем каждый из них пишет логи в собственный поток stdout или stderr.
Такой подход позволяет разграничить потоки логов от разных частей приложения, некоторые из которых могут не поддерживать запись в stdout или stderr. Логика, управляющая перенаправлением логов, проста и не требует значительных ресурсов. Кроме того, поскольку stdout и stderr обрабатываются kubelet'ом, можно использовать встроенные инструменты вроде kubectl logs.
Предположим, к примеру, что в Pod'е работает один контейнер, который пишет логи в два разных файла в двух разных форматах. Вот пример конфигурации такого Pod'а:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Не рекомендуется писать логи разных форматов в один и тот же поток, даже если удалось перенаправить оба компонента в stdout контейнера. Вместо этого можно создать два sidecar-контейнера. Каждый из них будет забирать определенный лог-файл с общего тома и перенаправлять логи в свой stdout.
Вот пример конфигурации Pod'а с двумя sidecar-контейнерами:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Доступ к каждому потоку логов такого Pod'а можно получить отдельно, выполнив следующие команды:
kubectl logs counter count-log-1
Результат будет таким:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
Результат будет таким:
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
Агент на уровне узла, установленный в кластере, подхватывает эти потоки логов автоматически без дополнительной настройки. При желании можно настроить агент на парсинг логов в зависимости от контейнера-источника.
Обратите внимание: несмотря на низкое использование процессора и памяти (порядка нескольких milliCPU для процессора и пары мегабайт памяти), запись логов в файл и их последующая потоковая передача в stdout может вдвое увеличить нагрузку на диск. Если приложение пишет в один файл, рекомендуется установить /dev/stdout в качестве адресата, нежели использовать подход с транслирующим контейнером.
Sidecar-контейнеры также можно использовать для ротации файлов логов, которые не могут быть ротированы самим приложением. В качестве примера можно привести небольшой контейнер, периодически запускающий logrotate. Однако рекомендуется использовать stdout и stderr напрямую, а управление политиками ротации и хранения оставить kubelet'у.
Sidecar-контейнер с лог-агентом
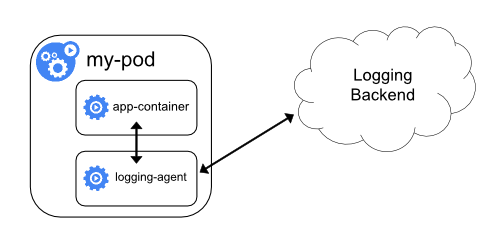
Если лог-агент на уровне узла недостаточно гибок для ваших потребностей, можно создать sidecar-контейнер с отдельным лог-агентом, специально настроенным на работу с приложением.
Примечание:
Работа лог-агента в sidecar-контейнере может привести к значительному потреблению ресурсов. Более того, доступ к этим журналам с помощью kubectl logs будет невозможен, поскольку они не контролируются kubelet'ом.
Ниже приведены два файла конфигурации sidecar-контейнера с лог-агентом. Первый содержит ConfigMap для настройки fluentd.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Примечание:
За информацией о настройке fluentd обратитесь к его
документации.
Второй файл описывает Pod с sidecar-контейнером, в котором работает fluentd. Pod монтирует том с конфигурацией fluentd.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
В приведенных выше примерах fluentd можно заменить на другой лог-агент, считывающий данные из любого источника в контейнере приложения.
Прямой доступ к логам из приложения
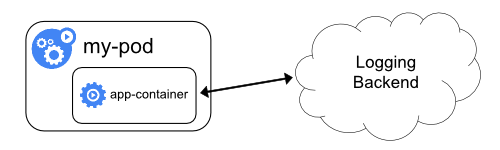
Сбор логов приложения на уровне кластера, при котором доступ к ним осуществляется напрямую, выходит за рамки Kubernetes.
5 - Логи системных компонентов
Логи системных компонентов регистрируют события, происходящие в кластере, что может быть очень полезно при отладке. Степень детализации логов настраивается. Так, в логах низкой детализации будет содержаться только информация об ошибках внутри компонента, в то время как логи высокой детализации будут содержать пошаговую трассировку событий (доступ по HTTP, изменения состояния Pod'а, действия контроллера, решения планировщика).
Klog
klog — библиотека Kubernetes для сбора логов. Отвечает за генерацию соответствующих сообщений для системных компонентов оркестратора.
Дополнительные сведения о настройке klog можно получить в Справке по CLI.
В настоящее время ведется работа по упрощению процесса сбора логов в компонентах Kubernetes. Приведенные ниже флаги командной строки klog устарели, начиная с версии Kubernetes 1.23, и будут удалены в одном из будущих релизов:
--add-dir-header--alsologtostderr--log-backtrace-at--log-dir--log-file--log-file-max-size--logtostderr--one-output--skip-headers--skip-log-headers--stderrthreshold
Вывод всегда будет записываться в stderr независимо от его формата. Перенаправление вывода должно осуществляться компонентом, который вызывает компонент Kubernetes, например, POSIX-совместимой командной оболочкой или инструментом вроде systemd.
Иногда эти опции недоступны — например, в случае контейнера без дистрибутива (distroless) или системной службы Windows. Тогда kube-log-runner можно использовать в качестве обертки вокруг компонента Kubernetes для перенаправления вывода. Его предварительно собранный исполняемый файл включен в некоторые базовые образы Kubernetes под старым именем /go-runner, а в актуальных бинарных релизах архивов с kubernetes-server и kubernetes-node он называется kube-log-runner.
В таблице ниже показаны соответствия между вызовами kube-log-runner и логикой перенаправления командной оболочки:
| Использование |
Оболочка POSIX (например, Bash) |
kube-log-runner <options> <cmd> |
| Объединить stderr и stdout, вывести в stdout |
2>&1 |
kube-log-runner (default behavior) |
| Перенаправить оба потока в файл лога |
1>>/tmp/log 2>&1 |
kube-log-runner -log-file=/tmp/log |
| Скопировать в файл лога и в stdout |
2>&1 | tee -a /tmp/log |
kube-log-runner -log-file=/tmp/log -also-stdout |
| Перенаправить только stdout в файл лога |
>/tmp/log |
kube-log-runner -log-file=/tmp/log -redirect-stderr=false |
Вывод klog
Пример оригинального "родного" формата klog:
I1025 00:15:15.525108 1 httplog.go:79] GET /api/v1/namespaces/kube-system/pods/metrics-server-v0.3.1-57c75779f-9p8wg: (1.512ms) 200 [pod_nanny/v0.0.0 (linux/amd64) kubernetes/$Format 10.56.1.19:51756]
Сообщение может содержать переносы строк:
I1025 00:15:15.525108 1 example.go:79] This is a message
which has a line break.
