Концепции
Раздел "Концепции" поможет вам узнать о частях системы Kubernetes и об абстракциях, которые Kubernetes использует для представления вашего кластера, и помогает вам глубже понять, как работает Kubernetes.
Краткий обзор
Чтобы работать с Kubernetes, вы используете объекты API Kubernetes для описания желаемого состояния вашего кластера: какие приложения или другие рабочие нагрузки вы хотите запустить, какие образы контейнеров они используют, количество реплик, какие сетевые и дисковые ресурсы вы хотите использовать и сделать доступными и многое другое. Вы устанавливаете желаемое состояние, создавая объекты с помощью API Kubernetes, обычно через интерфейс командной строки kubectl. Вы также можете напрямую использовать API Kubernetes для взаимодействия с кластером и установки или изменения желаемого состояния.
После того, как вы установили желаемое состояние, Управляющий слой Kubernetes (control plane) заставляет текущее состояние кластера соответствовать желаемому состоянию с помощью генератора событий жизненного цикла подов (Pod Lifecycle Event Generator, PLEG). Для этого Kubernetes автоматически выполняет множество задач, таких как запуск или перезапуск контейнеров, масштабирование количества реплик данного приложения и многое другое. Управляющий слой Kubernetes состоит из набора процессов, запущенных в вашем кластере:
- Мастер Kubernetes — это коллекция из трех процессов, которые выполняются на одном узле в вашем кластере, который обозначен как главный узел. Это процессы: kube-apiserver, kube-controller-manager и kube-scheduler.
- Каждый отдельный неосновной узел в вашем кластере выполняет два процесса:
- kubelet, который взаимодействует с мастером Kubernetes.
- kube-proxy, сетевой прокси, который обрабатывает сетевые сервисы Kubernetes на каждом узле.
Объекты Kubernetes
Kubernetes содержит ряд абстракций, которые представляют состояние вашей системы: развернутые контейнеризованные приложения и рабочие нагрузки, связанные с ними сетевые и дисковые ресурсы и другую информацию о том, что делает ваш кластер. Эти абстракции представлены объектами в API Kubernetes. См. Понимание объектов Kubernetes для получения более подробной информации.
Основные объекты Kubernetes включают в себя:
Kubernetes также содержит абстракции более высокого уровня, которые опираются на Контроллеры для создания базовых объектов и предоставляют дополнительные функциональные и удобные функции. Они включают:
Управляющий слой Kubernetes
Различные части управляющего слоя Kubernetes (control plane), такие как мастер Kubernetes и процессы kubelet, определяют, как Kubernetes взаимодействует с кластером. Управляющий слой поддерживает запись всех объектов Kubernetes в системе и запускает непрерывные циклы управления для обработки состояния этих объектов. В любое время циклы управления управляющего слоя будут реагировать на изменения в кластере и работать, чтобы фактическое состояние всех объектов в системе соответствовало желаемому состоянию, которое вы указали.
Например, когда вы используете API Kubernetes для создания развертывания, вы предоставляете новое желаемое состояние для системы. Управляющий слой Kubernetes записывает создание этого объекта и выполняет ваши инструкции, запуская необходимые приложения и планируя их на узлы кластера, чтобы фактическое состояние кластера соответствовало желаемому состоянию.
Мастер Kubernetes
Мастер Kubernetes отвечает за поддержание желаемого состояния для вашего кластера. Когда вы взаимодействуете с Kubernetes, например, используя интерфейс командной строки kubectl, вы работаете с мастером Kubernetes вашего кластера.
Под "мастером" понимается совокупность процессов, которые управляют состоянием кластера. Обычно все эти процессы выполняются на одном узле кластера, и поэтому этот узел называется главным (master). Мастер также может быть реплицирован для доступности и резервирования.
Узлы Kubernetes
Узлы в кластере - это машины (виртуальные машины, физические серверы и т.д.), на которых работают ваши приложения и облачные рабочие процессы. Мастер Kubernetes контролирует каждый узел; вы редко будете взаимодействовать с узлами напрямую.
Что дальше
Если вы хотите описать концепт, обратитесь к странице
Использование шаблонов страниц
для получения информации о типе страницы и шаблоне концепции.
1 - Обзор
1.1 - Что такое Kubernetes
Эта страница посвящена краткому обзору Kubernetes.
Kubernetes — это портативная расширяемая платформа с открытым исходным кодом для управления контейнеризованными рабочими нагрузками и сервисами, которая облегчает как декларативную настройку, так и автоматизацию. У платформы есть большая, быстро растущая экосистема. Сервисы, поддержка и инструменты Kubernetes широко доступны.
Название Kubernetes происходит от греческого, что означает рулевой или штурман. Google открыл исходный код Kubernetes в 2014 году. Kubernetes основывается на десятилетнем опыте работы Google с масштабными рабочими нагрузками, в сочетании с лучшими в своем классе идеями и практиками сообщества.
История
Давайте вернемся назад и посмотрим, почему Kubernetes так полезен.

Традиционная эра развертывания:
Ранее организации запускали приложения на физических серверах. Не было никакого способа определить границы ресурсов для приложений на физическом сервере, и это вызвало проблемы с распределением ресурсов. Например, если несколько приложений выполняются на физическом сервере, могут быть случаи, когда одно приложение будет занимать большую часть ресурсов, и в результате чего другие приложения будут работать хуже. Решением этого было запустить каждое приложение на другом физическом сервере. Но это не масштабировалось, поскольку ресурсы использовались не полностью, из-за чего организациям было накладно поддерживать множество физических серверов.
Эра виртуального развертывания: В качестве решения была представлена виртуализация. Она позволила запускать несколько виртуальных машин (ВМ) на одном физическом сервере. Виртуализация изолирует приложения между виртуальными машинами и обеспечивает определенный уровень безопасности, поскольку информация одного приложения не может быть свободно доступна другому приложению.
Виртуализация позволяет лучше использовать ресурсы на физическом сервере и обеспечивает лучшую масштабируемость, поскольку приложение можно легко добавить или обновить, кроме этого снижаются затраты на оборудование и многое другое. С помощью виртуализации можно превратить набор физических ресурсов в кластер одноразовых виртуальных машин.
Каждая виртуальная машина представляет собой полноценную машину, на которой выполняются все компоненты, включая собственную операционную систему, поверх виртуализированного оборудования.
Эра контейнеров: Контейнеры похожи на виртуальные машины, но у них есть свойства изоляции для совместного использования операционной системы (ОС) между приложениями. Поэтому контейнеры считаются легкими. Подобно виртуальной машине, контейнер имеет свою собственную файловую систему, процессор, память, пространство процесса и многое другое. Поскольку они не связаны с базовой инфраструктурой, они переносимы между облаками и дистрибутивами ОС.
Контейнеры стали популярными из-за таких дополнительных преимуществ как:
- Гибкое создание и развертывание приложений: простота и эффективность создания образа контейнера по сравнению с использованием образа виртуальной машины.
- Непрерывная разработка, интеграция и развертывание: обеспечивает надежную и частую сборку и развертывание образа контейнера с быстрым и простым откатом (благодаря неизменности образа).
- Разделение задач между Dev и Ops: создавайте образы контейнеров приложений во время сборки/релиза, а не во время развертывания, тем самым отделяя приложения от инфраструктуры.
- Наблюдаемость охватывает не только информацию и метрики на уровне ОС, но также информацию о работоспособности приложений и другие сигналы.
- Идентичная окружающая среда при разработке, тестировании и релизе: на ноутбуке работает так же, как и в облаке.
- Переносимость облачных и операционных систем: работает на Ubuntu, RHEL, CoreOS, on-prem, Google Kubernetes Engine и в любом другом месте.
- Управление, ориентированное на приложения: повышает уровень абстракции от запуска ОС на виртуальном оборудовании до запуска приложения в ОС с использованием логических ресурсов.
- Слабосвязанные, распределенные, гибкие, выделенные микросервисы: вместо монолитного стека на одной большой выделенной машине, приложения разбиты на более мелкие независимые части, которые можно динамически развертывать и управлять.
- Изоляция ресурсов: предсказуемая производительность приложения.
- Грамотное использование ресурсов: высокая эффективность и компактность.
Зачем вам Kubernetes и что он может сделать?
Контейнеры — отличный способ связать и запустить ваши приложения. В производственной среде необходимо управлять контейнерами, которые запускают приложения, и гарантировать отсутствие простоев. Например, если контейнер выходит из строя, необходимо запустить другой контейнер. Не было бы проще, если бы такое поведение обрабатывалось системой?
Вот тут Kubernetes приходит на помощь! Kubernetes дает вам фреймворк для гибкой работы распределенных систем. Он занимается масштабированием и обработкой ошибок в приложении, предоставляет шаблоны развертывания и многое другое. Например, Kubernetes может легко управлять канареечным развертыванием вашей системы.
Kubernetes предоставляет вам:
- Мониторинг сервисов и распределение нагрузки
Kubernetes может обнаружить контейнер, используя имя DNS или собственный IP-адрес. Если трафик в контейнере высокий, Kubernetes может сбалансировать нагрузку и распределить сетевой трафик, чтобы развертывание было стабильным.
- Оркестрация хранилища
Kubernetes позволяет вам автоматически смонтировать систему хранения по вашему выбору, такую как локальное хранилище, провайдеры общедоступного облака и многое другое.
- Автоматическое развертывание и откаты
Используя Kubernetes можно описать желаемое состояние развернутых контейнеров и изменить фактическое состояние на желаемое. Например, вы можете автоматизировать Kubernetes на создание новых контейнеров для развертывания, удаления существующих контейнеров и распределения всех их ресурсов в новый контейнер.
- Автоматическое распределение нагрузки
Вы предоставляете Kubernetes кластер узлов, который он может использовать для запуска контейнерных задач. Вы указываете Kubernetes, сколько ЦП и памяти (ОЗУ) требуется каждому контейнеру. Kubernetes может разместить контейнеры на ваших узлах так, чтобы наиболее эффективно использовать ресурсы.
- Самоконтроль
Kubernetes перезапускает отказавшие контейнеры, заменяет и завершает работу контейнеров, которые не проходят определенную пользователем проверку работоспособности, и не показывает их клиентам, пока они не будут готовы к обслуживанию.
- Управление конфиденциальной информацией и конфигурацией
Kubernetes может хранить и управлять конфиденциальной информацией, такой как пароли, OAuth-токены и ключи SSH. Вы можете развертывать и обновлять конфиденциальную информацию и конфигурацию приложения без изменений образов контейнеров и не раскрывая конфиденциальную информацию в конфигурации стека.
Чем Kubernetes не является
Kubernetes ― это не традиционная комплексная система PaaS (платформа как услуга). Поскольку Kubernetes работает на уровне контейнеров, а не на уровне оборудования, у него имеется определенные общеприменимые возможности, характерные для PaaS, такие как развертывание, масштабирование, балансировка нагрузки, ведение журналов и мониторинг. Тем не менее, Kubernetes это не монолитное решение, поэтому указанные возможности по умолчанию являются дополнительными и подключаемыми. У Kubernetes есть компоненты для создания платформы разработчика, но он сохраняет право выбора за пользователем и гибкость там, где это важно.
Kubernetes:
- Не ограничивает типы поддерживаемых приложений. Kubernetes стремится поддерживать широкий спектр рабочих нагрузок, включая те, у которых есть или отсутствует состояние, а также связанные с обработкой данных. Если приложение может работать в контейнере, оно должно отлично работать и в Kubernetes.
- Не развертывает исходный код и не собирает приложение. Рабочие процессы непрерывной интеграции, доставки и развертывания (CI/CD) определяются культурой и предпочтениями организации, а также техническими требованиями.
- Не предоставляет сервисы для приложения, такие как промежуточное программное обеспечение (например, очереди сообщений), платформы обработки данных (например, Spark), базы данных (например, MySQL), кеши или кластерные системы хранения (например, Ceph), как встроенные сервисы. Такие компоненты могут работать в Kubernetes и/или могут быть доступны для приложений, работающих в Kubernetes, через переносные механизмы, такие как Open Service Broker.
- Не включает решения для ведения журнала, мониторинга или оповещения. Он обеспечивает некоторые интеграции в качестве доказательства концепции и механизмы для сбора и экспорта метрик.
- Не указывает и не требует настройки языка/системы (например, Jsonnet). Он предоставляет декларативный API, который может быть нацелен на произвольные формы декларативных спецификаций.
- Не предоставляет и не принимает никаких комплексных систем конфигурации, технического обслуживания, управления или самовосстановления.
- Кроме того, Kubernetes — это не просто система оркестрации. Фактически, Kubernetes устраняет необходимость в этом. Техническое определение оркестрации — это выполнение определенного рабочего процесса: сначала сделай A, затем B, затем C. Напротив, Kubernetes содержит набор независимых, компонуемых процессов управления, которые непрерывно переводит текущее состояние к предполагаемому состоянию. Неважно, как добраться от А до С. Не требуется также централизованный контроль. Это делает систему более простой в использовании, более мощной, надежной, устойчивой и расширяемой.
Что дальше
1.2 - Компоненты Kubernetes
При развёртывании Kubernetes вы имеете дело с кластером.
Кластер Kubernetes cluster состоит из набор машин, так называемые узлы, которые запускают контейнеризированные приложения. Кластер имеет как минимум один рабочий узел.
В рабочих узлах размещены поды, являющиеся компонентами приложения. Управляющий слой (control plane) управляет рабочими узлами и подами в кластере. В промышленных средах управляющий слой обычно запускается на нескольких компьютерах, а кластер, как правило, развёртывается на нескольких узлах, гарантируя отказоустойчивость и высокую надёжность.
На этой странице в общих чертах описывается различные компоненты, необходимые для работы кластера Kubernetes.
Ниже показана диаграмма кластера Kubernetes со всеми связанными компонентами.
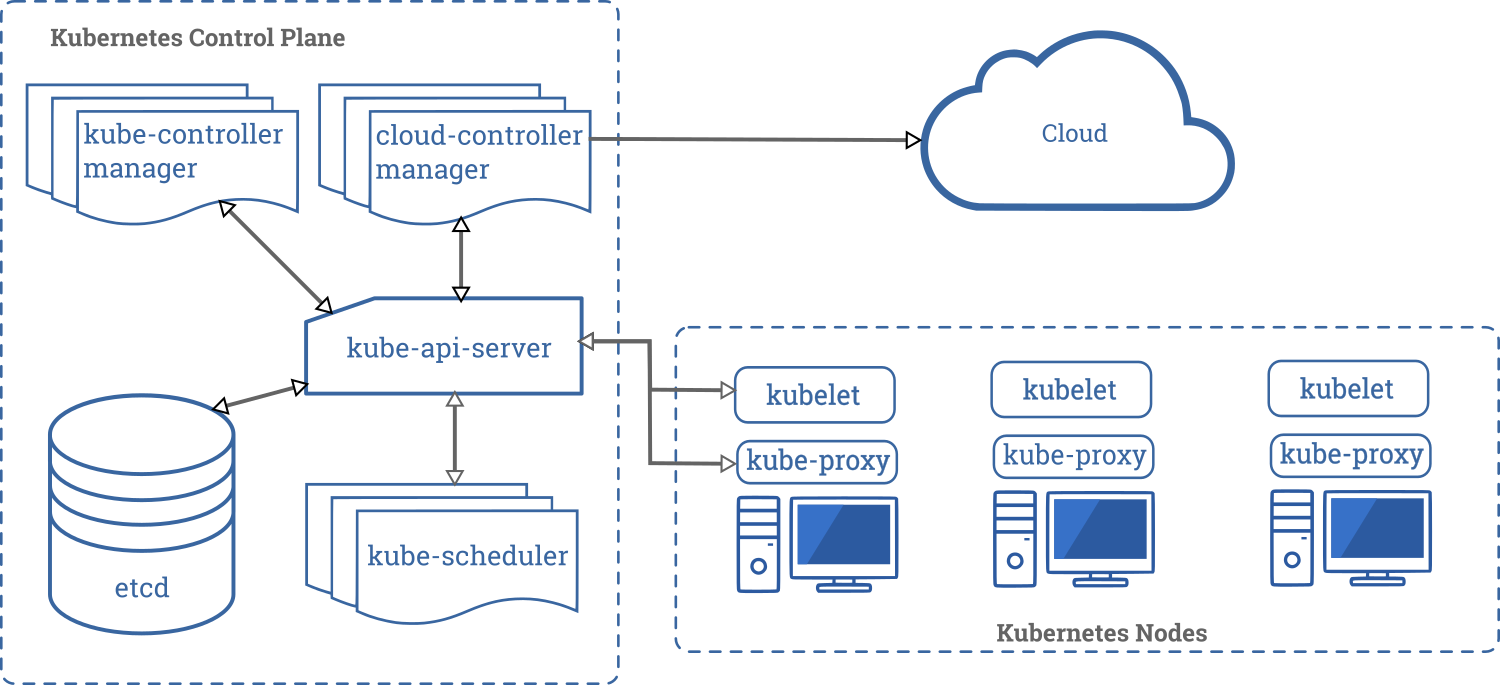
Компоненты управляющего слоя
Компоненты управляющего слоя (control plane) отвечают за основные операции кластера (например, планирование), а также обрабатывают события кластера (например, запускают новый под, когда поле replicas развертывания не соответствует требуемому количеству реплик).