Структурированное логирование
СТАТУС ФИЧИ: Kubernetes v1.23 [beta]
Предупреждение:
Переход на структурированное логирование — продолжающийся процесс. Не все сообщения структурированы в текущей версии Kubernetes. При парсинге файлов логов необходимо также обрабатывать неструктурированные сообщения.
Формат логов и сериализация значений могут измениться в будущем.
Структурированное логирование придает определенную структуру сообщениям логов, упрощая программное извлечение информации и сокращая затраты и усилия на их обработку. Код, который генерирует сообщение лога, определяет, используется ли обычный неструктурированный вывод klog или структурированное логирование.
По умолчанию структурированные сообщения форматируются как текст, при этом его формат обратно совместим с традиционным форматом klog:
<klog header> "<message>" <key1>="<value1>" <key2>="<value2>" ...
Пример:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
Строки заключаются в кавычки. Другие значения форматируются с помощью %+v. В результате сообщение может продолжиться на следующей строке в зависимости от типа данных.
I1025 00:15:15.525108 1 example.go:116] "Example" data="This is text with a line break\nand \"quotation marks\"." someInt=1 someFloat=0.1 someStruct={StringField: First line,
second line.}
Контекстное логирование
СТАТУС ФИЧИ: Kubernetes v1.24 [alpha]
Контекстное логирование базируется на структурированном логировании. Речь идет в первую очередь о том, как разработчики используют лог-вызовы: код, основанный на этой концепции, более гибок и поддерживает дополнительные сценарии использования (см. Contextual Logging KEP).
При использовании в компонентах дополнительных функций, таких как WithValues или WithName, записи лога содержат дополнительную информацию, которая передается в функции вызывающей стороной.
В настоящее время за включение контекстного логирования отвечает переключатель функционала StructuredLogging. По умолчанию оно отключено. Соответствующая инфраструктура появилась в версии 1.24 и она не потребовала изменений в компонентах. Команда component-base/logs/example показывает, как использовать новые лог-вызовы и как ведет себя компонент, поддерживающий контекстное логирование.
$ cd $GOPATH/src/k8s.io/kubernetes/staging/src/k8s.io/component-base/logs/example/cmd/
$ go run . --help
...
--feature-gates mapStringBool A set of key=value pairs that describe feature gates for alpha/experimental features. Options are:
AllAlpha=true|false (ALPHA - default=false)
AllBeta=true|false (BETA - default=false)
ContextualLogging=true|false (ALPHA - default=false)
$ go run . --feature-gates ContextualLogging=true
...
I0404 18:00:02.916429 451895 logger.go:94] "example/myname: runtime" foo="bar" duration="1m0s"
I0404 18:00:02.916447 451895 logger.go:95] "example: another runtime" foo="bar" duration="1m0s"
Префикс example и foo="bar" были добавлены вызовом функции, которая пишет в лог сообщение runtime и значение duration="1m0s", при этом вносить изменения в эту функцию не потребовалось.
При отключенном контекстном логировании WithValues и WithName ничего не делают, а вызовы журнала проходят через глобальный логгер klog. Соответственно, эта дополнительная информация более не отображается в логе:
$ go run . --feature-gates ContextualLogging=false
...
I0404 18:03:31.171945 452150 logger.go:94] "runtime" duration="1m0s"
I0404 18:03:31.171962 452150 logger.go:95] "another runtime" duration="1m0s"
Логи в формате JSON
СТАТУС ФИЧИ: Kubernetes v1.19 [alpha]
Предупреждение:
Вывод в формате JSON не поддерживает многие стандартные флаги klog. Список неподдерживаемых флагов klog см. в Справочнике по CLI.
Кроме того, запись в формате JSON не гарантируется (например, во время запуска процесса). Таким образом, если планируется дальнейший парсинг логов, убедитесь, что ваш парсер способен обрабатывать строки лога, которые не являются JSON.
Имена полей и сериализация JSON могут измениться в будущем.
Флаг --logging-format=json переключает формат логов с родного формата klog на JSON. Пример лога в формате JSON (стилистически отформатированном):
{
"ts": 1580306777.04728,
"v": 4,
"msg": "Pod status updated",
"pod":{
"name": "nginx-1",
"namespace": "default"
},
"status": "ready"
}
Специальные ключи:
ts — временная метка в формате времени Unix (обязательный параметр, float);v — детализация (для общей информации — не для сообщений об ошибках, int);err — ошибка (опциональный параметр, string);msg — сообщение (обязательный параметр, string).
Список компонентов, поддерживающих формат JSON:
Уровень детализации лога
Флаг -v задает степень детализации лога. Увеличение значения увеличивает количество регистрируемых событий. Уменьшение значения уменьшает количество регистрируемых событий. Увеличение детализации приводит к тому, что регистрируются все менее значимые события. При уровне детализации, равном 0, регистрируются только критические события.
Местоположение лога
Существует два типа системных компонентов: те, которые работают в контейнере, и те, которые работают за пределами контейнера. Например:
На машинах с systemd среда исполнения и kubelet пишут в journald. В противном случае ведется запись в файлы .log в директории /var/log. Системные компоненты внутри контейнеров всегда пишут в файлы .log в директории /var/log, обходя механизм логирования по умолчанию. Как и логи контейнеров, логи системных компонентов в /var/log нуждаются в ротации. В кластерах Kubernetes, созданных с использованием скрипта kube-up.sh, ротация логов настраивается с помощью инструмента logrotate. logrotate ротирует логи ежедневно или при достижении ими размера в 100 МБ.
Что дальше
6 - Типы прокси-серверов в Kubernetes
На этой странице рассказывается о различных типах прокси-серверов, которые используются в Kubernetes.
Прокси-серверы
При работе с Kubernetes можно столкнуться со следующими типами прокси-серверов:
-
kubectl:
- работает на локальной машине или в Pod'е;
- поднимает канал связи от локальной машины к интерфейсу API-сервера Kubernetes;
- данные от клиента к прокси-серверу передаются по HTTP;
- данные от прокси к серверу API передаются по HTTPS;
- отвечает за обнаружение сервера API;
- добавляет заголовки аутентификации.
-
Прокси-сервер API:
- бастион, встроенный в API-сервер;
- подключает пользователя за пределами кластера к IP-адресам кластера, которые в ином случае могут оказаться недоступными;
- входит в процессы сервера API;
- данные от клиента к прокси-серверу передаются по HTTPS (или по HTTP, если сервер API настроен соответствующим образом);
- данные от прокси-сервера к цели передаются по HTTP или HTTPS в зависимости от настроек прокси;
- используется для доступа к узлам, Pod'ам или сервисам;
- при подключении к сервису выступает балансировщиком нагрузки.