Компоненты управляющего слоя могут быть запущены на любой машине в кластере. Однако для простоты сценарии настройки обычно запускают все компоненты управляющего слоя на одном компьютере и в то же время не позволяют запускать пользовательские контейнеры на этом компьютере. Смотрите страницу Создание высоконадёжных кластеров для примера настройки нескольких ведущих виртуальных машин.
kube-apiserver
Сервер API — компонент Kubernetes
панели управления, который представляет API Kubernetes.
API-сервер — это клиентская часть панели управления Kubernetes
Основной реализацией API-сервера Kubernetes является kube-apiserver.
kube-apiserver предназначен для горизонтального масштабирования, то есть развёртывание на несколько экземпляров.
Вы можете запустить несколько экземпляров kube-apiserver и сбалансировать трафик между этими экземплярами.
etcd
Распределённое и высоконадёжное хранилище данных в формате "ключ-значение", которое используется как основное хранилище всех данных кластера в Kubernetes.
Если ваш кластер Kubernetes использует etcd в качестве основного хранилища, убедитесь, что у вас настроено резервное копирование данных.
Вы можете найти подробную информацию о etcd в официальной документации.
kube-scheduler
Компонент плоскости управления, который отслеживает созданные поды без привязанного узла и выбирает узел, на котором они должны работать.
При планировании развёртывания подов на узлах учитываются множество факторов, включая требования к ресурсам, ограничения, связанные с аппаратными/программными политиками, принадлежности (affinity) и непринадлежности (anti-affinity) узлов/подов, местонахождения данных, предельных сроков.
kube-controller-manager
Компонент Control Plane запускает процессы контроллера.
Вполне логично, что каждый контроллер в свою очередь представляет собой отдельный процесс, и для упрощения все такие процессы скомпилированы в один двоичный файл и выполняются в одном процессе.
Эти контроллеры включают:
- Контроллер узла (Node Controller): уведомляет и реагирует на сбои узла.
- Контроллер репликации (Replication Controller): поддерживает правильное количество подов для каждого объекта контроллера репликации в системе.
- Контроллер конечных точек (Endpoints Controller): заполняет объект конечных точек (Endpoints), то есть связывает сервисы (Services) и поды (Pods).
- Контроллеры учетных записей и токенов (Account & Token Controllers): создают стандартные учетные записи и токены доступа API для новых пространств имен.
cloud-controller-manager
cloud-controller-manager запускает контроллеры, которые взаимодействуют с основными облачными провайдерами. Двоичный файл cloud-controller-manager — это альфа-функциональность, появившиеся в Kubernetes 1.6.
cloud-controller-manager запускает только циклы контроллера, относящиеся к облачному провайдеру. Вам нужно отключить эти циклы контроллера в kube-controller-manager. Вы можете отключить циклы контроллера, установив флаг --cloud-provider со значением external при запуске kube-controller-manager.
С помощью cloud-controller-manager код как облачных провайдеров, так и самого Kubernetes может разрабатываться независимо друг от друга. В предыдущих версиях код ядра Kubernetes зависел от кода, предназначенного для функциональности облачных провайдеров. В будущих выпусках код, специфичный для облачных провайдеров, должен поддерживаться самим облачным провайдером и компоноваться с cloud-controller-manager во время запуска Kubernetes.
Следующие контроллеры зависят от облачных провайдеров:
- Контроллер узла (Node Controller): проверяет облачный провайдер, чтобы определить, был ли удален узел в облаке после того, как он перестал работать
- Контроллер маршрутов (Route Controller): настраивает маршруты в основной инфраструктуре облака
- Контроллер сервисов (Service Controller): создаёт, обновляет и удаляет балансировщики нагрузки облачного провайдера.
- Контроллер тома (Volume Controller): создаёт, присоединяет и монтирует тома, а также взаимодействует с облачным провайдером для оркестрации томов.
Компоненты узла
Компоненты узла работают на каждом узле, поддерживая работу подов и среды выполнения Kubernetes.
kubelet
Агент, работающий на каждом узле в кластере. Он следит за тем, чтобы контейнеры были запущены в поде.
Утилита kubelet принимает набор PodSpecs, и гарантирует работоспособность и исправность определённых в них контейнеров. Агент kubelet не отвечает за контейнеры, не созданные Kubernetes.
kube-proxy
kube-proxy — сетевой прокси, работающий на каждом узле в кластере, и реализующий часть концепции сервис.
kube-proxy конфигурирует правила сети на узлах. При помощи них разрешаются сетевые подключения к вашими подам изнутри и снаружи кластера.
kube-proxy использует уровень фильтрации пакетов в операционной системы, если он доступен. В противном случае, kube-proxy сам обрабатывает передачу сетевого трафика.
Среда выполнения контейнера
Иcполняемая среда контейнера — это программа, предназначенная для запуска контейнера в Kubernetes.
Kubernetes поддерживает различные среды для запуска контейнеров: Docker,
containerd, CRI-O,
и любые реализации Kubernetes CRI (Container Runtime
Interface).
Дополнения
Дополнения используют ресурсы Kubernetes (DaemonSet, Deployment и т.д.) для расширения функциональности кластера. Поскольку дополнения охватывают весь кластер, ресурсы относятся к пространству имен kube-system.
Некоторые из дополнений описаны ниже; более подробный список доступных расширений вы можете найти на странице Дополнения.
DNS
Хотя прочие дополнения не являются строго обязательными, однако при этом у всех Kubernetes-кластеров должен быть кластерный DNS, так как многие примеры предполагают его наличие.
Кластерный DNS — это DNS-сервер наряду с другими DNS-серверами в вашем окружении, который обновляет DNS-записи для сервисов Kubernetes.
Контейнеры, запущенные посредством Kubernetes, автоматически включают этот DNS-сервер в свои DNS.
Веб-интерфейс (Dashboard)
Dashboard — это универсальный веб-интерфейс для кластеров Kubernetes. С помощью этой панели, пользователи могут управлять и устранять неполадки кластера и приложений, работающих в кластере.
Мониторинг ресурсов контейнера
Мониторинг ресурсов контейнера записывает общие метрики о контейнерах в виде временных рядов в центральной базе данных и предлагает пользовательский интерфейс для просмотра этих данных.
Логирование кластера
Механизм логирования кластера отвечает за сохранение логов контейнера в централизованном хранилище логов с возможностью их поиска/просмотра.
Что дальше
1.3 - API Kubernetes
Общие соглашения API описаны на странице соглашений API.
Конечные точки API, типы ресурсов и примеры описаны в справочнике API.
Удаленный доступ к API обсуждается в Controlling API Access doc.
API Kubernetes также служит основой декларативной схемы конфигурации системы. С помощью инструмента командной строки kubectl можно создавать, обновлять, удалять и получать API-объекты.
Kubernetes также сохраняет сериализованное состояние (в настоящее время в хранилище etcd) каждого API-ресурса.
Kubernetes как таковой состоит из множества компонентов, которые взаимодействуют друг с другом через собственные API.
Изменения в API
Исходя из нашего опыта, любая успешная система должна улучшаться и изменяться по мере появления новых сценариев использования или изменения существующих. Поэтому мы надеемся, что и API Kubernetes будет постоянно меняться и расширяться. Однако в течение продолжительного периода времени мы будем поддерживать хорошую обратную совместимость с существующими клиентами. В целом, новые ресурсы API и поля ресурсов будут добавляться часто. Удаление ресурсов или полей регулируются соответствующим процессом.
Определение совместимого изменения и методы изменения API подробно описаны в документе об изменениях API.
Определения OpenAPI и Swagger
Все детали API документируется с использованием OpenAPI.
Начиная с Kubernetes 1.10, API-сервер Kubernetes основывается на спецификации OpenAPI через конечную точку /openapi/v2.
Нужный формат устанавливается через HTTP-заголовки:
| Заголовок |
Возможные значения |
| Accept |
application/json, application/com.github.proto-openapi.spec.v2@v1.0+protobuf (по умолчанию заголовок Content-Type установлен в application/json с */*, допустимо также пропускать этот заголовок) |
| Accept-Encoding |
gzip (можно не передавать этот заголовок) |
До версии 1.14 конечные точки с форматом (/swagger.json, /swagger-2.0.0.json, /swagger-2.0.0.pb-v1, /swagger-2.0.0.pb-v1.gz) предоставляли спецификацию OpenAPI в разных форматах. Эти конечные точки были объявлены устаревшими и удалены в Kubernetes 1.14.
Примеры получения спецификации OpenAPI:
В Kubernetes реализован альтернативный формат сериализации API, основанный на Protobuf, который в первую очередь предназначен для взаимодействия внутри кластера. Описание этого формата можно найти в проектом решении, а IDL-файлы по каждой схемы — в пакетах Go, определяющих API-объекты.
До версии 1.14 apiserver Kubernetes также представлял API, который можно использовать для получения спецификации Swagger v1.2 для API Kubernetes по пути /swaggerapi. Эта конечная точка устарела и была удалена в Kubernetes 1.14
Версионирование API
Чтобы упростить удаления полей или изменение ресурсов, Kubernetes поддерживает несколько версий API, каждая из которых доступна по собственному пути, например, /api/v1 или /apis/extensions/v1beta1.
Мы выбрали версионирование API, а не конкретных ресурсов или полей, чтобы API отражал четкое и согласованное представление о системных ресурсах и их поведении, а также, чтобы разграничивать API, которые уже не поддерживаются и/или находятся в экспериментальной стадии. Схемы сериализации JSON и Protobuf следуют одним и тем же правилам по внесению изменений в схему, поэтому описание ниже охватывают оба эти формата.
Обратите внимание, что версионирование API и программное обеспечение косвенно связаны друг с другом. Предложение по версионированию API и новых выпусков описывает, как связаны между собой версии API с версиями программного обеспечения.
Разные версии API характеризуются разными уровнями стабильности и поддержки. Критерии каждого уровня более подробно описаны в документации изменений API. Ниже приводится краткое изложение:
- Альфа-версии:
- Названия версий включают надпись
alpha (например, v1alpha1).
- Могут содержать баги. Включение такой функциональности может привести к ошибкам. По умолчанию она отключена.
- Поддержка функциональности может быть прекращена в любое время без какого-либо оповещения об этом.
- API может быть несовместим с более поздними версиями без упоминания об этом.
- Рекомендуется для использования только в тестировочных кластерах с коротким жизненным циклом из-за высокого риска наличия багов и отсутствия долгосрочной поддержки.
- Бета-версии:
- Названия версий включают надпись
beta (например, v2beta3).
- Код хорошо протестирован. Активация этой функциональности — безопасно. Поэтому она включена по умолчанию.
- Поддержка функциональности в целом не будет прекращена, хотя кое-что может измениться.
- Схема и/или семантика объектов может стать несовместимой с более поздними бета-версиями или стабильными выпусками. Когда это случится, мы даем инструкции по миграции на следующую версию. Это обновление может включать удаление, редактирование и повторного создание API-объектов. Этот процесс может потребовать тщательного анализа. Кроме этого, это может привести к простою приложений, которые используют данную функциональность.
- Рекомендуется только для неосновного производственного использования из-за риска возникновения возможных несовместимых изменений с будущими версиями. Если у вас есть несколько кластеров, которые возможно обновить независимо, вы можете снять это ограничение.
- Пожалуйста, попробуйте в действии бета-версии функциональности и поделитесь своими впечатлениями! После того как функциональность выйдет из бета-версии, нам может быть нецелесообразно что-то дальше изменять.
- Стабильные версии:
- Имя версии
vX, где vX — целое число.
- Стабильные версии функциональностей появятся в новых версиях.
API-группы
Чтобы упростить расширение API Kubernetes, реализованы группы API.
Группа API указывается в пути REST и в поле apiVersion сериализованного объекта.
В настоящее время используется несколько API-групп:
-
Группа core, которая часто упоминается как устаревшая (legacy group), доступна по пути /api/v1 и использует apiVersion: v1.
-
Именованные группы находятся в пути REST /apis/$GROUP_NAME/$VERSION и используют apiVersion: $GROUP_NAME/$VERSION (например, apiVersion: batch/v1). Полный список поддерживаемых групп API можно увидеть в справочнике API Kubernetes.
Есть два поддерживаемых пути к расширению API с помощью пользовательских ресурсов:
- CustomResourceDefinition для пользователей, которым нужен очень простой CRUD.
- Пользователи, которым нужна полная семантика API Kubernetes, могут реализовать собственный apiserver и использовать агрегатор для эффективной интеграции для клиентов.
Включение или отключение групп API
Некоторые ресурсы и группы API включены по умолчанию. Их можно включить или отключить, установив --runtime-config для apiserver. Флаг --runtime-config принимает значения через запятую. Например, чтобы отключить batch/v1, используйте --runtime-config=batch/v1=false, а чтобы включить batch/v2alpha1, используйте флаг --runtime-config=batch/v2alpha1.
Флаг набор пар ключ-значение, указанных через запятую, который описывает конфигурацию во время выполнения сервера.
Примечание:
Включение или отключение групп или ресурсов требует перезапуска apiserver и controller-manager для применения изменений --runtime-config.
Включение определённых ресурсов в группу extensions/v1beta1
DaemonSets, Deployments, StatefulSet, NetworkPolicies, PodSecurityPolicies и ReplicaSets в API-группе extensions/v1beta1 по умолчанию отключены.
Например: чтобы включить deployments и daemonsets, используйте флаг --runtime-config=extensions/v1beta1/deployments=true,extensions/v1beta1/daemonsets=true.
Примечание:
Включение/отключение отдельных ресурсов поддерживается только в API-группе extensions/v1beta1 по историческим причинам.
1.4 - Работа с объектами Kubernetes
1.4.1 - Изучение объектов Kubernetes
На этой странице объясняется, как объекты Kubernetes представлены в API Kubernetes, и как их можно определить в формате .yaml.
Изучение объектов Kubernetes
Объекты Kubernetes — сущности, которые хранятся в Kubernetes. Kubernetes использует их для представления состояния кластера. В частности, они описывают следующую информацию:
- Какие контейнеризированные приложения запущены (и на каких узлах).
- Доступные ресурсы для этих приложений.
- Стратегии управления приложения, которые относятся, например, к перезапуску, обновлению или отказоустойчивости.
После создания объекта Kubernetes будет следить за существованием объекта. Создавая объект, вы таким образом указываете системе Kubernetes, какой должна быть рабочая нагрузка кластера; это требуемое состояние кластера.
Для работы с объектами Kubernetes – будь то создание, изменение или удаление — нужно использовать API Kubernetes. Например, при использовании CLI-инструмента kubectl, он обращается к API Kubernetes. С помощью одной из клиентской библиотеки вы также можете использовать API Kubernetes в собственных программах.
Спецификация и статус объекта
Почти в каждом объекте Kubernetes есть два вложенных поля-объекта, которые управляют конфигурацией объекта: spec и status.
При создании объекта в поле spec указывается требуемое состояние (описание характеристик, которые должны быть у объекта).
Поле status описывает текущее состояние объекта, которое создаётся и обновляется самим Kubernetes и его компонентами. Управляющий слой Kubernetes непрерывно управляет фактическим состоянием каждого объекта, чтобы оно соответствовало требуемому состоянию, которое было задано пользователем.
Например: Deployment — это объект Kubernetes, представляющий работающее приложение в кластере. При создании объекта Deployment вы можете указать в его поле spec, что хотите иметь три реплики приложения. Система Kubernetes получит спецификацию объекта Deployment и запустит три экземпляра приложения, таким образом обновит статус (состояние) объекта, чтобы он соответствовал заданной спецификации. В случае сбоя одного из экземпляров (это влечет за собой изменение состояние), Kubernetes обнаружит несоответствие между спецификацией и статусом и исправит его, т.е. активирует новый экземпляр вместо того, который вышел из строя.
Для получения дополнительной информации о спецификации объекта, статусе и метаданных смотрите документ с соглашениями API Kubernetes.
Описание объекта Kubernetes
При создании объекта в Kubernetes нужно передать спецификацию объекта, которая содержит требуемое состояние, а также основную информацию об объекте (например, его имя). Когда вы используете API Kubernetes для создания объекта (напрямую либо через kubectl), соответствующий API-запрос должен включать в теле запроса всю указанную информацию в JSON-формате. В большинстве случаев вы будете передавать kubectl эти данные, записанные в файле .yaml. Тогда инструмент kubectl преобразует их в формат JSON при выполнении запроса к API.
Ниже представлен пример .yaml-файла, в котором заданы обязательные поля и спецификация объекта, необходимая для объекта Deployment в Kubernetes:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Один из способов создания объекта Deployment с помощью файла .yaml, показанного выше — использовать команду kubectl apply, которая принимает в качестве аргумента файл в формате .yaml. Например:
kubectl apply -f https://k8s.io/examples/application/deployment.yaml --record
Вывод будет примерно таким:
deployment.apps/nginx-deployment created
Обязательные поля
В файле .yaml создаваемого объекта Kubernetes необходимо указать значения для следующих полей:
apiVersion — используемая для создания объекта версия API Kuberneteskind — тип создаваемого объектаmetadata — данные, позволяющие идентифицировать объект (name, UID и необязательное поле namespace)spec — требуемое состояние объекта
Конкретный формат поля-объекта spec зависит от типа объекта Kubernetes и содержит вложенные поля, предназначенные только для используемого объекта. В справочнике API Kubernetes можно найти формат спецификации любого объекта Kubernetes.
Например, формат spec для объекта Pod находится в ядре PodSpec v1, а формат spec для Deployment — в DeploymentSpec v1 apps.
Что дальше
- Обзор API Kubernetes более подробно объясняет некоторые из API-концепций
- Познакомиться с наиболее важными и основными объектами в Kubernetes, например, с подами.
- Узнать подробнее про контролеры в Kubernetes
1.4.2 - Управление объектами Kubernetes
В инструменте командной строки kubectl есть несколько разных способов создания и управления объектами Kubernetes. На этой странице рассматриваются различные подходы. Изучите документацию по Kubectl для получения подробной информации по управлению объектами с помощью Kubectl.
Способы управления
Предупреждение:
Используйте только один способ для управления объектами Kubernetes. Применение нескольких методов управления к одному и тому же объекту может привести к неопределенному поведению.
| Способ управления |
Область применения |
Рекомендуемое окружение |
Количество поддерживаемых авторов |
Трудность изучения |
| Императивные команды |
Активные объекты |
Проекты в стадии разработки |
1+ |
Низкая |
| Императивная конфигурация объекта |
Отдельные файлы |
Продакшен-проекты |
1 |
Средняя |
| Декларативная конфигурация объекта |
Директории или файлы |
Продакшен-проекты |
1+ |
Сложная |
Императивные команды
При использовании императивных команд пользователь работает непосредственно с активными (текущими) объектами в кластере. Пользователь указывает выполняемые операции команде kubectl в качестве аргументов или флагов.
Это самый простой способ начать или выполнять одноразовые задачи в кластере. Из-за того, что происходит работа с активными объектами напрямую, нет возможности посмотреть историю предыдущих конфигураций.
Примеры
Запустите экземпляр контейнера nginx, посредством создания объекта Deployment:
kubectl run nginx --image nginx
То же самое, но с другим синтаксисом:
kubectl create deployment nginx --image nginx
Плюсы и минусы
Преимущества по сравнению с конфигурацией объекта:
- Простые команды, которые легко выучить и запомнить.
- Для применения изменений в кластер нужно только выполнить команды.
Недостатки по сравнению с конфигурацией объекта:
- Команды не интегрированы с процессом проверки (обзора) изменений.
- У команд нет журнала с изменениями.
- Команды не дают источник записей, за исключением активных объектов.
- Команды не содержат шаблон для создания новых объектов.
Императивная конфигурация объекта
В случае использования императивной конфигурации объекта команде kubectl устанавливают действие (создание, замена и т.д.), необязательные флаги и как минимум одно имя файла. Файл должен содержать полное определение объекта в формате YAML или JSON.
Посмотрите Справочник API для получения более подробной информации про определения объекта.
Предупреждение:
Императивная команда replace заменяет существующую спецификацию новой (переданной), удаляя все изменения в объекте, которые не определены в конфигурационном файле. Такой подход не следует использовать для типов ресурсов, спецификации которых обновляются независимо от конфигурационного файла.
Например, поле externalIPs в сервисах типа LoadBalancer обновляется кластером независимо от конфигурации.
Примеры
Создать объекты, определенные в конфигурационном файле:
kubectl create -f nginx.yaml
Удалить объекты, определенные в двух конфигурационных файлах:
kubectl delete -f nginx.yaml -f redis.yaml
Обновить объекты, определенные в конфигурационном файле, перезаписав текущую конфигурацию:
kubectl replace -f nginx.yaml
Плюсы и минусы
Преимущества по сравнению с императивными командами:
- Конфигурация объекта может храниться в системе управления версиями, такой как Git.
- Конфигурация объекта может быть интегрирована с процессами проверки изменений и логирования.
- Конфигурация объекта предусматривает шаблон для создания новых объектов.
Недостатки по сравнению с императивными командами:
- Конфигурация объекта требует наличие общего представления об схеме объекта.
- Конфигурация объекта предусматривает написание файла YAML.
Преимущества по сравнению с декларативной конфигурацией объекта:
- Императивная конфигурация объекта проще и легче для понимания.
- Начиная с Kubernetes 1.5, конфигурация императивных объектов стала лучше и совершеннее.
Недостатки по сравнению с декларативной конфигурацией объекта:
- Императивная конфигурация объекта наилучшим образом работает с файлами, а не с директориями.
- Обновления текущих объектов должны быть описаны в файлах конфигурации, в противном случае они будут потеряны при следующей замене.
Декларативная конфигурация объекта
При использовании декларативной конфигурации объекта пользователь работает с локальными конфигурационными файлами объекта, при этом он не определяет операции, которые будут выполняться над этими файлами. Операции создания, обновления и удаления автоматически для каждого объекта определяются kubectl. Этот механизм позволяет работать с директориями, в ситуациях, когда для разных объектов может потребоваться выполнение других операций.
Примечание:
Декларативная конфигурация объекта сохраняет изменения, сделанные другими, даже если эти изменения не будут зафиксированы снова в конфигурационный файл объекта.
Это достигается путем использования API-операции patch, чтобы записать только обнаруженные изменения, а не использовать для этого API-операцию replace, которая полностью заменяет конфигурацию объекта.
Примеры
Обработать все конфигурационные файлы объектов в директории configs и создать либо частично обновить активные объекты. Сначала можно выполнить diff, чтобы посмотреть, какие изменения будут внесены, и только после этого применить их:
kubectl diff -f configs/
kubectl apply -f configs/
Рекурсивная обработка директорий:
kubectl diff -R -f configs/
kubectl apply -R -f configs/
Плюсы и минусы
Преимущества по сравнению с императивной конфигурацией объекта:
- Изменения, внесенные непосредственно в активные объекты, будут сохранены, даже если они не отражены в конфигурационных файлах.
- Декларативная конфигурация объекта лучше работает с директориями и автоматически определяет тип операции (создание, частичное обновление, удаление) каждого объекта.
Недостатки по сравнению с императивной конфигурацией объекта:
- Декларативную конфигурацию объекта сложнее отладить и понять, когда можно получить неожиданные результаты.
- Частичные обновления с использованием различий приводит к сложным операциям слияния и исправления.
Что дальше
1.4.3 - Имена и идентификаторы объектов
Каждый объект в кластере имеет уникальное имя для конкретного типа ресурса.
Кроме этого, у каждого объекта Kubernetes есть собственный уникальный идентификатор (UID) в пределах кластера.
Например, в одном и том же пространстве имён может быть только один Pod-объект с именем myapp-1234, и при этом существовать объект Deployment с этим же названием myapp-1234.
Для создания пользовательских неуникальных атрибутов у Kubernetes есть метки и аннотации.
Имена
Клиентская строка, предназначенная для ссылки на объект в URL-адресе ресурса, например /api/v1/pods/some-name.
Указанное имя может иметь только один объект определённого типа. Но если вы удалите этот объект, вы можете создать новый с таким же именем
Ниже перечислены три типа распространённых требований к именам ресурсов.
Имена поддоменов DNS
Большинству типов ресурсов нужно указать имя, используемое в качестве имени поддомена DNS в соответствии с RFC 1123. Соответственно, имя должно:
- содержать не более 253 символов
- иметь только строчные буквенно-цифровые символы, '-' или '.'
- начинаться с буквенно-цифрового символа
- заканчивается буквенно-цифровым символом
Имена меток DNS
Некоторые типы ресурсов должны соответствовать стандарту меток DNS, который описан в RFC 1123. Таким образом, имя должно:
- содержать не более 63 символов
- содержать только строчные буквенно-цифровые символы или '-'
- начинаться с буквенно-цифрового символа
- заканчивается буквенно-цифровым символом
Имена сегментов пути
Определённые имена типов ресурсов должны быть закодированы для использования в качестве сегмента пути. Проще говоря, имя не может быть "." или "..", а также не может содержать "/" или "%".
Пример файла манифеста пода nginx-demo.
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Примечание:
У отдельных типов ресурсов есть дополнительные ограничения именования.
Уникальные идентификаторы
Уникальная строка, сгенерированная самим Kubernetes, для идентификации объектов.
У каждого объекта, созданного в течение всего периода работы кластера Kubernetes, есть собственный уникальный идентификатор (UID). Он предназначен для выяснения различий между событиями похожих сущностей.
Уникальные идентификатор (UID) в Kubernetes — это универсальные уникальные идентификаторы (известные также как Universally Unique IDentifier, сокращенно UUID).
Эти идентификаторы стандартизированы под названием ISO/IEC 9834-8, а также как ITU-T X.667.
Что дальше
1.4.4 - Пространства имён
Kubernetes поддерживает несколько виртуальных кластеров в одном физическом кластере. Такие виртуальные кластеры называются пространствами имён.
Причины использования нескольких пространств имён
Пространства имён применяются в окружениях с многочисленными пользователями, распределенными по нескольким командам или проектам. Пространства имён не нужно создавать, если есть кластеры с небольшим количеством пользователей (например, десяток пользователей). Пространства имён имеет смысл использовать, когда необходима такая функциональность.
Пространства имён определяют область имён. Имена ресурсов должны быть уникальными в пределах одного и того же пространства имён. Пространства имён не могут быть вложенными, а каждый ресурс Kubernetes может находиться только в одном пространстве имён.
Пространства имён — это способ разделения ресурсов кластера между несколькими пользователями (с помощью квоты ресурсов).
По умолчанию в будущих версиях Kubernetes объекты в одном и том же пространстве имён будут иметь одинаковую политику контроля доступа.
Не нужно использовать пространства имён только для разделения слегка отличающихся ресурсов, например, в случае разных версий одного и того же приложения. Используйте метки, чтобы различать ресурсы в рамках одного пространства имён.
Использование пространств имён
Создание и удаление пространств имён описаны в руководстве администратора по пространствам имён.
Просмотр пространств имён
Используйте следующую команду, чтобы вывести список существующих пространств имён в кластере:
NAME STATUS AGE
default Active 1d
kube-system Active 1d
kube-public Active 1d
По умолчанию в Kubernetes определены три пространства имён:
default — пространство имён по умолчанию для объектов без какого-либо другого пространства имён.kube-system — пространство имён для объектов, созданных Kuberneteskube-public — создаваемое автоматически пространство имён, которое доступно для чтения всем пользователям (включая также неаутентифицированных пользователей). Как правило, это пространство имён используется кластером, если некоторые ресурсы должны быть общедоступными для всего кластера. Главная особенность этого пространства имён — оно всего лишь соглашение, а не требование.
Определение пространства имён для отдельных команд
Используйте флаг --namespace, чтобы определить пространство имён только для текущего запроса.
Примеры:
kubectl run nginx --image=nginx --namespace=<insert-namespace-name-here>
kubectl get pods --namespace=<insert-namespace-name-here>
Определение пространства имён для всех команд
Можно определить пространство имён, которое должно использоваться для всех выполняемых команд kubectl в текущем контексте.
kubectl config set-context --current --namespace=<insert-namespace-name-here>
# Проверка
kubectl config view --minify | grep namespace:
Пространства имён и DNS
При создании сервиса создаётся соответствующая ему DNS-запись.
Эта запись вида <service-name>.<namespace-name>.svc.cluster.local означает, что если контейнер использует только <service-name>, то он будет локальным сервисом в пространстве имён. Это позволит применять одну и ту же конфигурацию в нескольких пространствах имен (например, development, staging и production). Если нужно обращаться к другим пространствам имён, то нужно использовать полностью определенное имя домена (FQDN).
Объекты без пространства имён
Большинство ресурсов Kubernetes (например, поды, сервисы, контроллеры репликации и другие) расположены в определённых пространствах имён. При этом сами ресурсы пространства имён не находятся ни в других пространствах имён. А такие низкоуровневые ресурсы, как узлы и persistentVolumes, не принадлежат ни одному пространству имён.
Чтобы посмотреть, какие ресурсы Kubernetes находятся в пространстве имён, а какие — нет, используйте следующие команды:
# Ресурсы в пространстве имён
kubectl api-resources --namespaced=true
# Ресурсы, не принадлежавшие ни одному пространству имён
kubectl api-resources --namespaced=false
Что дальше
1.4.5 - Метки и селекторы
Метки — это пары ключ-значение, которые добавляются к объектам, как поды.
Метки предназначены для идентификации атрибутов объектов, которые имеют значимость и важны для пользователей, но при этом не относятся напрямую к основной системе.
Метки можно использовать для группировки и выбора подмножеств объектов. Метки могут быть добавлены к объектам во время создания и изменены в любое время после этого.
Каждый объект может иметь набор меток в виде пары ключ-значение. Каждый ключ должен быть уникальным в рамках одного и того же объекта.
"metadata": {
"labels": {
"key1" : "value1",
"key2" : "value2"
}
}
Метки используются при получении и отслеживании объектов и в веб-панелях и CLI-инструментах. Любая неидентифицирующая информация должна быть записана в аннотации.
Причины использования
Метки позволяют пользователям гибко сопоставить их организационные структуры с системными объектами, не требуя от клиентов хранить эти соответствия.
Развертывания сервисов и процессы пакетной обработки часто являются многомерными сущностями (например, множество разделов или развертываний, несколько групп выпусков, несколько уровней приложения, несколько микросервисов на каждый уровень приложения). Для управления часто требуются сквозные операции, которые нарушают инкапсуляцию строго иерархических представлений, особенно жестких иерархий, определяемых инфраструктурой, а не пользователями.
Примеры меток:
"release" : "stable", "release" : "canary""environment" : "dev", "environment" : "qa", "environment" : "production""tier" : "frontend", "tier" : "backend", "tier" : "cache""partition" : "customerA", "partition" : "customerB""track" : "daily", "track" : "weekly"
Это всего лишь примеры часто используемых меток; конечно, вы можете использовать свои собственные. Помните о том, что ключ метки должна быть уникальной в пределах одного объекта.
Синтаксис и набор символов
Метки представляют собой пары ключ-значение. Разрешенные ключи метки имеют два сегмента, разделённые слешем (/): префикс (необязательно) и имя. Сегмент имени обязателен и должен содержать не более 63 символов, среди которых могут быть буквенно-цифровые символы ([a-z0-9A-Z]), а также дефисы (-), знаки подчеркивания (_), точки (.). Префикс не обязателен, но он быть поддоменом DNS: набор меток DNS, разделенных точками (.), общей длиной не более 253 символов, за которыми следует слеш (/).
Если префикс не указан, ключ метки считается закрытым для пользователя. Компоненты автоматизированной системы (например, kube-scheduler, kube-controller-manager, kube-apiserver, kubectl или другие сторонние), которые добавляют метки к объектам пользователя, должны указывать префикс.
Префиксы kubernetes.io/ и k8s.io/ зарезервированы для использования основными компонентами Kubernetes.
Например, ниже представлен конфигурационный файл объекта Pod с двумя метками environment: production и app: nginx:
apiVersion: v1
kind: Pod
metadata:
name: label-demo
labels:
environment: production
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Селекторы меток
В отличие от имен и идентификаторов, метки не гарантируют уникальность. Поэтому мы предполагаем, что многие объекты будут иметь одинаковые метки.
С помощью селектора меток клиент/пользователь может идентифицировать набор объектов. Селектор меток — основное средство группировки в Kubernetes.
В настоящее время API поддерживает два типа селекторов: на равенстве и на наборе.
Селектор меток может состоять из нескольких условий, разделенных запятыми. В таком случае все условия должны быть выполнены, поэтому запятая-разделитель работает как логический оператор И (&&).
Работа пустых или неопределённых селекторов зависит от контекста. Типы API, которые использует селекторы, должны задокументировать это поведение.
Примечание:
Для некоторых API-типов, например, ReplicaSets, селекторы меток двух экземпляров не должны дублироваться в пространстве имен, в противном случае контроллер может рассматривать их как конфликтующие инструкции и не сможет определить количество реплик.
Внимание:
Как для условий, основанных на равенстве, так и для условий на основе набора, не существует логического оператора ИЛИ (||). Убедитесь, что синтаксис фильтрации правильно составлен.
Условие равенства
Условия равенства или неравенства позволяют отфильтровать объекты по ключам и значениям меток. Сопоставляемые объекты должны удовлетворять всем указанным условиям меток, хотя при этом у объектов также могут быть заданы другие метки.
Доступны три оператора: =,==,!=. Первые два означают равенство (и являются всего лишь синонимами), а последний оператор определяет неравенство. Например:
environment = production
tier != frontend
Первый пример выбирает все ресурсы с ключом environment, у которого значение указано production.