-
kube proxy:
- работает на каждом узле;
- обрабатывает трафик UDP, TCP и SCTP;
- "не понимает" HTTP;
- выполняет функции балансировщика нагрузки;
- используется только для доступа к сервисам.
-
Прокси-сервер/балансировщик нагрузки перед API-сервером(-ами):
- наличие и тип (например, nginx) определяется конфигурацией кластера;
- располагается между клиентами и одним или несколькими серверами API;
- балансирует запросы при наличии нескольких серверов API.
-
Облачные балансировщики нагрузки на внешних сервисах:
- предоставляются некоторыми облачными провайдерами (например, AWS ELB, Google Cloud Load Balancer);
- создаются автоматически для сервисов Kubernetes с типом
LoadBalancer;
- как правило, поддерживают только UDP/TCP;
- наличие поддержки SCTP зависит от реализации балансировщика нагрузки облачного провайдера;
- реализация варьируется в зависимости от поставщика облачных услуг.
Пользователи Kubernetes, как правило, в своей работе сталкиваются только с прокси-серверами первых двух типов. За настройку остальных типов обычно отвечает администратор кластера.
Запросы на перенаправления
На смену функциям перенаправления (редиректам) пришли прокси-серверы. Перенаправления устарели.
7 - Равноправный доступ к API
СТАТУС ФИЧИ: Kubernetes v1.20 [beta]
Контроль за поведением API-сервера Kubernetes в условиях высокой нагрузки — ключевая задача для администраторов кластера. В kube-apiserver имеются некоторые механизмы управления (например, флаги командной строки --max-requests-inflight и --max-mutating-requests-inflight) для ограничения нагрузки на сервер. Они предотвращают наплыв входящих запросов и потенциальный отказ сервера API, но не позволяют гарантировать прохождение наиболее важных запросов в периоды высокой нагрузки.
Функция регулирования приоритета и обеспечения равноправного доступа к API (API Priority and Fairness), или РДА, — отличная альтернатива флагам. Она оптимизирует вышеупомянутые ограничения на максимальное количество запросов. РДА тщательнее классифицирует запросы и изолирует их. Также она поддерживает механизм очередей, который помогает обрабатывать запросы при краткосрочных всплесках нагрузки. Отправка запросов из очередей осуществляется на основе метода организации равноправных очередей, поэтому плохо работающий контроллер не будет мешать работе других (даже с аналогичным уровнем приоритета).
Эта функция предназначена для корректной работы со стандартными контроллерами, которые используют информеры и реагируют на неудачные API-запросы, экспоненциально увеличивая выдержку (back-off) между ними, а также клиентами, устроенными аналогичным образом.
Внимание:
Запросы, отнесенные к категории "long-running" — в первую очередь следящие, — не подпадают под действие фильтра функции равноправного доступа к API. Это также верно для флага --max-requests-inflight без включенной функции РДА.
Включение/отключение равноправного доступа к API
Управление РДА осуществляется с помощью переключателя функционала (feature gate); по умолчанию функция включена. В разделе Переключатели функционала приведено их общее описание и способы включения/отключения. В случае РДА соответствующий переключатель называется "APIPriorityAndFairness". Данная функция также включает группу API, при этом: (a) версия v1alpha1 по умолчанию отключена, (b) версии v1beta1 и v1beta2 по умолчанию включены. Чтобы отключить РДА и бета-версии групп API, добавьте следующие флаги командной строки в вызов kube-apiserver:
kube-apiserver \
--feature-gates=APIPriorityAndFairness=false \
--runtime-config=flowcontrol.apiserver.k8s.io/v1beta1=false,flowcontrol.apiserver.k8s.io/v1beta2=false \
# …и остальные флаги, как обычно
Кроме того, версию v1alpha1 группы API можно включить с помощью --runtime-config=flowcontrol.apiserver.k8s.io/v1alpha1=true.
Флаг командной строки --enable-priority-and-fairness=false отключит функцию равноправного доступа к API, даже если другие флаги ее активировали.
Основные понятия
Функция равноправного доступа к API в своей работе использует несколько базовых понятий/механизмов. Входящие запросы классифицируются по атрибутам с помощью т.н. FlowSchemas, после чего им присваиваются уровни приоритета. Уровни приоритета обеспечивают некоторую степень изоляции, обеспечивая различные пределы параллелизма, предотвращая влияние запросов с разными уровнями приоритета друг на друга. В пределах одного приоритета алгоритм равнодоступного формирования очереди предотвращает взаимное влияние запросов из разных потоков и формирует очередь запросов, снижая число неудачных запросов во время всплесков трафика при приемлемо низкой средней нагрузке.
Уровни приоритета
Без включенного равноправного доступа к API управление общим параллелизмом в API-сервере осуществляется флагами --max-requests-inflight и --max-mutating-requests-inflight для kube-apiserver. При включенном равноправном доступе к API пределы параллелизма, заданные этими флагами, суммируются, а затем сумма распределяется по настраиваемому набору уровней приоритета. Каждому входящему запросу присваивается определенный уровень приоритета, причем каждый уровень приоритета может отправлять только такое количество параллельных запросов, которое прописано в его конфигурации.
Конфигурация по умолчанию, например, предусматривает отдельные уровни приоритета для запросов на выборы лидера, запросов от встроенных контроллеров и запросов от Pod'ов. Это означает, что Pod, ведущий себя некорректно и переполняющий API-сервер запросами, не сможет помешать выборам лидера или оказать влияние на действия встроенных контроллеров.
Очереди
Каждый уровень приоритета может включать большое количество различных источников трафика. Во время перегрузки важно предотвратить негативное влияние одного потока запросов на остальные (например, в идеале один сбойный клиент, переполняющий kube-apiserver своими запросами, не должен оказывать заметного влияния на других клиентов). Для этого при обработке запросов с одинаковым уровнем приоритета используется алгоритм равнодоступной очереди. Каждый запрос приписывается к потоку, который идентифицируется по имени соответствующей FlowSchema и дифференциатору потока: пользователю-источнику запроса, пространству имен целевого ресурса или пустым значением. Система старается придать примерно равный вес запросам в разных потоках с одинаковым уровнем приоритета.
Для раздельной обработки различных инстансов контроллеры с большим их числом должны аутентифицироваться под разными именами пользователей.