Последний получает все ресурсы с ключом tier без значения frontend, а также все ресурсы, в которых нет метки с ключом tier.
Используя оператор запятой можно совместить показанные два условия в одно, запросив ресурсы, в которых есть значение метки production и исключить frontend: environment=production,tier!=frontend.
С помощью условия равенства в объектах Pod можно указать, какие нужно выбрать ресурсы. Например, в примере ниже объект Pod выбирает узлы с меткой "accelerator=nvidia-tesla-p100".
apiVersion: v1
kind: Pod
metadata:
name: cuda-test
spec:
containers:
- name: cuda-test
image: "registry.k8s.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-p100
Условие набора
Условие меток на основе набора фильтрует ключи в соответствии с набором значений. Поддерживаются три вида операторов: in, notin и exists (только идентификатор ключа). Например:
environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
В первом примере выбираются все ресурсы с ключом environment и значением production или qa.
Во втором примере выбираются все ресурсы с ключом tier и любыми значениями, кроме frontend и backend, а также все ресурсы без меток с ключом tier.
Третий пример выбирает все ресурсы, включая метку с ключом partition (с любым значением).
В четвертом примере выбираются все ресурсы без метки с ключом partition (с любым значением).
Как и логический оператор И работает разделитель в виде запятой. Таким образом, фильтрация ресурсов по ключу partition (вне зависимости от значения) и ключу environment с любым значением, кроме qa, можно получить с помощью следующего выражения: partition,environment notin (qa).
Селектор меток на основе набора — основная форма равенства, поскольку environment=production то же самое, что и environment in (production); аналогично, оператор != соответствует notin.
Условия набора могут использоваться одновременно с условия равенства. Например, так: partition in (customerA, customerB),environment!=qa.
API
Фильтрация LIST и WATCH
Операции LIST и WATCH могут использовать параметр запроса, чтобы указать селекторы меток фильтрации наборов объектов. Есть поддержка обоих условий (строка запроса URL ниже показывается в исходном виде):
- Условия на основе равенства:
?labelSelector=environment%3Dproduction,tier%3Dfrontend
- Условия на основе набора:
?labelSelector=environment+in+%28production%2Cqa%29%2Ctier+in+%28frontend%29
Указанные выше формы селектора меток можно использовать для просмотра или отслеживания ресурсов через REST-клиент. Например, apiserver с kubectl, который использует условие равенства:
kubectl get pods -l environment=production,tier=frontend
Либо используя условия на основе набора:
kubectl get pods -l 'environment in (production),tier in (frontend)'
Как уже показывалось, условия набора дают больше возможностей. Например, в них можно использовать подобие оператора И:
kubectl get pods -l 'environment in (production, qa)'
Либо можно воспользоваться исключающим сопоставлением с помощью оператора notin:
kubectl get pods -l 'environment,environment notin (frontend)'
Установка ссылок в API-объекты
Некоторые объекты Kubernetes, такие как services и replicationcontrollers, также используют селекторы меток для ссылки на наборы из других ресурсов, например, подов.
Service и ReplicationController
Набор подов, на которые указывает service, определяется через селектор меток. Аналогичным образом, количество подов, которыми должен управлять replicationcontroller, также формируются с использованием селектора меток.
Селекторы меток для обоих объектов записываются в словарях файлов формата json и yaml, при этом поддерживаются только селекторы с условием равенства:
"selector": {
"component" : "redis",
}
Или:
selector:
component: redis
Этот селектор (как в формате json, так и в yaml) эквивалентен component=redis или component in (redis).
Ресурсы, поддерживающие условия набора
Новые ресурсы, такие как Job, Deployment, ReplicaSet и DaemonSet, также поддерживают условия набора.
selector:
matchLabels:
component: redis
matchExpressions:
- {key: tier, operator: In, values: [cache]}
- {key: environment, operator: NotIn, values: [dev]}
matchLabels — словарь пар {key,value}. Каждая пара {key,value} в словаре matchLabels эквивалентна элементу matchExpressions, где поле key — "key", поле operator — "In", а массив values содержит только "value".
matchExpressions представляет собой список условий селектора пода. В качестве операторов могут быть In, NotIn, Exists и DoesNotExist. В случае использования In и NotIn должны заданы непустые значения. Все условия, как для matchLabels, так и для matchExpressions, объединяются с помощью логического И, поэтому при выборке объектов все они должны быть выполнены.
Выбор наборов узлов
Один из вариантов использования меток — возможность выбора набора узлов, в которых может быть развернут под.
Смотрите документацию про выбор узлов, чтобы получить дополнительную информацию.
1.4.6 - Аннотации
Аннотации Kubernetes можно использовать для добавления собственных метаданных к объектам. Такие клиенты, как инструменты и библиотеки, могут получить эти метаданные.
Добавление метаданных к объектам
Вы можете использовать метки или аннотации для добавления метаданных к объектам Kubernetes. Метки можно использовать для выбора объектов и для поиска коллекций объектов, которые соответствуют определенным условиям. В отличие от них аннотации не используются для идентификации и выбора объектов. Метаданные в аннотации могут быть маленькими или большими, структурированными или неструктурированными, кроме этого они включать символы, которые не разрешены в метках.
Аннотации, как и метки, являются коллекциями с наборами пар ключ-значение:
"metadata": {
"annotations": {
"key1" : "value1",
"key2" : "value2"
}
}
Некоторые примеры информации, которая может быть в аннотациях:
-
Поля, управляемые декларативным уровнем конфигурации. Добавление этих полей в виде аннотаций позволяет отличать их от значений по умолчанию, установленных клиентами или серверами, а также от автоматически сгенерированных полей и полей, заданных системами автоматического масштабирования.
-
Информация о сборке, выпуске или образе, например, метка времени, идентификаторы выпуска, ветка git, номера PR, хеши образов и адрес реестра.
-
Ссылки на репозитории логирования, мониторинга, аналитики или аудита.
-
Информация о клиентской библиотеке или инструменте, которая может использоваться при отладке (например, имя, версия и информация о сборке).
-
Информация об источнике пользователя или инструмента/системы, например, URL-адреса связанных объектов из других компонентов экосистемы.
-
Небольшие метаданные развертывания (например, конфигурация или контрольные точки).
-
Номера телефонов или пейджеров ответственных лиц или записи в справочнике, в которых можно найти нужную информацию, например, сайт группы.
-
Инструкции от конечных пользователей по исправлению работы или использования нестандартной функциональности.
Вместо использования аннотаций, вы можете сохранить такого рода информацию во внешней базе данных или директории, хотя это усложнило бы создание общих клиентских библиотек и инструментов развертывания, управления, самодиагностики и т.д.
Синтаксис и набор символов
Аннотации представляют собой пары ключ-значение. Разрешенные ключи аннотации имеют два сегмента, разделённые слешем (/): префикс (необязательно) и имя. Сегмент имени обязателен и должен содержать не более 63 символов, среди которых могут быть буквенно-цифровые символы([a-z0-9A-Z]), а также дефисы (-), знаки подчеркивания (_), точки (.). Префикс не обязателен, но он быть поддоменом DNS: набор меток DNS, разделенных точками (.), общей длиной не более 253 символов, за которыми следует слеш (/).
Если префикс не указан, ключ аннотации считается закрытым для пользователя. Компоненты автоматизированной системы (например, kube-scheduler, kube-controller-manager, kube-apiserver, kubectl или другие сторонние), которые добавляют аннотации к объектам пользователя, должны указывать префикс.
Префиксы kubernetes.io/ и k8s.io/ зарезервированы для использования основными компонентами Kubernetes.
Например, ниже представлен конфигурационный файл объекта Pod с аннотацией imageregistry: https://hub.docker.com/:
apiVersion: v1
kind: Pod
metadata:
name: annotations-demo
annotations:
imageregistry: "https://hub.docker.com/"
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Что дальше
Узнать подробнее про метки и селекторы.
1.4.7 - Селекторы полей
Селекторы полей позволяют выбирать ресурсы Kubernetes, исходя из значения одного или нескольких полей ресурсов. Ниже приведены несколько примеров запросов селекторов полей:
metadata.name=my-servicemetadata.namespace!=defaultstatus.phase=Pending
Следующая команда kubectl выбирает все Pod-объекты, в которых значение поля status.phase равно Running:
kubectl get pods --field-selector status.phase=Running
Примечание:
По сути, селекторы полей являются фильтрами ресурсов. По умолчанию нет установленных селекторов/фильтров, поэтому выбираются ресурсы всех типов. Это означает, что два запроса kubectl ниже одинаковы:
kubectl get pods
kubectl get pods --field-selector ""
Поддерживаемые поля
Доступные селекторы полей зависят от типа ресурса Kubernetes. У всех типов ресурсов есть поля metadata.name и metadata.namespace. При использовании несуществующего селекторов полей приведёт к возникновению ошибки. Например:
kubectl get ingress --field-selector foo.bar=baz
Error from server (BadRequest): Unable to find "ingresses" that match label selector "", field selector "foo.bar=baz": "foo.bar" is not a known field selector: only "metadata.name", "metadata.namespace"
Поддерживаемые операторы
Можно использовать операторы =, == и != в селекторах полей (= и == — синонимы). Например, следующая команда kubectl выбирает все сервисы Kubernetes, не принадлежавшие пространству имен default:
kubectl get services --all-namespaces --field-selector metadata.namespace!=default
Составные селекторы
Аналогично метки и другим селекторам, несколько селекторы полей могут быть объединены через запятую. Приведенная ниже команда kubectl выбирает все Pod-объекты, у которых значение поле status.phase, отличное от Running, а поле spec.restartPolicy имеет значение Always:
kubectl get pods --field-selector=status.phase!=Running,spec.restartPolicy=Always
Множественные типы ресурсов
Можно использовать селекторы полей с несколькими типами ресурсов одновременно. Команда kubectl выбирает все объекты StatefulSet и Services, не включенные в пространство имен default:
kubectl get statefulsets,services --all-namespaces --field-selector metadata.namespace!=default
1.4.8 - Рекомендуемые метки
Вы можете визуализировать и управлять объектами Kubernetes не только с помощью kubectl и панели управления. С помощью единого набора меток можно единообразно описывать объекты, что позволяет инструментам согласованно работать между собой.
В дополнение к существующим инструментам, рекомендуемый набор меток описывают приложения в том виде, в котором они могут быть получены.
Метаданные сосредоточены на понятии приложение. Kubernetes — это не платформа как услуга (PaaS), поэтому не закрепляет формальное понятие приложения.
Вместо этого приложения являются неформальными и описываются через метаданные. Определение приложения довольно расплывчатое.
Примечание:
Это рекомендуемые для использования метки. Они облегчают процесс управления приложениями, но при этом не являются обязательными для основных инструментов.
Общие метки и аннотации используют один и тот же префикс: app.kubernetes.io. Метки без префикса являются приватными для пользователей. Совместно используемый префикс гарантирует, что общие метки не будут влиять на пользовательские метки.
Метки
Чтобы извлечь максимум пользы от использования таких меток, они должны добавляться к каждому ресурсному объекту.
| Ключ |
Описание |
Пример |
Тип |
app.kubernetes.io/name |
Имя приложения |
mysql |
string |
app.kubernetes.io/instance |
Уникальное имя экземпляра приложения |
wordpress-abcxzy |
string |
app.kubernetes.io/version |
Текущая версия приложения (например, семантическая версия, хеш коммита и т.д.) |
5.7.21 |
string |
app.kubernetes.io/component |
Имя компонента в архитектуре |
database |
string |
app.kubernetes.io/part-of |
Имя основного приложения, частью которого является текущий объект |
wordpress |
string |
app.kubernetes.io/managed-by |
Инструмент управления приложением |
helm |
string |
Для демонстрации этих меток, рассмотрим следующий объект StatefulSet:
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
app.kubernetes.io/managed-by: helm
Приложения и экземпляры приложений
Одно и то же приложение может быть установлено несколько раз в кластер Kubernetes, в ряде случаев — в одинаковое пространство имен. Например, WordPress может быть установлен более одного раза, тогда каждый из сайтов будет иметь собственный установленный экземпляр WordPress.
Имя приложения и имя экземпляра хранятся по отдельности. Например, WordPress имеет ключ app.kubernetes.io/name со значением wordpress, при этом у него есть имя экземпляра, представленное ключом app.kubernetes.io/instance со значением wordpress-abcxzy. Такой механизм позволяет идентифицировать как приложение, так и экземпляры приложения. У каждого экземпляра приложения должно быть уникальное имя.
Примеры
Следующие примеры показывают разные способы использования общих меток, поэтому они различаются по степени сложности.
Простой сервис без состояния
Допустим, у нас есть простой сервис без состояния, развернутый с помощью объектов Deployment и Service. Следующие два фрагмента конфигурации показывают, как можно использовать метки в самом простом варианте.
Объект Deployment используется для наблюдения за подами, на которых запущено приложение.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxzy
...
Объект Service используется для открытия доступа к приложению.
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxzy
...
Веб-приложение с базой данных
Рассмотрим случай немного посложнее: веб-приложение (WordPress), которое использует базу данных (MySQL), установленное с помощью Helm. В следующих фрагментов конфигурации объектов отображена отправная точка развертывания такого приложения.
Следующий объект Deployment используется для WordPress:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
Объект Service используется для открытия доступа к WordPress:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
MySQL открывается в виде StatefulSet с метаданными как для самого приложения, так и основного (родительского) приложения, к которому принадлежит СУБД:
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
...
Объект Service предоставляет MySQL в составе WordPress:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
...
Вы заметите, что StatefulSet и Service MySQL содержат больше информации о MySQL и WordPress.
2 - Кластерная Архитектура
Архитектурные концепции, лежащие в основе Kubernetes.
2.1 - Узлы
Kubernetes запускает ваши приложения, помещая контейнеры в Поды для запуска на Узлах (Nodes).
В зависимости от кластера, узел может быть виртуальной или физической машиной. Каждый узел
содержит сервисы, необходимые для запуска
Подов, управляемых
control plane (управляющим слоем).
Обычно у вас есть несколько узлов в кластере; однако в среде обучения или среде
с ограниченными ресурсами у вас может быть только один.
Компоненты на узле включают
kubelet,
среду выполнения контейнера и
kube-proxy.
Управление
Существует два основных способа добавления Узлов в API сервер:
- Kubelet на узле саморегистрируется в управляющем слое
- Вы или другой пользователь вручную добавляете объект Узла
После того как вы создадите объект Узла или kubelet на узле самозарегистируется,
управляющий слой проверяет, является ли новый объект Узла валидным (правильным). Например, если вы
попробуете создать Узел при помощи следующего JSON манифеста:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}
Kubernetes создает внутри себя объект Узла (представление). Kubernetes проверяет,
что kubelet зарегистрировался на API сервере, который совпадает со значением поля metadata.name Узла.
Если узел здоров (если все необходимые сервисы запущены),
он имеет право на запуск Пода. В противном случае этот узел игнорируется для любой активности кластера
до тех пор, пока он не станет здоровым.
Примечание:
Kubernetes сохраняет объект для невалидного Узла и продолжает проверять, становится ли он здоровым.
Вы или контроллер должны явно удалить объект Узла, чтобы
остановить проверку доступности узла.
Имя объекта Узла должно быть валидным
именем поддомена DNS.
Саморегистрация Узлов
Когда kubelet флаг --register-node имеет значение true (по умолчанию), то kubelet будет пытаться
зарегистрировать себя на API сервере. Это наиболее предпочтительная модель, используемая большинством дистрибутивов.
Для саморегистрации kubelet запускается со следующими опциями:
-
--kubeconfig - Путь к учетным данным для аутентификации на API сервере.
-
--cloud-provider - Как общаться с облачным провайдером, чтобы прочитать метаданные о себе.
-
--register-node - Автоматически зарегистрироваться на API сервере.
-
--register-with-taints - Зарегистрировать узел с приведенным списком ограничений (taints) (разделенных запятыми <key>=<value>:<effect>).
Ничего не делает, если register-node - false.
-
--node-ip - IP-адрес узла.
-
--node-labels - Метки для добавления при регистрации узла в кластере (смотрите ограничения для меток, установленные плагином согласования (admission plugin) NodeRestriction).
-
--node-status-update-frequency - Указывает, как часто kubelet отправляет статус узла мастеру.
Когда режим авторизации Узла и
плагин согласования NodeRestriction включены,
kubelet'ы имеют право только создавать/изменять свой собственный ресурс Узла.
Ручное администрирование узла
Вы можете создавать и изменять объекты узла используя
kubectl.
Когда вы хотите создать объекты Узла вручную, установите kubelet флаг --register-node=false.
Вы можете изменять объекты Узла независимо от настройки --register-node.
Например, вы можете установить метки на существующем Узле или пометить его не назначаемым.
Вы можете использовать метки на Узлах в сочетании с селекторами узла на Подах для управления планированием.
Например, вы можете ограничить Под, иметь право на запуск только на группе доступных узлов.
Маркировка узла как не назначаемого предотвращает размещение планировщиком новых подов на этом Узле,
но не влияет на существующие Поды на Узле. Это полезно в качестве
подготовительного шага перед перезагрузкой узла или другим обслуживанием.