Распределив запрос в некоторый поток, РДА приписывает его к очереди. Этот процесс базируется на методе, известном как shuffle sharding (тасование между шардами), который относительно эффективно изолирует потоки низкой интенсивности от потоков высокой интенсивности с помощью очередей.
Параметры алгоритма постановки в очередь можно настраивать для каждого уровня приоритетов. В результате администратор может выбирать между использованием памяти, равнодоступностью (свойством, которое обеспечивает продвижение независимых потоков, когда совокупный трафик превышает пропускную способность), толерантностью к всплескам трафика и дополнительной задержкой, вызванной постановкой в очередь.
Запросы-исключения
Некоторые запросы считаются настолько важными, что на них не распространяется ни одно из ограничений, налагаемых этой функцией. Механизм исключений не позволяет ошибочно настроенной конфигурации управления потоком полностью вывести сервер API из строя.
Ресурсы
API управления потоками включает в себя два вида ресурсов. PriorityLevelConfigurations определяет доступные классы изоляции, долю доступного бюджета параллелизма, которая выделяется для каждого класса, и позволяет выполнять тонкую настройку работы с очередями. FlowSchema используется для классификации отдельных входящих запросов, сопоставляя каждый из них с одной из конфигураций PriorityLevelConfiguration. Кроме того, существует версия v1alpha1 данной группы API, с аналогичными Kinds с теми же синтаксисом и семантикой.
PriorityLevelConfiguration
PriorityLevelConfiguration представляет отдельный класс изоляции. У каждой конфигурации PriorityLevelConfiguration имеется независимый предел на количество активных запросов и ограничения на число запросов в очереди.
Пределы параллелизма для PriorityLevelConfigurations указываются не в виде абсолютного количества запросов, а в виде "долей параллелизма" (concurrency shares). Совокупный объем ресурсов API-сервера, доступных для параллелизма, распределяется между существующими PriorityLevelConfigurations пропорционально этим долям. Администратор кластера может увеличить или уменьшить совокупный объем трафика на сервер, просто перезапустив kube-apiserver с другим значением --max-requests-inflight (или --max-mutating-requests-inflight). В результате пропускная способность каждой PriorityLevelConfigurations возрастет (или снизится) соразмерно ее доле.
Внимание:
При включенной функции Priority and Fairness суммарный предел параллелизма для сервера равен сумме --max-requests-inflight и --max-mutating-requests-inflight. При этом мутирующие и не мутирующие запросы рассматриваются вместе; чтобы обрабатывать их независимо для некоторого ресурса, создайте отдельные FlowSchemas для мутирующих и не мутирующих действий (verbs).
Поле type спецификации PriorityLevelConfiguration определяет судьбу избыточных запросов, когда их объем, отнесенный к одной PriorityLevelConfiguration, превышает ее допустимый уровень параллелизма. Тип Reject означает, что избыточный трафик будет немедленно отклонен с ошибкой HTTP 429 (Too Many Requests). Тип Queue означает, что запросы, превышающие пороговое значение, будут поставлены в очередь, при этом для балансировки прогресса между потоками запросов будут использоваться методы тасования между шардами и равноправных очередей.
Конфигурация очередей позволяет настроить алгоритм равноправных очередей для каждого уровня приоритета. Подробности об алгоритме можно узнать из предложения по улучшению; если вкратце:
-
Увеличение queues снижает количество конфликтов между различными потоками за счет повышенного использования памяти. При единице логика равнодоступной очереди отключается, но запросы все равно могут быть поставлены в очередь.
-
Увеличение длины очереди (queueLengthLimit) позволяет выдерживать большие всплески трафика без потери запросов за счет увеличения задержек и повышенного потребления памяти.
-
Изменение handSize позволяет регулировать вероятность конфликтов между различными потоками и общий параллелизм, доступный для одного потока в условиях чрезмерной нагрузки.
Примечание:
Больший handSize снижает вероятность конфликта двух отдельных потоков (и, следовательно, вероятность того, что один из них подавит другой), но повышает вероятность того, что малое число потоков загрузят API-сервер. Больший handSize также потенциально увеличивает задержку, которую может вызвать один поток с высоким трафиком. Максимальное возможное количество запросов в очереди от одного потока равно handSize * queueLengthLimit.
Ниже приведена таблица с различными конфигурациями, показывающая вероятность того, что "мышь" (поток низкой интенсивности) будет раздавлена "слонами" (потоками высокой интенсивности) в зависимости от числа "слонов" при тасовании потоков между шардами. Скрипт для расчета таблицы доступен по ссылке.
Конфигурации shuffle sharding
handSize |
Число очередей |
1 слон |
4 слона |
16 слонов |
| 12 |
32 |
4.428838398950118e-09 |
0.11431348830099144 |
0.9935089607656024 |
| 10 |
32 |
1.550093439632541e-08 |
0.0626479840223545 |
0.9753101519027554 |
| 10 |
64 |
6.601827268370426e-12 |
0.00045571320990370776 |
0.49999929150089345 |
| 9 |
64 |
3.6310049976037345e-11 |
0.00045501212304112273 |
0.4282314876454858 |
| 8 |
64 |
2.25929199850899e-10 |
0.0004886697053040446 |
0.35935114681123076 |
| 8 |
128 |
6.994461389026097e-13 |
3.4055790161620863e-06 |
0.02746173137155063 |
| 7 |
128 |
1.0579122850901972e-11 |
6.960839379258192e-06 |
0.02406157386340147 |
| 7 |
256 |
7.597695465552631e-14 |
6.728547142019406e-08 |
0.0006709661542533682 |
| 6 |
256 |
2.7134626662687968e-12 |
2.9516464018476436e-07 |
0.0008895654642000348 |
| 6 |
512 |
4.116062922897309e-14 |
4.982983350480894e-09 |
2.26025764343413e-05 |
| 6 |
1024 |
6.337324016514285e-16 |
8.09060164312957e-11 |
4.517408062903668e-07 |
FlowSchema
FlowSchema сопоставляется со входящими запросами; по результатам данного действия тем приписывается определенный уровень приоритета. Каждый входящий запрос по очереди проверяется на соответствие каждой FlowSchema, начиная с тех, у которых наименьшее численное значение matchingPrecedence (т.е., логически наивысший приоритет). Проверка ведется до первого совпадения.
Внимание:
Учитывается только первая подходящая FlowSchema для данного запроса. Если одному входящему запросу соответствует несколько FlowSchemas, он попадет в ту, у которой наивысший matchingPrecedence. Если несколько FlowSchema с одинаковым matchingPrecedence соответствуют одному запросу, предпочтение будет отдано той, у которой лексикографически меньшее имя (name). Впрочем, лучше не полагаться на это, а убедиться, что matchingPrecedence уникален для всех FlowSchema.