Чтобы отметить Узел не назначаемым, выполните:
Примечание:
Поды, являющиеся частью
DaemonSet допускают
запуск на не назначаемом Узле. DaemonSets обычно обеспечивает локальные сервисы узла,
которые должны запускаться на Узле, даже если узел вытесняется для запуска приложений.
Статус Узла
Статус узла содержит следующие данные:
Вы можете использовать kubectl для просмотра статуса Узла и других деталей:
kubectl describe node <insert-node-name-here>
Каждая секция из вывода команды описана ниже.
Адреса (Addresses)
Использование этих полей варьируется в зависимости от вашего облачного провайдера или конфигурации физических серверов (bare metal).
- HostName: Имя хоста, сообщаемое ядром узла. Может быть переопределено через kubelet
--hostname-override параметр.
- ExternalIP: Обычно, IP адрес узла, который является внешне маршрутизируемым (доступен за пределами кластера).
- InternalIP: Обычно, IP адрес узла, который маршрутизируется только внутри кластера.
Условия (Conditions)
Поле conditions описывает статус всех Running узлов. Примеры условий включают в себя:
Условия узла и описание того, когда применяется каждое условие.
| Условие Узла |
Описание |
Ready |
True если узел здоров и готов принять поды, False если узел нездоров и не принимает поды, и Unknown если контроллер узла не получал информацию от узла в течение последнего периода node-monitor-grace-period (по умолчанию 40 секунд) |
DiskPressure |
True если присутствует давление на размер диска - то есть, если емкость диска мала; иначе False |
MemoryPressure |
True если существует давление на память узла - то есть, если памяти на узле мало; иначе False |
PIDPressure |
True если существует давление на процессы - то есть, если на узле слишком много процессов; иначе False |
NetworkUnavailable |
True если сеть для узла настроена некорректно, иначе False |
Примечание:
Если вы используете инструменты командной строки для вывода сведений об блокированном узле,
то Условие включает SchedulingDisabled. SchedulingDisabled не является Условием в Kubernetes API;
вместо этого блокированные узлы помечены как Не назначаемые в их спецификации.
Состояние узла представлено в виде JSON объекта. Например, следующая структура описывает здоровый узел:
"conditions": [
{
"type": "Ready",
"status": "True",
"reason": "KubeletReady",
"message": "kubelet is posting ready status",
"lastHeartbeatTime": "2019-06-05T18:38:35Z",
"lastTransitionTime": "2019-06-05T11:41:27Z"
}
]
Если значение параметра Status для условия Ready остается Unknown или False
дольше чем период pod-eviction-timeout(аргумент, переданный в
kube-controller-manager), то все Поды
на узле планируются к удалению контроллером узла. По умолчанию таймаут выселения пять минут.
В некоторых случаях, когда узел недоступен, API сервер не может связаться с kubelet на узле.
Решение об удалении подов не может быть передано в kubelet до тех пор, пока связь с API сервером не будет восстановлена.
В то же время поды, которые запланированы к удалению, могут продолжать работать на отделенном узле.
Контроллер узла не будет принудительно удалять поды до тех пор, пока не будет подтверждено,
что они перестали работать в кластере. Вы можете видеть, что поды, которые могут работать на недоступном узле,
находятся в состоянии Terminating или Unknown. В тех случаях, когда Kubernetes не может сделать вывод
из основной инфраструктуры о том, что узел окончательно покинул кластер, администратору кластера может потребоваться
удалить объект узла вручную. Удаление объекта узла из Kubernetes приводит к удалению всех объектов Подов, запущенных
на узле, с API сервера и освобождает их имена.
Контроллер жизненного цикла узла автоматически создает
ограничения (taints), которые представляют собой условия.
Планировщик учитывает ограничения Узла при назначении Пода на Узел.
Поды так же могут иметь допуски (tolerations), что позволяет им сопротивляться ограничениям Узла.
Смотрите раздел Ограничить Узлы по Условию
для дополнительной информации.
Емкость и Выделяемые ресурсы (Capacity and Allocatable)
Описывает ресурсы, доступные на узле: CPU, память и максимальное количество подов,
которые могут быть запланированы на узле.
Поля в блоке capacity указывают общее количество ресурсов, которые есть на Узле.
Блок allocatable указывает количество ресурсов на Узле,
которые доступны для использования обычными Подами.
Вы можете прочитать больше о емкости и выделяемых ресурсах, изучая, как зарезервировать вычислительные ресурсы на Узле.
Информация (Info)
Описывает общую информацию об узле, такую как версия ядра, версия Kubernetes (версии kubelet и kube-proxy), версия Docker (если используется) и название ОС.
Эта информация собирается Kubelet'ом на узле.
Контроллер узла
Контроллер узла является компонентом
управляющего слоя Kubernetes, который управляет различными аспектами узлов.
Контроллер узла играет различные роли в жизни узла. Первая - назначение CIDR-блока узлу
при его регистрации (если включено назначение CIDR).
Вторая - поддержание в актуальном состоянии внутреннего списка узлов контроллера узла
согласно списку доступных машин облачного провайдера. При работе в облачной среде всякий раз,
когда узел неисправен, контроллер узла запрашивает облачного провайдера, доступна ли
виртуальная машина для этого узла. Если нет, то контроллер узла удаляет узел из
своего списка узлов.
Третья - это мониторинг работоспособности узлов. Контроллер узла
отвечает за обновление условия NodeReady для NodeStatus на
ConditionUnknown, когда узел становится недоступным (т.е. контроллер узла
по какой-то причине перестает получать сердцебиения (heartbeats) от узла,
например, из-за того, что узел упал), и затем позже выселяет все поды с узла
(используя мягкое (graceful) завершение) если узел продолжает быть недоступным.
(По умолчанию таймауты составляют 40 секунд, чтобы начать сообщать ConditionUnknown,
и 5 минут после, чтобы начать выселять поды.)
Контроллер узла проверяет состояние каждого узла каждые --node-monitor-period секунд.
Сердцебиения
Сердцебиения, посылаемые узлами Kubernetes, помогают определить доступность узла.
Существует две формы сердцебиений: обновление NodeStatus и
Lease объект.
Каждый узел имеет связанный с ним Lease объект в kube-node-lease
namespace.
Lease - это легковесный ресурс, который улучшает производительность
сердцебиений узла при масштабировании кластера.
Kubelet отвечает за создание и обновление NodeStatus и Lease объекта.
- Kubelet обновляет
NodeStatus либо когда происходит изменение статуса,
либо если в течение настроенного интервала обновления не было. По умолчанию
интервал для обновлений NodeStatus составляет 5 минут (намного больше,
чем 40-секундный стандартный таймаут для недоступных узлов).
- Kubelet создает и затем обновляет свой Lease объект каждый 10 секунд
(интервал обновления по умолчанию). Lease обновления происходят независимо от
NodeStatus обновлений. Если обновление Lease завершается неудачно,
kubelet повторяет попытку с экспоненциальным откатом, начинающимся с 200 миллисекунд и ограниченным 7 секундами.
Надежность
В большинстве случаев контроллер узла ограничивает скорость выселения
до --node-eviction-rate (по умолчанию 0,1) в секунду, что означает,
что он не выселяет поды с узлов быстрее чем с одного узла в 10 секунд.
Поведение выселения узла изменяется, когда узел в текущей зоне доступности
становится нездоровым. Контроллер узла проверяет, какой процент узлов в зоне
нездоров (NodeReady условие в значении ConditionUnknown или ConditiononFalse)
в одно и то же время. Если доля нездоровых узлов не меньше
--unhealthy-zone-threshold (по умолчанию 0.55), то скорость выселения уменьшается:
если кластер небольшой (т.е. количество узлов меньше или равно
--large-cluster-size-threshold - по умолчанию, 50), то выселения прекращаются,
в противном случае скорость выселения снижается до
--secondary-node-eviction-rate (по умолчанию, 0.01) в секунду.
Причина, по которой эти политики реализуются для каждой зоны доступности, заключается в том,
что одна зона доступности может стать отделенной от мастера, в то время как другие
остаются подключенными. Если ваш кластер не охватывает несколько зон доступности
облачного провайдера, то существует только одна зона доступности (весь кластер).
Основная причина разнесения ваших узлов по зонам доступности заключается в том,
что приложения могут быть перенесены в здоровые зоны, когда одна из зон полностью
становится недоступной. Поэтому, если все узлы в зоне нездоровы, то контроллер узла
выселяет поды с нормальной скоростью --node-eviction-rate. Крайний случай - когда все зоны
полностью нездоровы (т.е. в кластере нет здоровых узлов). В таком случае
контроллер узла предполагает, что существует некоторая проблема с подключением к мастеру,
и останавливает все выселения, пока какое-нибудь подключение не будет восстановлено.
Контроллер узла также отвечает за выселение подов, запущенных на узлах с
NoExecute ограничениями, за исключением тех подов, которые сопротивляются этим ограничениям.
Контроллер узла так же добавляет ограничения
соответствующие проблемам узла, таким как узел недоступен или не готов. Это означает,
что планировщик не будет размещать поды на нездоровых узлах.
Внимание:
kubectl cordon помечает узел как 'не назначаемый', что имеет побочный эффект от контроллера сервисов,
удаляющего узел из любых списков целей LoadBalancer узла, на которые он ранее имел право,
эффективно убирая входящий трафик балансировщика нагрузки с блокированного узла(ов).
Емкость узла
Объекты узла отслеживают информацию о емкости ресурсов узла (например,
объем доступной памяти и количество CPU).
Узлы, которые самостоятельно зарегистрировались, сообщают
о своей емкости во время регистрации. Если вы вручную
добавляете узел, то вам нужно задать информацию о емкости узла при его добавлении.
Планировщик Kubernetes гарантирует,
что для всех Подов на Узле достаточно ресурсов. Планировщик проверяет,
что сумма requests от контейнеров на узле не превышает емкость узла.
Эта сумма requests включает все контейнеры, управляемые kubelet,
но исключает любые контейнеры, запущенные непосредственно средой выполнения контейнера,
а также исключает любые процессы, запущенные вне контроля kubelet.
Топология узла
СТАТУС ФИЧИ: Kubernetes v1.16 [alpha]
Если вы включили TopologyManager
feature gate, то kubelet
может использовать подсказки топологии при принятии решений о выделении ресурсов.
Смотрите Контроль Политик Управления Топологией на Узле
для дополнительной информации.
Что дальше
2.2 - Связь между управляющим слоем и узлом
Этот документ описывает связь между API-сервером и кластером Kubernetes. Цель состоит в том, чтобы позволить пользователям настраивать свою установку для усиления сетевой конфигурации, чтобы кластер мог работать в ненадежной сети (или на полностью общедоступных IP-адресах облачного провайдера).
От узла к управляющему слою
В Kubernetes имеется API шаблон «ступица и спица» (hub-and-spoke). Все используемые API из узлов (или которые запускают pod-ы) завершает apiserver. Ни один из других компонентов управляющего слоя не предназначен для предоставления удаленных сервисов. Apiserver настроен на прослушивание удаленных подключений через безопасный порт HTTPS (обычно 443) с одной или несколькими включенными формами аутентификации клиента.
Должна быть включена одна или несколько форм авторизации, особенно, если разрешены анонимные запросы или ServiceAccount токены.
Узлы должны быть снабжены публичным корневым сертификатом для кластера, чтобы они могли безопасно подключаться к apiserver-у вместе с действительными учетными данными клиента. Хороший подход заключается в том, чтобы учетные данные клиента, предоставляемые kubelet-у, имели форму клиентского сертификата. См. Информацию о загрузке kubelet TLS bootstrapping для автоматической подготовки клиентских сертификатов kubelet.
Pod-ы, которые хотят подключиться к apiserver, могут сделать это безопасно, используя ServiceAccount, чтобы Kubernetes автоматически вводил общедоступный корневой сертификат и действительный токен-носитель в pod при его создании.
Служба kubernetes (в пространстве имен default) настроена с виртуальным IP-адресом, который перенаправляет (через kube-proxy) на HTTPS эндпоинт apiserver-а.
Компоненты уровня управления также взаимодействуют с кластером apiserver-а через защищенный порт.
В результате режим работы по умолчанию для соединений от узлов и модулей, работающих на узлах, к управляющему слою по умолчанию защищен и может работать в ненадежных и/или общедоступных сетях.
От управляющего слоя к узлу
Существуют два пути связи управляющего слоя (API-сервера) с узлами. Первый - от apiserver-а до kubelet процесса, который выполняется на каждом узле кластера. Второй - от apiserver к любому узлу, pod-у или службе через промежуточную функциональность apiserver-а.
apiserver в kubelet
Соединение из apiserver-а к kubelet используются для:
- Извлечения логов с pod-ов.
- Прикрепление (через kubectl) к запущенным pod-ам.
- Обеспечение функциональности переадресации портов kubelet.
Эти соединения завершаются на HTTPS эндпоинте kubelet-a. По умолчанию apiserver не проверяет сертификат обслуживания kubelet-ов, что делает соединение подверженным к атаке «человек посередине» (man-in-the-middle) и небезопасным к запуску в ненадежных и/или общедоступных сетях.
Для проверки этого соединения используется флаг --kubelet-certificate-authority чтобы предоставить apiserver-у набор корневых (root) сертификатов для проверки сертификата обслуживания kubelet-ов.
Если это не возможно, используйте SSH-тунелирование между apiserver-ом и kubelet, если это необходимо, чтобы избежать подключения по ненадежной или общедоступной сети.
Наконец, должны быть включены аутентификация или авторизация kubelet для защиты kubelet API.
apiserver для узлов, pod-ов, и служб
Соединения с apiserver к узлу, поду или сервису по умолчанию осуществляются по-обычному HTTP-соединению и поэтому не аутентифицируются, и не шифруются. Они могут быть запущены по защищенному HTTPS-соединению, после добавления префикса https: к имени узла, пода или сервиса в URL-адресе API, но они не будут проверять сертификат предоставленный HTTPS эндпоинтом, как и не будут предоставлять учетные данные клиента. Таким образом, хотя соединение будет зашифровано, оно не обеспечит никаких гарантий целостности. Эти соединения в настоящее время небезопасны для запуска в ненадежных или общедоступных сетях.
SSH-туннели
Kubernetes поддерживает SSH-туннели для защиты путей связи от управляющего слоя к узлам. В этой конфигурации apiserver инициирует SSH-туннель для каждого узла в кластере (подключается к ssh-серверу, прослушивая порт 22) и передает весь трафик предназначенный для kubelet, узлу, pod-у или службе через туннель. Этот туннель гарантирует, что трафик не выводится за пределы сети, в которой работает узел.
SSH-туннели в настоящее время устарели, поэтому вы не должны использовать их, если не знаете, что делаете. Служба подключения является заменой этого канала связи.
Служба подключения
СТАТУС ФИЧИ: Kubernetes v1.18 [beta]
В качестве замены SSH-туннелям, служба подключения обеспечивает прокси TCP-уровня для взаимодействия управляющего слоя с кластером. Служба подключения состоит из двух частей: сервер подключения к сети управляющего слоя и агентов подключения в сети узлов. Агенты службы подключения инициируют подключения к серверу подключения и поддерживают сетевое подключение. После включения службы подключения, весь трафик с управляющего слоя на узлы проходит через эти соединения.
Следуйте инструкциям Задача службы подключения, чтобы настроить службу подключения в кластере.
2.3 - Контроллеры
В робототехнике и автоматизации, цикл управления - это непрерывный цикл, который регулирует состояние системы.
Вот один из примеров контура управления: термостат в помещении.
Когда вы устанавливаете температуру, это говорит термостату о вашем желаемом состоянии. Фактическая температура в помещении - это
текущее состояние. Термостат действует так, чтобы приблизить текущее состояние к желаемому состоянию, путем включения или выключения оборудования.
Контроллеры в Kubernetes - управляющие циклы, которые отслеживают состояние вашего
кластера, затем вносят или запрашивают
изменения там, где это необходимо.
Каждый контроллер пытается привести текущее состояние кластера ближе к желаемому состоянию.
Шаблон контроллера
Контроллер отслеживает по крайней мере один тип ресурса Kubernetes.
Эти объекты
имеют поле спецификации, которое представляет желаемое состояние. Контроллер (ы) для этого ресурса несут ответственность за приближение текущего состояния к желаемому состоянию
Контроллер может выполнить это действие сам; чаще всего в Kubernetes,
контроллер отправляет сообщения на
сервер API которые имеют
полезные побочные эффекты. Пример этого вы можете увидеть ниже.
Управление с помощью сервера API
Контроллер Job является примером встроенного контроллера Kubernetes. Встроенные контроллеры управляют состоянием, взаимодействуя с кластером сервера API.
Задание - это ресурс Kubernetes, который запускает
Pod, или возможно несколько Pod-ов, выполняющих задачу и затем останавливающихся.
(После планирования, Pod объекты становятся частью желаемого состояния для kubelet).