Схема FlowSchema подходит определенному запросу, если хотя бы одно из ее правил (rules) подходит ему. В свою очередь, правило соответствует запросу, если ему соответствует хотя бы один из его субъектов (subjects) и хотя бы одно из его правил resourceRules или nonResourceRules (в зависимости от того, является ли входящий запрос ресурсным или нересурсным URL).
Для поля name в субъектах (subjects) и полей verbs, apiGroups, resources, namespaces и nonResourceURLs в ресурсных и нересурсных правилах может быть указан универсальный символ *, который будет соответствовать всем значениям для данного поля, фактически исключая его из рассмотрения.
Параметр distinguisherMethod.type схемы FlowSchema определяет, как запросы, соответствующие этой схеме, будут разделяться на потоки. Он может быть либо ByUser (в этом случае один запрашивающий пользователь не сможет лишить других пользователей ресурсов), либо ByNamespace (в этом случае запросы на ресурсы в одном пространстве имен не смогут помешать запросам на ресурсы в других пространствах имен), либо он может быть пустым (или distinguisherMethod может быть опущен) (в этом случае все запросы, соответствующие данной FlowSchema, будут считаться частью одного потока). Правильный выбор для определенной FlowSchema зависит от ресурса и конкретной среды.
Значения по умолчанию
kube-apiserver поддерживает два вида объектов конфигурации РДА: обязательные и рекомендуемые.
Обязательные объекты конфигурации
Четыре обязательных объекта конфигурации отражают защитное поведение, встроенное в серверы. Оно реализуется независимо от этих объектов; параметры последних просто его отражают.
-
Обязательный уровень приоритета exempt используется для запросов, которые вообще не подчиняются контролю потока: они всегда будут доставляться немедленно. Обязательная FlowSchema exempt относит к этому уровню приоритета все запросы из группы system:masters. При необходимости можно задать другие FlowSchemas, которые будут наделять другие запросы данным уровнем приоритета.
-
Обязательный уровень приоритета catch-all используется в сочетании с обязательной FlowSchema catch-all, гарантируя, что каждый запрос получит какую-либо классификацию. Как правило, полагаться на эту универсальную конфигурацию не следует. Рекомендуется создать свои собственные универсальные FlowSchema и PriorityLevelConfiguration (или использовать опциональный уровень приоритета global-default, доступный по умолчанию). Поскольку предполагается, что обязательный уровень приоритета catch-all будет использоваться редко, его доля параллелизма невысока, кроме того, он не ставит запросы в очередь.
Опциональные объекты конфигурации
Опциональные объекты FlowSchemas и PriorityLevelConfigurations образуют оптимальную конфигурацию по умолчанию. При желании их можно изменить и/или создать дополнительные объекты конфигурации. Если велика вероятность высокой нагрузки на кластер, следует решить, какая конфигурация будет работать лучше всего.
Опциональная конфигурация группирует запросы по шести уровням приоритета:
-
Уровень приоритета node-high предназначен для проверки здоровья узлов.
-
Уровень приоритета system предназначен для запросов от группы system:nodes, не связанных с состоянием узлов, а именно: от kubelet'ов, которые должны иметь возможность связываться с сервером API для планирования рабочих нагрузок.
-
Уровень приоритета leader-election предназначен для запросов на выборы лидера от встроенных контроллеров (в частности, запросы на объекты типа Endpoint, ConfigMap или Lease, поступающие от пользователей system:kube-controller-manager или system:kube-scheduler и служебных учетных записей в пространстве имен kube-system). Их важно изолировать от другого трафика, поскольку сбои при выборе лидеров приводят к перезагрузкам контроллеров. Соответственно, новые контроллеры потребляют трафик, синхронизируя свои информеры.
-
Уровень приоритета workload-high предназначен для прочих запросов от встроенных контроллеров.
-
Уровень приоритета workload-low предназначен для запросов от остальных учетных записей служб, которые обычно включают все запросы от контроллеров, работающих в Pod'ах.
-
Уровень приоритета global-default обрабатывает весь остальной трафик, например, интерактивные команды kubectl, выполняемые непривилегированными пользователями.
Опциональные FlowSchemas служат для направления запросов на вышеуказанные уровни приоритета и здесь не перечисляются.
Обслуживание обязательных и опциональных объектов конфигурации
Каждый kube-apiserver самостоятельно обслуживает обязательные и опциональные объекты конфигурации, используя стратегию начальных/периодических проходов. Таким образом, в ситуации с серверами разных версий может возникнуть пробуксовка (thrashing) из-за разного представления серверов о правильном содержании этих объектов.
Каждый kube-apiserver выполняет начальный проход по обязательным и опциональным объектам конфигурации, а затем периодически (раз в минуту) обходит их.
Для обязательных объектов обслуживание заключается в проверке того, что объект существует и имеет надлежащую спецификацию (spec). Сервер не разрешает создавать или обновлять объекты со spec, которая не соответствует его защитному поведению.
Обслуживание опциональных объектов конфигурации предусматривает возможность переопределения их спецификации (spec). Кроме того, удаление носит непостоянный характер: объект будет восстановлен в процессе обслуживания. Если опциональный объект конфигурации не нужен, его не нужно удалять, но достаточно настроить spec'и так, чтобы последствия были минимальными. Обслуживание опциональных объектов также рассчитано на поддержку автоматической миграции при выходе новой версии kube-apiserver, при этом вероятны конфликты (thrashing), пока группировка серверов остается смешанной.
Обслуживание опционального объекта конфигурации предусматривает его создание — с рекомендуемой спецификацией сервера — если тот не существует. В то же время, если объект уже существует, поведение при обслуживании зависит от того, кто им управляет — kube-apiserver'ы или пользователи. В первом случае сервер гарантирует, что спецификация объекта соответствует рекомендуемой; во втором случае спецификация не анализируется.
Чтобы узнать, кто управляет объектом, необходимо найти аннотацию с ключом apf.kubernetes.io/autoupdate-spec. Если такая аннотация существует и ее значение равно true, то объект контролируется kube-apiserver'ами. Если аннотация существует и ее значение равно false, объект контролируется пользователями. Если ни одно из этих условий не выполняется, выполняется обращение к metadata.generation объекта. Если этот параметр равен 1, объект контролируется kube-apiserver'ами. В противном случае объект контролируют пользователи. Эти правила были введены в версии 1.22, и использование metadata.generation обусловлено переходом от более простого предыдущего поведения. Пользователи, желающие контролировать опциональный объект конфигурации, должны убедиться, что его аннотация apf.kubernetes.io/autoupdate-spec имеет значение false.
Обслуживание обязательного или опционального объекта конфигурации также предусматривает проверку наличия у него аннотации apf.kubernetes.io/autoupdate-spec, которая позволяет понять, контролируют ли его kube-apiserver'ы.
Обслуживание также предусматривает удаление объектов, которые не являются ни обязательными, ни опциональными, но имеют аннотацию apf.kubernetes.io/autoupdate-spec=true.
Освобождение проверок работоспособности от параллелизма
Опциональная конфигурация не предусматривает особого отношения к health check-запросам на kube-apiserver'ы от их локальных kubelet'ов. В данном случае обычно используется защищенный порт, но учетные данные не передаются. В опциональной конфигурации такие запросы относятся к FlowSchema global-default и соответствующему уровню приоритета global-default, где другой трафик может мешать их прохождению.
Чтобы освободить такие запросы от частотных ограничений, можно добавить FlowSchema, приведенную ниже.
Внимание:
Добавление данной FlowSchema позволит злоумышленникам отправлять удовлетворяющие ей health-check-запросы в любом количестве. При наличии фильтра веб-трафика или аналогичного внешнего механизма безопасности для защиты API-сервера кластера от интернет-трафика можно настроить правила для блокировки любых health-check-запросов, поступающих из-за пределов кластера.
apiVersion: flowcontrol.apiserver.k8s.io/v1beta3
kind: FlowSchema
metadata:
name: health-for-strangers
spec:
matchingPrecedence: 1000
priorityLevelConfiguration:
name: exempt
rules:
- nonResourceRules:
- nonResourceURLs:
- "/healthz"
- "/livez"
- "/readyz"
verbs:
- "*"
subjects:
- kind: Group
group:
name: system:unauthenticated
Диагностика
Каждый HTTP-ответ от сервера API с включенной функцией РДА содержит два дополнительных заголовка: X-Kubernetes-PF-FlowSchema-UID и X-Kubernetes-PF-PriorityLevel-UID. В них указываются схема потока и уровень приоритета соответственно. Имена объектов API не включаются в эти заголовки на случай, если запрашивающий пользователь не обладает правами на их просмотр, поэтому при отладке можно использовать команду типа:
kubectl get flowschemas -o custom-columns="uid:{metadata.uid},name:{metadata.name}"
kubectl get prioritylevelconfigurations -o custom-columns="uid:{metadata.uid},name:{metadata.name}"
чтобы привязать UID к именам для FlowSchemas и PriorityLevelConfigurations.
Наблюдаемость
Метрики
Примечание:
В Kubernetes до версии v1.20 лейблы flow_schema и priority_level также могли называться flowSchema и priorityLevel, соответственно. При использовании Kubernetes v1.19 и более ранних версий обратитесь к документации для соответствующей версии.
При включении функции равноправного доступа к API kube-apiserver начинает экспортировать дополнительные метрики. Их мониторинг помогает выявить негативное влияние (throttling) текущей конфигурации на важный трафик или найти неэффективные рабочие нагрузки, которые вредят здоровью системы.
-
apiserver_flowcontrol_rejected_requests_total — вектор-счетчик (кумулятивный с момента запуска сервера) запросов, которые были отклонены, с разбивкой по лейблам flow_schema (указывает на FlowSchema у запросов, попавших под соответствие), priority_level (уровень приоритета, который был присвоен этим запросам) и reason. Лейбл reason будет иметь одно из следующих значений:
queue-full — в очереди уже слишком много запросов;concurrency-limit — PriorityLevelConfiguration настроена на отклонение, а не на постановку в очередь избыточных запросов;time-out — запрос все еще находился в очереди, когда истек его лимит ожидания.
-
apiserver_flowcontrol_dispatched_requests_total — вектор-счетчик (кумулятивный с момента запуска сервера) запросов, которые начали выполняться, сгруппированный по лейблам flow_schema (указывает на FlowSchema у запросов, попавших под соответствие) и priority_level (уровень приоритета, который был присвоен этим запросам).
-
apiserver_current_inqueue_requests — вектор предыдущего максимума числа запросов в очереди, сгруппированных по лейблу request_kind, значение которого mutating или readOnly. Эти максимумы описывают наибольшее число, наблюдавшееся в последнем завершенном односекундном окне. Они дополняют более старый вектор apiserver_current_inflight_requests, который показывает максимум активно обслуживаемых запросов в последнем окне.
-
apiserver_flowcontrol_read_vs_write_request_count_samples — вектор-гистограмма наблюдений за тогда-текущим количеством запросов с разбивкой по лейблам phase (принимает значения waiting и executing) и request_kind (принимает значения mutating и readOnly). Наблюдения проводятся периодически с высокой частотой. Каждое наблюдаемое значение представляет собой число в диапазоне от 0 до 1, равное отношению числа запросов к соответствующему ограничению на их количество (ограничение длины очереди в случае ожидания и лимит параллелизма в случае выполнения).
-
apiserver_flowcontrol_read_vs_write_request_count_watermarks — вектор-гистограмма максимумов или минимумов количества запросов (число запросов, деленное на соответствующее ограничение) с разбивкой по лейблам phase (принимает значения waiting и executing) и request_kind (принимает значения mutating и readOnly); лейбл mark принимает значения high и low. Минимумы и максимумы собираются в окнах, ограниченных временем, когда наблюдение было добавлено в apiserver_flowcontrol_read_vs_write_request_count_samples. Эти экстремумы помогают определить разброс диапазона значений, наблюдавшийся в разных сэмплах.
-
apiserver_flowcontrol_current_inqueue_requests — gauge-вектор, содержащий количество стоящих в очереди (не выполняющихся) запросов в каждый момент с разбивкой по лейблам priority_level и flow_schema.
-
apiserver_flowcontrol_current_executing_requests — gauge-вектор, содержащий количество исполняемых (не ожидающих в очереди) запросов в каждый момент с разбивкой по лейблам priority_level и flow_schema.
-
apiserver_flowcontrol_request_concurrency_in_use — gauge-вектор, содержащий количество занятых мест в каждый момент с разбивкой по лейблам priority_level и flow_schema.