Когда контроллер задания видит новую задачу, он убеждается что где-то в вашем кластере kubelet-ы на множестве узлов запускают нужное количество Pod-ов для выполнения работы.
Контроллер задания сам по себе не запускает никакие Pod-ы или контейнеры. Вместо этого контроллер задания сообщает серверу API о создании или удалении Pod-ов.
Другие компоненты в
управляющем слое
действуют на основе информации (имеются ли новые запланированные Pod-ы для запуска), и в итоге работа завершается.
После того как вы создадите новое задание, желаемое состояние для этого задания будет завершено. Контроллер задания приближает текущее состояние этой задачи к желаемому состоянию: создает Pod-ы, выполняющие работу, которую вы хотели для этой задачи, чтобы задание было ближе к завершению.
Контроллеры также обновляют объекты которые их настраивают.
Например: как только работа выполнена для задания, контроллер задания обновляет этот объект задание, чтобы пометить его как Завершенный.
(Это немного похоже на то, как некоторые термостаты выключают свет, чтобы указать, что теперь ваша комната имеет установленную вами температуру).
Прямое управление
В отличие от Задания, некоторым контроллерам нужно вносить изменения в вещи за пределами вашего кластера.
Например, если вы используете контур управления, чтобы убедиться, что в вашем кластере достаточно Узлов,
тогда этому контроллеру нужно что-то вне текущего кластера, чтобы при необходимости запустить новые узлы.
Контроллеры, которые взаимодействуют с внешним состоянием, находят свое желаемое состояние с сервера API, а затем напрямую взаимодействуют с внешней системой, чтобы приблизить текущее состояние.
(На самом деле существует контроллер, который горизонтально масштабирует узлы в вашем кластере.)
Важным моментом здесь является то, что контроллер вносит некоторые изменения, чтобы вызвать желаемое состояние, а затем сообщает текущее состояние обратно на сервер API вашего кластера. Другие контуры управления могут наблюдать за этими отчетными данными и предпринимать собственные действия.
В примере с термостатом, если в помещении очень холодно, тогда другой контроллер может также включить обогреватель для защиты от замерзания. В кластерах Kubernetes управляющий слой косвенно работает с инструментами управления IP-адресами, службами хранения данных, API облачных провайдеров и другими службами для реализации
расширения Kubernetes.
Желаемое против текущего состояния
Kubernetes использует систему вида cloud-native и способен справляться с постоянными изменениями.
Ваш кластер может изменяться в любой по мере выполнения работы и контуры управления автоматически устраняют сбой. Это означает, что потенциально Ваш кластер никогда не достигнет стабильного состояния.
Пока контроллеры вашего кластера работают и могут вносить полезные изменения, не имеет значения, является ли общее состояние стабильным или нет.
Дизайн
В качестве принципа своей конструкции Kubernetes использует множество контроллеров, каждый из которых управляет определенным аспектом состояния кластера. Чаще всего конкретный контур управления (контроллер) использует один вид ресурса в качестве своего желаемого состояния и имеет другой вид ресурса, которым он управляет, чтобы это случилось. Например, контроллер для заданий отслеживает объекты заданий (для обнаружения новой работы) и объекты модулей (для выполнения заданий, а затем для того, чтобы видеть, когда работа завершена). В этом случае что-то еще создает задания, тогда как контроллер заданий создает Pod-ы.
Полезно иметь простые контроллеры, а не один монолитный набор взаимосвязанных контуров управления. Контроллеры могут выйти из строя, поэтому Kubernetes предназначен для этого.
Примечание:
Существует несколько контроллеров, которые создают или обновляют один и тот же тип объекта. За кулисами контроллеры Kubernetes следят за тем, чтобы обращать внимание только на ресурсы, связанные с их контролирующим ресурсом.
Например, у вас могут быть развертывания и задания; они оба создают Pod-ы. Контроллер заданий не удаляет Pod-ы созданные вашим развертыванием, потому что имеется информационные (метки)
которые могут быть использованы контроллерами тем самым показывая отличие Pod-ов.
Способы запуска контроллеров
Kubernetes поставляется с набором встроенных контроллеров, которые работают внутри kube-controller-manager. Эти встроенные контроллеры обеспечивают важные основные функции.
Контроллер развертывания и контроллер заданий - это примеры контроллеров, которые входят в состав самого Kubernetes («встроенные» контроллеры).
Kubernetes позволяет вам запускать устойчивый управляющий слой (control plane), так что в случае отказа одного из встроенных контроллеров работу берет на себя другая часть управляющего слоя.
Вы можете найти контроллеры, которые работают вне управляющего слоя, чтобы расширить Kubernetes.
Или, если вы хотите, можете написать новый контроллер самостоятельно. Вы можете запустить свой собственный контроллер в виде наборов Pod-ов,
или внешнее в Kubernetes. Что подойдет лучше всего, будет зависеть от того, что делает этот конкретный контроллер.
Что дальше
2.4 - Диспетчер облачных контроллеров
СТАТУС ФИЧИ: Kubernetes v1.11 [beta]
Технологии облачной инфраструктуры позволяют запускать Kubernetes в общедоступных, частных и гибридных облаках. Kubernetes верит в автоматизированную, управляемую API инфраструктуру без жесткой связи между компонентами.
Диспетчер облачных контроллеров компонент управляющего слоя Kubernetes, встраивающий специфику облака в логику управления. Диспетчер облачных контроллеров позволяет связать кластер с API поставщика облачных услуг и отделить компоненты, взаимодействующие с этой облачной платформой, от компонентов, взаимодействующих только с вашим кластером.
Отделяя логику взаимодействия между Kubernetes и базовой облачной инфраструктурой, компонент cloud-controller-manager позволяет поставщикам облачных услуг выпускать функции в другом темпе по сравнению с основным проектом Kubernetes.
Диспетчер облачных контроллеров спроектирован с использованием механизма плагинов, которые позволяют различным облачным провайдерам интегрировать свои платформы с Kubernetes.
Дизайн

Диспетчер облачных контроллеров работает в управляющем слое (control plane) как реплицированный набор процессов (обычно это контейнер в Pod-ах). Каждый диспетчер облачных контроллеров реализует множество контроллеров в единственном процессе.
Примечание:
Вы также можете запустить диспетчер облачных контроллеров как
дополнение Kubernetes, а не как часть управляющего слоя.
Функции диспетчера облачных контроллеров
Контроллеры внутри диспетчера облачных контроллеров включают в себя:
Контроллер узла
Контроллер узла отвечает за создание объектов узла при создании новых серверов в вашей облачной инфраструктуре. Контроллер узла получает информацию о работающих хостах внутри вашей арендуемой инфраструктуры облачного провайдера.
Контроллер узла выполняет следующие функции:
- Инициализация объектов узла для каждого сервера, которые контроллер получает через API облачного провайдера.
- Аннотирование и маркировка объектов узла специфичной для облака информацией, такой как регион узла и доступные ему ресурсы (процессор, память и т.д.).
- Получение имени хоста и сетевых адресов.
- Проверка работоспособности узла. В случае, если узел перестает отвечать на запросы, этот контроллер проверяет с помощью API вашего облачного провайдера, был ли сервер деактивирован / удален / прекращен. Если узел был удален из облака, контроллер удаляет объект узла из вашего Kubernetes кластера.
Некоторые облачные провайдеры реализуют его разделение на контроллер узла и отдельный контроллер жизненного цикла узла.
Контроллер маршрута
Контроллер маршрута отвечает за соответствующую настройку маршрутов в облаке, чтобы контейнеры на разных узлах кластера Kubernetes могли взаимодействовать друг с другом.
В зависимости от облачного провайдера, контроллер маршрута способен также выделять блоки IP-адресов для сети Pod-ов.
Контроллер сервисов
Сервисы интегрируются с компонентами облачной инфраструктуры, такими как управляемые балансировщики нагрузки, IP-адреса, фильтрация сетевых пакетов и проверка работоспособности целевых объектов. Контроллер сервисов взаимодействует с API вашего облачного провайдера для настройки требуемых балансировщиков нагрузки и других компонентов инфраструктуры, когда вы объявляете ресурсы сервисов.
Авторизация
В этом разделе разбирается доступ к различным объектам API, который нужен облачным контроллерам для выполнения своих операций.
Контроллер узла
Контроллер узла работает только с объектом узла. Он требует полного доступа на чтение и изменение объектов узла.
v1/Node:
- Get
- List
- Create
- Update
- Patch
- Watch
- Delete
Контроллер маршрута
Контроллер маршрута прослушивает создание объектов узла и соответствующим образом настраивает маршруты. Для этого требуется получить доступ к объектам узла.
v1/Node:
Контроллер сервисов
Контроллер сервисов прослушивает события Create, Update и Delete объектов служб, а затем соответствующим образом настраивает конечные точки для соответствующих сервисов.
Для доступа к сервисам требуется доступ к событиям List и Watch. Для обновления сервисов требуется доступ к событиям Patch и Update.
Чтобы настроить ресурсы конечных точек для сервисов, требуется доступ к событиям Create, List, Get, Watch и Update.
v1/Service:
- List
- Get
- Watch
- Patch
- Update
Другие
Реализация ядра диспетчера облачных контроллеров требует доступ для создания объектов событий, а для обеспечения безопасной работы требуется доступ к созданию сервисных учетных записей (ServiceAccounts).
v1/Event:
v1/ServiceAccount:
RBAC ClusterRole для диспетчера облачных контроллеров выглядит так:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
Что дальше
Администрирование диспетчера облачных контроллеров
содержит инструкции по запуску и управлению диспетчером облачных контроллеров.
Хотите знать, как реализовать свой собственный диспетчер облачных контроллеров или расширить проект?
Диспетчер облачных контроллеров использует интерфейсы Go, которые позволяют реализовать подключение из любого облака. В частности, он использует интерфейс CloudProvider, который определен в cloud.go из kubernetes/cloud-provider.
Реализация общих контроллеров, описанных в этом документе (Node, Route, и Service), а также некоторые другие вспомогательные конструкции, вместе с общим интерфейсом облачного провайдера являются частью ядра Kubernetes. Особые реализации для облачных провайдеров находятся вне ядра Kubernetes и реализуют интерфейс CloudProvider.
Дополнительные сведения о разработке плагинов см. в разделе Разработка диспетчера облачных контроллеров.
2.5 - Container Runtime Interface (CRI)
Интерфейс CRI позволяет kubelet работать с различными исполняемыми средами контейнеров без необходимости перекомпиляции компонентов кластера.
Исполняемая среда контейнеров должна работать на всех узлах кластера, чтобы kubelet мог запускать Pod'ы и их контейнеры.
Интерфейс Kubernetes Container Runtime Interface (CRI) container Runtime Interface (CRI) — это основной протокол для связи между kubelet'ом и исполняемой средой контейнеров.
Интерфейс Kubernetes Container Runtime Interface (CRI) задает основной gRPC-протокол, на базе которого осуществляется коммуникация между компонентами кластера: kubelet'ом и исполняемой средой.
API
СТАТУС ФИЧИ: Kubernetes v1.23 [stable]
Kubelet выступает в роли клиента при подключении к исполняемой среде через gRPC. Конечные точки ImageService и RuntimeService должны быть доступны в исполняемой среде контейнеров; в kubelet их можно настроить независимо с помощью флагов командной строки --image-service-endpoint и --container-runtime-endpoint.
В Kubernetes v1.30 kubelet предпочитает использовать CRI v1. Если исполняемая среда контейнера не поддерживает v1 CRI, kubelet пытается перейти на более старую поддерживаемую версию. В версии v1.30 kubelet также может работать с CRI v1alpha2, но эта версия считается устаревшей. Если согласовать поддерживаемую версию CRI не удается, узел не регистрируется.
Обновление
При обновлении Kubernetes kubelet автоматически выбирает последнюю версию CRI при перезапуске компонента. Если это не удается, происходит откат, как описано выше. Если повторный вызов gRPC произошел из-за обновления исполняемой среды контейнера, последняя также должна поддерживать первоначально выбранную версию, иначе повторный вызов будет неудачным. Для этого требуется перезапуск kubelet'а.
Что дальше
2.6 - Сборщик мусора
Сборщик мусора - это собирательный термин для различных механизмов? используемых Kubernetes для очистки ресурсов кластера. Это позволить очистить ресурсы, такие как:
Владельцы и зависимости
Многие объекты в Kubernetes ссылаются друг на друга через ссылки владельцев.
Ссылки владельцев сообщают плоскости управления какие объекты зависят от других.
Kubernetes использует ссылки владельцев, чтобы предоставить плоскости управления и другим API
клиентам, возможность очистить связанные ресурсы перед удалением объекта. В большинстве случаев, Kubernetes автоматический управляет ссылками владельцев.
Владелец отличается от меток и селекторов
которые также используют некоторые ресурсы. Например, рассмотрим
Службу которая создает объект
EndpointSlice. Служба использует метки чтобы позволить плоскости управления определить какие EndpointSlice объекты используются для этой службы. В дополнение
к меткам, каждый EndpointSlice управляет ои имени службы, имеет
ссылку владельца. Ссылки владельцев помогают различным частям Kubernetes избегать
вмешательства в объекты, которые они не контролируют.
Примечание:
Ссылки на владельцев перекрестных пространств имен запрещены по дизайну.
Зависимости пространства имен могут указывать на область действия кластера или владельцев пространства имен.
Владелец пространства имен должен быть в том же пространстве имен, что и зависимости.
Если это не возможно, ссылка владельца считается отсутствующей и зависимый объект подлежит удалению, как только будет проверено отсутствие всех владельцев.
Зависимости области действия кластер может указывать только владельцев области действия кластера.
В версии v1.20+, если зависимость с областью действия кластера указывает на пространство имен как владелец,
тогда он рассматривается как имеющий неразрешимую ссылку на владельца и не может быть обработан сборщиком мусора.
В версии v1.20+, если сборщик мусора обнаружит недопустимое перекрестное пространство имен ownerReference,
или зависящие от области действия кластера ownerReference ссылка на тип пространства имен, предупреждающее событие с причиной OwnerRefInvalidNamespace и involvedObject сообщающее о недействительной зависимости.
Вы можете проверить наличие такого рода событий, выполнив kubectl get events -A --field-selector=reason=OwnerRefInvalidNamespace.
Каскадное удаление
Kubernetes проверяет и удаляет объекты, на которые больше нет ссылок владельцев, так же как и pod-ов, оставленных после удаления ReplicaSet. Когда Вы удаляете объект, вы можете контролировать автоматический ли Kubernetes удаляет зависимые объекты автоматически в процессе вызова каскадного удаления. Существует два типа каскадного удаления, а именно:
- Каскадное удаление Foreground
- Каскадное удаление Background
Вы так же можете управлять как и когда сборщик мусора удаляет ресурсы, на которые ссылаются владельцы с помощью Kubernetes finalizers.
Каскадное удаление Foreground
В Каскадном удалении Foreground, объект владельца, который вы удаляете, сначала переходить в состояние в процессе удаления. В этом состоянии с объектом-владельцем происходить следующее:
- Сервер Kubernetes API устанавливает полю объекта
metadata.deletionTimestamp
время, когда объект был помечен для удаления.
- Сервер Kubernetes API так же устанавливает метку
metadata.finalizersдля поля
foregroundDeletion.
- Объект остается видимым благодаря Kubernetes API пока процесс удаления не завершиться
После того как владелец объекта переходит в состояние прогресса удаления, контроллер удаляет зависимые объекты. После удаления всех зависимых объектов, контроллер удаляет объект владельца. На этом этапе, объект больше не отображается в Kubernetes API.
Во время каскадного удаления foreground, единственным зависимым, которые блокируют удаления владельца, являются те, у кого имеется поле ownerReference.blockOwnerDeletion=true.
Чтобы узнать больше. Смотрите Использование каскадного удаления foreground.
Каскадное удаление Background
В каскадном удалении background, сервер Kubernetes API немедленно удаляет владельца объекта, а контроллер очищает зависимые объекты в фоновом режиме. По умолчанию, Kubernetes использует каскадное удаление background, если вы в ручную не используете удаление foreground или не решите отключить зависимые объекты.
Чтобы узнать больше. Смотрите Использование каскадного удаления background.
Осиротевшие зависимости
Когда Kubernetes удаляет владельца объекта, оставшиеся зависимости называются осиротевшими объектами. По умолчанию, Kubernetes удаляет зависимые объекты. Чтобы узнать, как переопределить это поведение смотрите Удаление объектов владельца и осиротевших зависимостей.
Сбор мусора из неиспользуемых контейнеров и образов
kubelet выполняет сбор мусора для неиспользуемых образов каждые пять минут и для неиспользуемых контейнеров каждую минуту. Вам следует избегать использования внешних инструментов для сборки мусора, так как они могут
нарушить поведение kubelet и удалить контейнеры, которые должны существовать.
Чтобы настроить параметры для сборщика мусора для неиспользуемого контейнера и сборки мусора образа, подстройте
kubelet использую конфигурационный файл
и измените параметры, связанные со сборщиком мусора используя тип ресурса
KubeletConfiguration.
Жизненный цикл контейнерных образов Container image lifecycle
Kubernetes управляет жизненным циклом всех образов с помощью своего менеджера образов, которые являются частью kubelet, в сотрудничестве с cadvisor. При принятии решений о сборке мусора, kubelet учитывает следующие ограничения использования диска:
HighThresholdPercentLowThresholdPercent
Использование диска выше настроенного значения HighThresholdPercent запускает сборку мусора, которая удаляет образы в порядке основанном на последнем использовании, начиная с самого старого. Kubelet удаляет образы до тех пор, пока использование диска не достигнет значения LowThresholdPercent.
Сборщик мусора контейнерных образов
Kubelet собирает не используемые контейнеры на основе следующих переменных, которые вы можете определить:
MinAge: минимальный возраст, при котором kubelet может начать собирать мусор контейнеров. Отключить, установив значение 0.MaxPerPodContainer: максимальное количество неактивных контейнеров, которое может быть у каждой пары Pod-ов. Отключить, установив значение меньше чем 0.MaxContainers: максимальное количество не используемых контейнеров, которые могут быть в кластере. Отключить, установив значение меньше чем 0.
В дополнение к этим переменным, kubelet собирает неопознанные и удаленные контейнеры, обычно начиная с самого старого.
MaxPerPodContainer и MaxContainer могут потенциально конфликтовать друг с другом в ситуациях, когда требуется максимальное количество контейнеров в Pod-е (MaxPerPodContainer) выйдет за пределы допустимого общего количества глобальных не используемых контейнеров (MaxContainers). В этой ситуации kubelet регулирует MaxPodPerContainer для устранения конфликта. Наихудшим сценарием было бы понизить MaxPerPodContainer да 1 и изгнать самые старые контейнеры.
Кроме того, владельцы контейнеров в pod-е могут быть удалены, как только они становятся старше чем MinAge.
Примечание:
Kubelet собирает мусор только у контейнеров, которыми он управляет.
Настройка сборщик мусора
Вы можете настроить сборку мусора ресурсов, настроив параметры, специфичные для контроллеров, управляющих этими ресурсами. В последующих страницах показано, как настроить сборку мусора:
Что дальше
3 - Контейнеры
Технология упаковки приложения вместе с его runtime-зависимостями.
Каждый запускаемый контейнер воспроизводим; стандартизация благодаря включению зависимостей позволяет каждый раз получать одинаковое поведение при запуске.
Контейнеры абстрагируют приложения от базовой инфраструктуры хоста, упрощая развертывание в различных облачных средах или ОС.
Образы контейнеров
Образ контейнера – это готовый к запуску пакет программного обеспечения, содержащий все необходимое для запуска приложения: код, среду исполнения, прикладные и системные библиотеки, а также значения по умолчанию всех важных параметров.
Контейнер по определению неизменяем (immutable): код работающего контейнера невозможно поменять. Чтобы внести правки в контейнеризованное приложение, необходимо собрать новый образ, содержащий эти правки, а затем запустить контейнер на базе обновленного образа.
Исполняемые среды контейнеров
Иcполняемая среда контейнера — это программа, предназначенная для запуска контейнера в Kubernetes.
Kubernetes поддерживает различные среды для запуска контейнеров: Docker,
containerd, CRI-O,
и любые реализации Kubernetes CRI (Container Runtime
Interface).
Что дальше
3.1 - Образы
Образ контейнера содержит исполняемые данные приложения и всех его программных зависимостей. Образы контейнеров — это исполняемые пакеты программного обеспечения, способные автономно работать и дополненные конкретными предположениями о соответствующей среде исполнения.
Как правило, образ контейнера с приложением предварительно собирается и размещается в реестре, после чего его можно использовать в Pod'е.
На этой странице представлено общее описание концепции контейнерных образов.
Названия образов
Образам контейнеров обычно присваивается имя, намекающее на их функционал и цели, например, pause, example/mycontainer или kube-apiserver. Образы также могут включать имя хоста реестра, например, fictional.registry.example/imagename, и (в некоторых случаях) номер порта, например, fictional.registry.example:10443/imagename.
Если имя хоста реестра не указано, Kubernetes по умолчанию будет использовать публичный реестр Docker.
После имени образа можно добавить тег (как, например, в командах docker и podman). Теги помогают идентифицировать различные версии одной и той же линейки образов.
Теги образов могут состоять из строчных и прописных букв, цифр, знаков подчеркивания (_), точек (.) и дефисов (-).
Кроме того, существуют дополнительные правила размещения символов-разделителей (_, - и .) внутри тега.
Если тег не указан, Kubernetes по умолчанию использует тег latest.
Обновление образов
При первоначальном создании объекта типа Deployment, StatefulSet, Pod или другого объекта, включающего шаблон Pod'а, политика извлечения всех контейнеров в этом Pod'е будет по умолчанию установлена на IfNotPresent, если иное не указано явно. В рамках этой политики kubelet не извлекает образ, если тот уже присутствует в кэше.
Политика извлечения образов
Политика imagePullPolicy контейнера и тег образа определяют поведение kubelet'а при извлечении (загрузке) данного образа.
Вот список возможных значений imagePullPolicy и их влияние:
IfNotPresent- образ извлекается только в том случае, если он еще не доступен локально.
Always- каждый раз при запуске контейнера kubelet запрашивает дайджест образа в реестре образов контейнеров. Если полученный дайджест полностью совпадает с дайджестом кэшированного образа, kubelet использует кэшированный образ; иначе извлекается и используется образ с полученным дайждестом.
Never- kubelet не пытается скачать образ. Если образ уже присутствует локально, kubelet пытается запустить контейнер; в противном случае запуск завершается неудачей. Для получения более подробной информации обратитесь к разделу о предварительно извлеченных (pre-pulled) образах.
Благодаря семантике кэширования, лежащей в основе механизма поставки образов, даже imagePullPolicy: Always может быть вполне эффективной (при условии, что реестр надежно доступен). Исполняемая среда для контейнера может обнаружить, что слои образов уже имеются на узле и их не нужно скачивать еще раз.
Примечание:
Избегайте использования тега :latest при развертывании контейнеров в production, поскольку в этом случае не понятно, какая именно версия образа используется и на какую ее нужно откатить при необходимости.
Всегда указывайте содержательный тег, например v1.42.0.
Чтобы убедиться, что Pod всегда использует одну и ту же версию образа контейнера, можно указать дайджест образа вместо тега; для этого замените <image-name>:<tag> на <image-name>@<digest>
(например, image@sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2).
Изменение кода, к которому привязан некий тег, может привести к тому, что в Pod'ах окажется две версии кода — старая и новая. Дайджест образа однозначно идентифицирует конкретную версию образа, что гарантирует идентичность кода при запуске контейнера с заданным именем образа и дайджестом. Таким образом, изменение кода в реестре уже не может привести к смешению версий.
Существуют сторонние admission-контроллеры, которые модифицируют Pod'ы (и их шаблоны) при создании, из-за чего рабочая нагрузка определяется на основе дайджеста образа, а не тега. Это может быть полезно в случаях, когда необходимо убедиться, что вся рабочая нагрузка использует идентичный код независимо от изменений тегов в реестре.
Политика извлечения образов по умолчанию
Когда информация о новом Pod'е поступает на сервер API, кластер устанавливает поле imagePullPolicy в соответствии со следующими условиями:
imagePullPolicy автоматически присваивается значение Always, если поле imagePullPolicy не задано, а тег для образа контейнера имеет значение :latest;imagePullPolicy автоматически присваивается значение Always, если поле imagePullPolicy не задано, а тег для образа контейнера не указан;imagePullPolicy автоматически присваивается значение IfNotPresent, если поле imagePullPolicy не задано, а тег для образа контейнера имеет значение, отличное от :latest.
Примечание:
Значение imagePullPolicy контейнера всегда устанавливается при первом создании объекта и не обновляется при последующем изменении тега образа.
Например, если в Deployment'е используется образ с тегом, отличным от :latest, а потом он меняется на :latest, поле imagePullPolicy останется прежним (т.е. не будет изменено на Always). После первоначального создания любого объекта его политику извлечения можно изменить вручную.
Обязательное извлечение образов
Для принудительного извлечения образов можно сделать следующее:
- Установить
imagePullPolicy контейнера в Always;
- Не устанавливать
imagePullPolicy и использовать тег :latest для образа; Kubernetes автоматически поменяет политику на Always, получив информацию о Pod'е;
- Не устанавливать
imagePullPolicy и тег образа; Kubernetes автоматически применит политику Always, получив информацию о Pod'е;
- Включить admission-контроллер AlwaysPullImages.
ImagePullBackOff
При создании kubelet'ом контейнеров для Pod'а может возникнуть ситуация, когда контейнер пребывает в состоянии Waiting из-за ImagePullBackOff.
Статус ImagePullBackOff означает, что контейнер не может запуститься, поскольку у Kubernetes не получается извлечь его образ (например, из-за ошибки в имени или попытки извлечь образ из приватного репозитория без imagePullSecret). BackOff в названии статуса указывает на то, что Kubernetes будет продолжать попытки извлечь образ, постепенно увеличивая интервал между ними.
Так, интервал между попытками будет расти до тех пор, пока не достигнет установленного предела в 300 секунд (5 минут).
Мультиархитектурные образы с индексами
Помимо обычных исполняемых образов реестр контейнеров также может хранить так называемые индексы образов. Индекс образа содержит ссылки на различные манифесты образов, каждый из которых предназначен для определенной архитектуры. Идея здесь в том, чтобы любой пользователь мог получить образ, оптимизированный под конкретную архитектуру, используя его унифицированное, общее для всех архитектур имя (например, pause, example/mycontainer, kube-apiserver).
Сам Kubernetes обычно добавляет суффикс -$(ARCH) к имени образа. Для обратной совместимости также рекомендуется генерировать образы с суффиксами в названиях. Например, универсальный образ pause, содержащий манифест для всех архитектур, рекомендуется дополнить образом pause-amd64 для обратной совместимости со старыми конфигурациями или YAML-файлами, в которых могут быть жестко прописаны образы с суффиксами.
Работа с приватным реестром
Для чтения образов из приватных реестров могут потребоваться соответствующие ключи.
Доступ к таким реестрам можно получить следующими способами:
- Аутентификация на уровне узлов:
- все Pod'ы имеют доступ ко всем настроенным приватным реестрам;
- требуется конфигурация узлов администратором кластера;
- Предварительно извлеченные образы:
- все Pod'ы могут использовать любые образы, кэшированные на узле;
- для настройки требуется root-доступ ко всем узлам;
- imagePullSecrets на уровне Pod'а:
- доступ к реестру получают только Pod'ы с ключами;
- Специализированные расширения от вендора/пользователя:
- в кастомных конфигурациях могут существовать специализированные механизмы аутентификации узлов в реестре контейнеров, реализованные самим пользователем или поставщиком облачных услуг.
Ниже мы подробнее остановимся на каждом из вариантов.
Аутентификация на уровне узлов
Конкретные инструкции по настройке учетных данных зависят от среды исполнения контейнера и реестра. Для получения наиболее подробной информации следует обратиться к документации используемого решения.
Пример настройки частного реестра образов контейнеров приводится в упражнении Извлекаем образ из частного реестра. В нем используется частный реестр в Docker Hub.
Интерпретация config.json
Интерпретация config.json отличается в оригинальной Docker-реализации и в Kubernetes. В Docker ключи auths могут указывать только корневые URL, в то время как Kubernetes позволяет использовать URL с подстановками (globbing) и пути с префиксами. То есть config.json, подобный этому, вполне допустим:
{
"auths": {
"*my-registry.io/images": {
"auth": "…"
}
}
}
Корневой URL (*my-registry.io) сопоставляется с помощью следующего синтаксиса:
pattern:
{ term }
term:
'*' соответствует любой последовательности символов, не являющихся разделителями
'?' соответствует любому одиночному символу, не являющемуся разделителем
'[' [ '^' ] { диапазон символов } ']'
класс символов (не может быть пустым)
c соответствует символу c (c != '*', '?', '\\', '[')
'\\' c соответствует символу c
диапазон символов:
c соответствует символу c (c != '\\', '-', ']')
'\\' c соответствует символу c
lo '-' hi соответствует символу c при lo <= c <= hi
Учетные данные теперь будут передаваться в CRI-совместимую исполняемую среду для контейнеров для каждого действительного шаблона. Ниже приведены примеры имен образов, удовлетворяющие требованиям к паттерну:
my-registry.io/imagesmy-registry.io/images/my-imagemy-registry.io/images/another-imagesub.my-registry.io/images/my-imagea.sub.my-registry.io/images/my-image
kubelet последовательно извлекает образы для каждой обнаруженной учетной записи. Это означает, что config.json может содержать сразу несколько записей:
{
"auths": {
"my-registry.io/images": {
"auth": "…"
},
"my-registry.io/images/subpath": {
"auth": "…"
}
}
}
К примеру, если необходимо извлечь образ my-registry.io/images/subpath/my-image, kubelet будет пытаться загрузить его из второго источника, если первый не работает.
Предварительно извлеченные образы
Примечание:
Этот подход применим, если имеется доступ к конфигурации узлов. Он не будет надежно работать, если поставщик облачных услуг управляет узлами и автоматически заменяет их.
По умолчанию kubelet пытается извлечь каждый образ из указанного реестра. Однако если параметр imagePullPolicy контейнера установлен на IfNotPresent или Never, используется локальный образ (преимущественно или исключительно, соответственно).
Чтобы использовать предварительно извлеченные образы (и не связываться с аутентификацией для доступа к реестру), необходимо убедиться, что они идентичны на всех узлах кластера.
Предварительная загрузка образов позволяет увеличить скорость работы и является альтернативой аутентификации в приватном реестре.
При этом у всех Pod'ов будет доступ на чтение всех предварительно извлеченных образов.
Задаем imagePullSecrets на уровне Pod'а
Примечание:
Это рекомендуемый подход для запуска контейнеров на основе образов в приватных реестрах.
Kubernetes поддерживает указание ключей реестра образов на уровне Pod'а.
Создаем Secret с помощью конфигурационного файла Docker
Для аутентификации в реестре необходимо знать имя пользователя, пароль, имя хоста реестра и адрес электронной почты клиента.
Выполните следующую команду, подставив соответствующие значения вместо параметров, выделенных заглавными буквами:
kubectl create secret docker-registry <name> --docker-server=DOCKER_REGISTRY_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAIL
При наличии файла учетных данных Docker можно импортировать их как Secret'ы Kubernetes вместо команды, приведенной выше.
В разделе Создание Secret'а на основе существующих учетных данных Docker рассказывается, как это можно сделать.
Это особенно удобно в случае нескольких приватных реестров контейнеров, так как kubectl create secret docker-registry создает Secret, который работает только с одним приватным реестром.
Примечание:
Pod'ы могут работать только с Secret'ами в собственном пространстве имен, поэтому данный процесс необходимо повторить для каждого пространства имен.
Ссылаемся на imagePullSecrets в Pod'е
Теперь можно создавать Pod'ы, ссылающиеся на данный Secret, добавив раздел imagePullSecrets в манифест Pod'а.
Например:
cat <<EOF > pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo
namespace: awesomeapps
spec:
containers:
- name: foo
image: janedoe/awesomeapp:v1
imagePullSecrets:
- name: myregistrykey
EOF
cat <<EOF >> ./kustomization.yaml
resources:
- pod.yaml
EOF
Это необходимо проделать для каждого Pod'а, работающего с приватным репозиторием.
Процесс можно автоматизировать, задав imagePullSecrets в ресурсе ServiceAccount.
Подробные инструкции см. в разделе Добавить ImagePullSecrets в Service Account.
Этот подход можно использовать совместно с файлами .docker/config.json, определяемыми для каждого узла. Учетные данные будут объединены.
Примеры использования
Существует ряд решений для настройки приватных реестров. Вот некоторые распространенные случаи использования и рекомендуемые решения:
- Кластер, работающий только со свободными (например, Open Source) образами. Необходимость скрывать образы отсутствует.
- Используйте общедоступные образы из Docker Hub;
- Настройка не требуется;
- Некоторые облачные провайдеры автоматически кэшируют или зеркалируют публичные образы, что повышает доступность и сокращает время их извлечения.
- В кластере используются закрытые образы. Они должны быть скрыты для всех за пределами компании, но доступны для всех пользователей кластера.
- Используйте приватный репозиторий;
- Может потребоваться ручная настройка на узлах, которым необходим доступ к частному репозиторию;
- В качестве альтернативы можно завести внутренний приватный реестр с доступом на чтение, скрыв его за сетевым экраном;
- Настройка Kubernetes не требуется;
- Используйте сервис для работы с образами, контролирующий доступ к ним;
- Этот подход лучше работает с автомасштабированием кластера, нежели ручная настройка узлов;
- Если изменение конфигурации узлов в кластере затруднено, можно использовать imagePullSecrets.
- Кластер с несвободными образами, некоторые из которых требуют более строгого контроля доступа.
- Убедитесь, что AlwaysPullImages admission-контроллер включен. В противном случае у всех Pod'ов потенциально будет доступ ко всем образам;
- Переместите конфиденциальные данные в Secret вместо того, чтобы упаковывать их в образ.