-
apiserver_flowcontrol_priority_level_request_count_samples — вектор-гистограмма наблюдений за текущим-на-тот-момент количеством запросов с разбивкой по лейблам phase (принимает значения waiting и executing) и priority_level. Каждая гистограмма получает наблюдения, сделанные периодически, вплоть до последней активности соответствующего рода. Наблюдения проводятся с высокой частотой. Каждое наблюдаемое значение представляет собой число в диапазоне от 0 до 1, равное отношению числа запросов к соответствующему ограничению на их количество (ограничение длины очереди в случае ожидания и лимит параллелизма в случае выполнения).
-
apiserver_flowcontrol_priority_level_request_count_watermarks — вектор-гистограмма максимумов или минимумов количества запросов с разбивкой по лейблам phase (принимает значения waiting и executing) и priority_level; лейбл mark принимает значения high и low. Минимумы и максимумы собираются в окнах, ограниченных временем, когда наблюдение было добавлено в apiserver_flowcontrol_priority_level_request_count_samples. Эти экстремумы показывают диапазон значений, наблюдавшийся в разных сэмплах.
-
apiserver_flowcontrol_priority_level_seat_count_samples — вектор-гистограмма наблюдений за использованием лимита параллелизма для уровня приоритета с разбивкой по priority_level. Использование — отношение (количество занятых мест) / (предел параллелизма). Метрика учитывает все стадии выполнения (как обычную, так и дополнительную задержку в конце записи для покрытия соответствующей работы по уведомлению) всех запросов, кроме WATCHes; для этих запросов учитывается только начальная стадия по доставке уведомлений о ранее существующих объектах. Каждая гистограмма в векторе также помечена лейблом phase: executing (количество мест для фазы ожидания не ограничено). Каждая гистограмма получает наблюдения, сделанные периодически, вплоть до последней активности соответствующего рода. Наблюдения производятся с высокой частотой.
-
apiserver_flowcontrol_priority_level_seat_count_watermarks — вектор-гистограмма минимумов и максимумов использования предела параллелизма для уровня приоритета с разбивкой по priority_leve и mark (принимает значения high и low). Каждая гистограмма в векторе также помечена лейблом phase: executing (для фазы ожидания предел на места отсутствует). Максимумы и минимумы собираются в окнах, ограниченных временем, когда наблюдение было добавлено в apiserver_flowcontrol_priority_level_seat_count_samples. Эти экстремумы помогают определить разброс диапазона значений, наблюдавшийся в разных сэмплах.
-
apiserver_flowcontrol_request_queue_length_after_enqueue — вектор-гистограмма длины очереди для очередей с разбивкой по лейблам priority_level и flow_schema как выборки по поставленным в очередь запросам. Каждый запрос при постановке в очередь вносит один сэмпл в гистограмму, сообщая о длине очереди сразу после добавления запроса. Обратите внимание, что это дает иную статистику, чем при объективном исследовании.
Примечание:
В данном случае выброс в гистограмме означает, что, скорее всего, один поток (т.е. запросы от одного пользователя или для одного пространства имен, в зависимости от конфигурации) переполняет сервер API и "срезается" (throttled). И наоборот, если гистограмма одного уровня приоритета показывает, что все очереди для этого уровня приоритета длиннее, чем для других уровней приоритета, возможно, следует увеличить долю параллелизма для этого уровня приоритета в PriorityLevelConfiguration.
-
apiserver_flowcontrol_request_concurrency_limit — gauge-вектор, содержащий вычисленный лимит параллелизма (основанный на общем лимите параллелизма сервера API и долях параллелизма PriorityLevelConfigurations), с разбивкой по лейблу priority_level.
-
apiserver_flowcontrol_request_wait_duration_seconds — вектор-гистограмма времени ожидания запросов в очереди с разбивкой по лейблам flow_schema (указывает, какая схема соответствует запросу), priority_level (указывает, к какому уровню был отнесен запрос) и execute (указывает, начал ли запрос выполняться).
Примечание:
Поскольку каждая FlowSchema всегда относит запросы к одному PriorityLevelConfiguration, можно сложить гистограммы для всех FlowSchema для одного уровня приоритета, чтобы получить эффективную гистограмму для запросов, отнесенных к этому уровню приоритета.
-
apiserver_flowcontrol_request_execution_seconds — вектор-гистограмма времени, затраченного на выполнение запросов, с разбивкой по по лейблам flow_schema (указывает, какая схема соответствует запросу) и priority_level (указывает, к какому уровню был отнесен запрос).
-
apiserver_flowcontrol_watch_count_samples — вектор-гистограмма количества активных запросов WATCH, относящихся к данной записи, с разбивкой по flow_schema и priority_level.
-
apiserver_flowcontrol_work_estimated_seats — вектор-гистограмма количества предполагаемых мест (максимум начального и конечного этапа выполнения), связанных с запросами, с разбивкой по flow_schema и priority_level.
-
apiserver_flowcontrol_request_dispatch_no_accommodation_total — вектор-счетчик количества событий, которые в принципе могли бы привести к отправке запроса, но не привели из-за отсутствия доступного параллелизма, с разбивкой по flow_schema и priority_level. Соответствующими событиями являются поступление запроса и завершение запроса.
Отладочные endpoint'ы
При включении функции равноправного доступа к API kube-apiserver предоставляет следующие дополнительные пути на своих HTTP[S]-портах.
-
/debug/api_priority_and_fairness/dump_priority_levels — список всех уровней приоритета и текущее состояние каждого из них. Получить его можно следующим образом:
kubectl get --raw /debug/api_priority_and_fairness/dump_priority_levels
Вывод выглядит примерно так:
PriorityLevelName, ActiveQueues, IsIdle, IsQuiescing, WaitingRequests, ExecutingRequests,
workload-low, 0, true, false, 0, 0,
global-default, 0, true, false, 0, 0,
exempt, <none>, <none>, <none>, <none>, <none>,
catch-all, 0, true, false, 0, 0,
system, 0, true, false, 0, 0,
leader-election, 0, true, false, 0, 0,
workload-high, 0, true, false, 0, 0,
-
/debug/api_priority_and_fairness/dump_queues — список всех очередей и их текущее состояние. Получить его можно следующим образом:
kubectl get --raw /debug/api_priority_and_fairness/dump_queues
Вывод выглядит примерно так:
PriorityLevelName, Index, PendingRequests, ExecutingRequests, VirtualStart,
workload-high, 0, 0, 0, 0.0000,
workload-high, 1, 0, 0, 0.0000,
workload-high, 2, 0, 0, 0.0000,
...
leader-election, 14, 0, 0, 0.0000,
leader-election, 15, 0, 0, 0.0000,
-
/debug/api_priority_and_fairness/dump_requests — список всех запросов, которые в настоящее время ожидают в очереди. Получить его можно следующим образом:
kubectl get --raw /debug/api_priority_and_fairness/dump_requests
Вывод выглядит примерно так:
PriorityLevelName, FlowSchemaName, QueueIndex, RequestIndexInQueue, FlowDistingsher, ArriveTime,
exempt, <none>, <none>, <none>, <none>, <none>,
system, system-nodes, 12, 0, system:node:127.0.0.1, 2020-07-23T15:26:57.179170694Z,
В дополнение к запросам, стоящим в очереди, вывод включает одну фантомную строку для каждого уровня приоритета, на которую не распространяется ограничение.
Более подробный список можно получить с помощью следующей команды:
kubectl get --raw '/debug/api_priority_and_fairness/dump_requests?includeRequestDetails=1'
Вывод выглядит примерно так:
PriorityLevelName, FlowSchemaName, QueueIndex, RequestIndexInQueue, FlowDistingsher, ArriveTime, UserName, Verb, APIPath, Namespace, Name, APIVersion, Resource, SubResource,
system, system-nodes, 12, 0, system:node:127.0.0.1, 2020-07-23T15:31:03.583823404Z, system:node:127.0.0.1, create, /api/v1/namespaces/scaletest/configmaps,
system, system-nodes, 12, 1, system:node:127.0.0.1, 2020-07-23T15:31:03.594555947Z, system:node:127.0.0.1, create, /api/v1/namespaces/scaletest/configmaps,
Что дальше
Для получения подробной информации о функции равноправного доступа к API см. предложение по улучшению (KEP). Предложения и запросы функционала принимаются через SIG API Machinery или в специализированном канале Slack.
8 - Установка дополнений
Примечание: Этот раздел ссылается на сторонние проекты, реализующие функциональность, которая требуется Kubernetes. Авторы Kubernetes не несут ответственность за проекты, представленные здесь в алфавитном порядке. Чтобы добавить проект к этому списку, ознакомьтесь с
руководством по контенту перед публикацией изменений.
Подробнее.
Надстройки расширяют функциональность Kubernetes.
На этой странице перечислены некоторые из доступных надстроек и ссылки на соответствующие инструкции по установке.
Сеть и сетевая политика
- ACI обеспечивает интегрированную сеть контейнеров и сетевую безопасность с помощью Cisco ACI.
- Antrea работает на уровне 3, обеспечивая сетевые службы и службы безопасности для Kubernetes, используя Open vSwitch в качестве уровня сетевых данных.
- Calico Calico поддерживает гибкий набор сетевых опций, поэтому вы можете выбрать наиболее эффективный вариант для вашей ситуации, включая сети без оверлея и оверлейные сети, с или без BGP. Calico использует тот же механизм для обеспечения соблюдения сетевой политики для хостов, модулей и (при использовании Istio и Envoy) приложений на уровне сервисной сети (mesh layer).
- Canal объединяет Flannel и Calico, обеспечивая сеть и сетевую политику.
- Cilium - это плагин сети L3 и сетевой политики, который может прозрачно применять политики HTTP/API/L7. Поддерживаются как режим маршрутизации, так и режим наложения/инкапсуляции, и он может работать поверх других подключаемых модулей CNI.
- CNI-Genie позволяет Kubernetes легко подключаться к выбору плагинов CNI, таких как Calico, Canal, Flannel, Romana или Weave.
- Contrail, основан на Tungsten Fabric, представляет собой платформу для виртуализации мультиоблачных сетей с открытым исходным кодом и управления политиками. Contrail и Tungsten Fabric интегрированы с системами оркестрации, такими как Kubernetes, OpenShift, OpenStack и Mesos, и обеспечивают режимы изоляции для виртуальных машин, контейнеров/подов и рабочих нагрузок без операционной системы.
- Flannel - это поставщик оверлейной сети, который можно использовать с Kubernetes.
- Knitter - это плагин для поддержки нескольких сетевых интерфейсов Kubernetes подов.
- Multus - это плагин Multi для работы с несколькими сетями в Kubernetes, который поддерживает большинство самых популярных CNI (например: Calico, Cilium, Contiv, Flannel), в дополнение к рабочим нагрузкам основанных на SRIOV, DPDK, OVS-DPDK и VPP в Kubernetes.
- OVN-Kubernetes - это сетевой провайдер для Kubernetes основанный на OVN (Open Virtual Network), реализация виртуальной сети, появившийся в результате проекта Open vSwitch (OVS). OVN-Kubernetes обеспечивает сетевую реализацию на основе наложения для Kubernetes, включая реализацию балансировки нагрузки и сетевой политики на основе OVS.
- OVN4NFV-K8S-Plugin - это подключаемый модуль контроллера CNI на основе OVN для обеспечения облачной цепочки сервисных функций (SFC), несколько наложенных сетей OVN, динамического создания подсети, динамического создания виртуальных сетей, сети поставщика VLAN, сети прямого поставщика и подключаемого к другим Multi Сетевые плагины, идеально подходящие для облачных рабочих нагрузок на периферии в сети с несколькими кластерами.
- NSX-T плагин для контейнера (NCP) обеспечивающий интеграцию между VMware NSX-T и контейнерами оркестраторов, таких как Kubernetes, а так же интеграцию между NSX-T и контейнеров на основе платформы CaaS/PaaS, таких как Pivotal Container Service (PKS) и OpenShift.
- Nuage - эта платформа SDN, которая обеспечивает сетевое взаимодействие на основе политик между Kubernetes подами и не Kubernetes окружением, с отображением и мониторингом безопасности.
- Romana - это сетевое решение уровня 3 для сетей подов, которое также поддерживает NetworkPolicy API. Подробности установки Kubeadm доступны здесь.
- Weave Net предоставляет сеть и обеспечивает сетевую политику, будет работать на обеих сторонах сетевого раздела и не требует внешней базы данных.
Обнаружение служб
- CoreDNS - это гибкий, расширяемый DNS-сервер, который может быть установлен в качестве внутрикластерного DNS для подов.
Визуализация и контроль
- Dashboard - это веб-интерфейс панели инструментов для Kubernetes.
- Weave Scope - это инструмент для графической визуализации ваших контейнеров, подов, сервисов и т.д. Используйте его вместе с учетной записью Weave Cloud или разместите пользовательский интерфейс самостоятельно.
Инфраструктура
- KubeVirt - это дополнение для запуска виртуальных машин в Kubernetes. Обычно работает на bare-metal кластерах.
Legacy Add-ons
В устаревшем каталоге cluster/addons задокументировано несколько других дополнений.
Ссылки на те, в хорошем состоянии, должны быть здесь. Пул реквесты приветствуются!