- Кластер категории multi-tenant (многопользовательский), где каждому пользователю требуется собственный приватный репозиторий.
- Убедитесь, что admission-контроллер AlwaysPullImages включен. В противном случае у всех Pod'ов всех пользователей потенциально будет доступ ко всем образам;
- Создайте приватный реестр с обязательной авторизацией;
- Сгенерируйте учетные данные для доступа к реестру для каждого пользователя, поместите их в Secret и добавьте его в пространство имен каждого пользователя;
- Каждый пользователь должен добавить свой Secret в imagePullSecrets каждого пространства имен.
Если нужен доступ к нескольким реестрам, можно создать по Secret'у для каждого реестра.
Что дальше
3.2 - RuntimeClass
СТАТУС ФИЧИ: Kubernetes v1.20 [stable]
На этой странице описывается ресурс RuntimeClass и механизм выбора исполняемой среды.
RuntimeClass позволяет выбрать конфигурацию исполняемой среды для контейнеров. Используется для настройки исполняемой среды в Pod'е.
Мотивация
Разным Pod'ам можно назначать различные RuntimeClass'ы, соблюдая баланс между производительностью и безопасностью. Например, если часть рабочей нагрузки требует высокого уровня информационной безопасности, связанные с ней Pod'ы можно запланировать так, чтобы они использовали исполняемую среду для контейнеров на основе аппаратной виртуализации. Это обеспечит повышенную изоляцию, но потребует дополнительных издержек.
Также можно использовать RuntimeClass для запуска различных Pod'ов с одинаковой исполняемой средой, но с разными настройками.
Подготовка
- Настройте реализацию CRI на узлах (зависит от используемой исполняемой среды);
- Создайте соответствующие ресурсы RuntimeClass.
1. Настройте реализацию CRI на узлах
Конфигурации, доступные с помощью RuntimeClass, зависят от реализации Container Runtime Interface (CRI). Для настройки определенной реализации CRI обратитесь к соответствующему разделу документации (ниже).
Примечание:
По умолчанию RuntimeClass предполагает однородную конфигурацию узлов в кластере (то есть все узлы настроены одинаково в плане исполняемой среды для контейнеров). Для гетерогенных конфигураций узлов см. раздел
Scheduling ниже.
Каждой конфигурации соответствует обработчик, на который ссылается RuntimeClass. Имя обработчика должно соответствовать синтаксису для меток DNS.
2. Создайте соответствующие ресурсы RuntimeClass
К каждой конфигурации, настроенной на шаге 1, должно быть привязано имя обработчика (handler), которое ее идентифицирует. Для каждого обработчика создайте соответствующий объект RuntimeClass.
На данный момент у ресурса RuntimeClass есть только 2 значимых поля: имя RuntimeClass (metadata.name) и обработчик (handler). Определение объекта выглядит следующим образом:
# RuntimeClass определен в API-группе node.k8s.io
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
# Имя, которое ссылается на RuntimeClass
# ресурс RuntimeClass не включается в пространство имен
name: myclass
# Имя соответствующей конфигурации CRI
handler: myconfiguration
Имя объекта RuntimeClass должно удовлетворять синтаксису для поддоменных имен DNS.
Примечание:
Рекомендуется ограничить доступ к операциям записи RuntimeClass (create/update/patch/delete) администратором кластера. Обычно это сделано по умолчанию. Более подробную информацию см. в разделе
Общая информация об авторизации.
Использование
После того как RuntimeClasses настроены для кластера, использовать их очень просто. Достаточно указать runtimeClassName в спецификации Pod'а. Например:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
runtimeClassName: myclass
# ...
kubelet будет использовать указанный RuntimeClass для запуска этого Pod'а. Если указанный RuntimeClass не существует или CRI не может запустить соответствующий обработчик, Pod войдет в фазу завершения работы Failed. Полное сообщение об ошибке можно получить, обратившись к соответствующему событию (event).
Если имя runtimeClassName не указано, будет использоваться RuntimeHandler по умолчанию (что эквивалентно поведению, когда функция RuntimeClass отключена).
Настройка CRI
Для получения более подробной информации о настройке исполняемых сред CRI обратитесь к разделу Установка CRI.
Обработчики исполняемой среды настраиваются в конфигурации containerd в файле /etc/containerd/config.toml. Допустимые обработчики прописываются в разделе runtimes:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.${HANDLER_NAME}]
Дополнительная информация доступна в документации по конфигурации containerd.
Обработчики исполняемой среды настраиваются в файле конфигурации CRI-O (/etc/crio/crio.conf). Допустимые обработчики прописываются в таблице crio.runtime:
[crio.runtime.runtimes.${HANDLER_NAME}]
runtime_path = "${PATH_TO_BINARY}"
Более подробную информацию см. в документации по конфигурации CRI-O.
Scheduling
СТАТУС ФИЧИ: Kubernetes v1.16 [beta]
Поле scheduling в RuntimeClass позволяет наложить определенные ограничения, гарантировав, что Pod'ы с определенным RuntimeClass'ом будут планироваться на узлы, которые его поддерживают. Если параметр scheduling не установлен, предполагается, что данный RuntimeClass поддерживается всеми узлами.
Чтобы гарантировать, что Pod'ы попадают на узлы, поддерживающие определенный RuntimeClass, эти узлы должны быть связаны общей меткой, которая затем выбирается полем runtimeclass.scheduling.nodeSelector. nodeSelector RuntimeClass'а объединяется с nodeSelector'ом admission-контроллера, на выходе образуя пересечение подмножеств узлов, выбранных каждым из селекторов. Если возникает конфликт, Pod отклоняется.
Если поддерживаемые узлы объединены неким taint'ом, чтобы предотвратить запуск на них Pod'ов с другими RuntimeClass'ами, можно к нужному RuntimeClass'у добавить tolerations. Как и в случае с nodeSelector, tolerations объединяются с tolerations Pod'а admission-контроллера, фактически образуя объединение двух подмножеств узлов с соответствующими tolerations.
Чтобы узнать больше о настройке селектора узлов и tolerations, см. раздел Назначаем Pod'ы на узлы.
Pod Overhead
СТАТУС ФИЧИ: Kubernetes v1.24 [stable]
Можно указать overhead-ресурсы, необходимые для работы Pod'а. Это позволит кластеру (и планировщику) учитывать их при принятии решений о Pod'ах и управлении ресурсами.
В RuntimeClass дополнительные ресурсы, потребляемые Pod'ом, указываются в поле overhead. С помощью этого поля можно указать ресурсы, необходимые Pod'ам с данным RuntimeClass'ом, и гарантировать их учет в Kubernetes.
Что дальше
3.3 - Контейнерное окружение
На этой странице описаны ресурсы, доступные для контейнеров в соответствующем окружении.
Контейнерное окружение
Контейнерное окружение Kubernetes предоставляет контейнерам несколько важных ресурсов:
- Файловую систему, сочетающую в себе образ и один или несколько томов.
- Информацию о самом контейнере.
- Информацию о других объектах в кластере.
Информация о контейнере
Hostname контейнера — имя Pod'а, в котором запущен контейнер. Его можно получить с помощью команды hostname или функции gethostname в libc.
Имя Pod'а и его пространство имен можно получить из переменных окружения в Downward API.
Контейнеру также доступны переменные окружения из определения Pod'а, заданные пользователем, а также любые переменные окружения, указанные статически в образе контейнера.
Информация о кластере
Список всех сервисов, активных на момент создания контейнера, доступен этому контейнеру в виде переменных окружения. Этот список ограничен сервисами в пространстве имен, которому принадлежит Pod с данным контейнером, а также сервисами управляющего слоя Kubernetes.
Для сервиса foo, связанного с контейнером bar, определены следующие переменные:
FOO_SERVICE_HOST=<хост, на котором запущен сервис>
FOO_SERVICE_PORT=<порт, на котором запущен сервис>
Сервисы получают выделенные IP-адреса и доступны для контейнера через DNS, если включен аддон DNS.
Что дальше
3.4 - Хуки жизненного цикла контейнеров
На этой странице описывается, как контейнеры под управлением kubelet могут использовать механизм хуков для запуска кода, инициированного событиями во время своего жизненного цикла.
Общая информация
Многие платформы для разработки предлагают хуки жизненного цикла компонентов (например, Angular). Kubernetes имеет аналогичный механизм. Хуки позволяют контейнерам оставаться в курсе событий своего жизненного цикла и запускать запакованный в обработчик код при наступлении определенных событий, приводящих к вызову хука.
Хуки контейнеров
В распоряжении контейнеров имеются два хука:
PostStart
Выполняется сразу после создания контейнера. Однако нет гарантии, что хук закончит работу до ENTRYPOINT контейнера. Параметры обработчику не передаются.
PreStop
Вызывается непосредственно перед завершением работы контейнера в результате запроса API или иного события (например, неудачное завершение теста liveness/startup, вытеснение, борьба за ресурсы и т.п.). Вызов хука PreStop завершается неудачно, если контейнер уже находится в прерванном (terminated) или завершенном (completed) состоянии. Кроме того, работа хука должна закончиться до того, как будет отправлен сигнал TERM для остановки контейнера. Отсчет задержки перед принудительной остановкой Pod'а (grace-период) начинается до вызова хука PreStop. Таким образом, независимо от результата выполнения обработчика, контейнер будет остановлен в течение этого grace-периода. Параметры обработчику не передаются.
Более подробное описание поведения при прекращении работы можно найти в разделе Прекращение работы Pod'ов.
Реализации обработчиков хуков
Чтобы контейнер имел доступ к хуку, необходимо реализовать и зарегистрировать обработчик для этого хука. Существует два типа обработчиков хуков, доступных для контейнеров:
- Exec — Выполняет определенную команду, например,
pre-stop.sh, внутри cgroups и пространств имен контейнера. Ресурсы, потребляемые командой, прибавляются к ресурсам, потребляемым контейнером.
- HTTP — Выполняет HTTP-запрос к определенной конечной точке контейнера.
Выполнение обработчиков хуков
При вызове хука, привязанного к жизненному циклу контейнера, система управления Kubernetes выполняет обработчик в соответствии с типом хука: kubelet отвечает за httpGet и tcpSocket, а exec выполняется в контейнере.
Вызовы обработчиков хуков синхронны в контексте Pod'а, содержащего контейнер. Это означает, что в случае PostStart-хука ENTRYPOINT контейнера и хук запускаются асинхронно. При этом если хук выполняется слишком долго или зависает, контейнер не может достичь состояния Running.
Хуки PreStop не запускаются асинхронно с сигналом на остановку контейнера; хук должен завершить свою работу до отправки сигнала TERM. Если хук PreStop зависнет во время выполнения, Pod будет пребывать в состоянии Terminating до истечения периода terminationGracePeriodSeconds, после чего Kubernetes "убьет" его. Этот grace-период включает как время, которое требуется для выполнения хука PreStop, так и время, необходимое для нормальной остановки контейнера. Например, если terminationGracePeriodSeconds равен 60, работа хука занимает 55 секунд, а контейнеру требуется 10 секунд для нормальной остановки после получения сигнала, то контейнер будет "убит" до того, как сможет нормально завершить свою работу, поскольку terminationGracePeriodSeconds меньше, чем суммарное время (55+10), необходимое для работы хука и остановки контейнера.
Если любой из хуков postStart / preStop завершается неудачей, Kubernetes "убивает" контейнер.
Поэтому обработчики для хуков должны быть максимально простыми. Однако бывают случаи, когда применение "тяжелых" команд оправдано – например, при сохранении состояния перед остановкой контейнера.
Гарантии поставки хука
Хук должен выполниться хотя бы один раз. Это означает, что он может вызываться неоднократно для любого события вроде PostStart или PreStop. Задача по правильной обработке подобных вызовов возложена на сам хук.
Как правило, поставка хука выполняется однократно. Если, например, приемник HTTP-хука не работает и не может принимать трафик, повторная попытка отправки не предпринимается. В редких случаях может происходить двойная поставка. Например, если kubelet перезапустится в процессе доставки хука, тот может быть отправлен повторно.
Отладка обработчиков хуков
Логи обработчиков хуков не отображаются в событиях Pod'а. В случае сбоя обработчика тот транслирует событие. Для PostStart это событие FailedPostStartHook, для PreStop — событие FailedPreStopHook. Чтобы самостоятельно сгенерировать событие FailedPreStopHook, в манифесте lifecycle-events.yaml замените команду для postStart на что-то заведомо невыполнимое (badcommand) и примените его. Если теперь выполнить команду kubectl describe pod lifecycle-demo, вы увидите следующее:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7s default-scheduler Successfully assigned default/lifecycle-demo to ip-XXX-XXX-XX-XX.us-east-2...
Normal Pulled 6s kubelet Successfully pulled image "nginx" in 229.604315ms
Normal Pulling 4s (x2 over 6s) kubelet Pulling image "nginx"
Normal Created 4s (x2 over 5s) kubelet Created container lifecycle-demo-container
Normal Started 4s (x2 over 5s) kubelet Started container lifecycle-demo-container
Warning FailedPostStartHook 4s (x2 over 5s) kubelet Exec lifecycle hook ([badcommand]) for Container "lifecycle-demo-container" in Pod "lifecycle-demo_default(30229739-9651-4e5a-9a32-a8f1688862db)" failed - error: command 'badcommand' exited with 126: , message: "OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: exec: \"badcommand\": executable file not found in $PATH: unknown\r\n"
Normal Killing 4s (x2 over 5s) kubelet FailedPostStartHook
Normal Pulled 4s kubelet Successfully pulled image "nginx" in 215.66395ms
Warning BackOff 2s (x2 over 3s) kubelet Back-off restarting failed container
Что дальше
4 - Рабочие нагрузки
Поймите под, самый маленький развертываемый вычислительный объект в Kubernetes, и абстракции более высокого уровня, которые помогут вам их запускать.
Рабочая нагрузка — это приложение, работающее в Kubernetes.
Независимо от того, представляет ли ваша рабочая нагрузка один компонент
или несколько, которые работают вместе, в Kubernetes вы
запускаете ее внутри набора подов.
В Kubernetes под представляет собой набор работающих
контейнеров в кластере.
Поды Kubernetes имеют определенный жизненный цикл.
Например, если у вас запущен под в кластере, то критическая ошибка на
узле, где этот модуль работает,
означает, что все поды на этом узле выходят из строя. Kubernetes считает
этот уровень сбоя безвозвратным: потребуется создать новый под для восстановления,
даже если узел позже станет работоспособным.
Однако, чтобы значительно облегчить жизнь, не нужно
непосредственно контролировать каждый под. Вместо этого можно использовать
ресурсы рабочей нагрузки, которые управляют набором подов за вас.
Эти ресурсы настраивают контроллеры,
которые обеспечивают запуск нужного количества модулей
нужного типа в соответствии с указанным вами состоянием.
Kubernetes предоставляет несколько встроенных ресурсов для рабочих нагрузок:
- Деплоймент (Deployment) и ReplicaSet
(замена устаревшего ресурса
ReplicationController).
Deployment хорошо подходит для управления неизменными (stateless) приложениями
в кластере, то есть для случаев, когда любой под
в деплойменте не содержит изменяемых данных
и может быть заменен при необходимости.
- StatefulSet позволяет запускать один или несколько
связанных подов, которые как-то отслеживают состояние (являются stateful). Например, если ваше
приложение записывает постоянные данные, вы можете использовать StatefulSet,
который сопоставляет каждый под с PersistentVolume.
Ваш код, работающий в подах этого StatefulSet, может
копировать данные в другие поды в том же StatefulSet,
чтобы повысить общую отказоустойчивость.
- DaemonSet создает поды, которые
предоставляют инструменты, которые доступны локально для узлов.
Каждый раз, когда вы добавляете в кластер узел,
соответствующий спецификации DaemonSet,
слой управления (control plane) планирует (т.е. запускает) под с этим DaemonSet
на новом узле. Каждый под в DaemonSet выполняет работу,
аналогичную работе системного демона на классическом сервере Unix/POSIX.
DaemonSet может иметь основополагающее значение для работы вашего кластера,
например, в случае плагина для запуска сети кластера (cluster networking).
Этот ресурс может помочь управлять узлом
или предоставить дополнительные возможности
для используемой контейнерной платформы.
- Job и
CronJob предоставляют различные
способы запуска задач, которые выполняются до своего завершения, а затем останавливаются.
Job используется для задачи,
которая выполняется только один раз. Вы можете
использовать CronJob для запуска этого же задания
несколько раз по расписанию.
В экосистеме вокруг проекта Kubernetes можно найти сторонние ресурсы для
рабочих нагрузок, которые предоставляют дополнительные функции. Используя
custom resource definition,
вы можете добавить сторонний ресурс рабочей нагрузки, если нужно определенное
поведение, не являющееся частью стандартного Kubernetes. Например, если вы хотите
запустить группу подов для своего приложения, но хотите свернуть работу в случае,
когда не все поды доступны (возможно, для распределенной задачи с высокой пропускной способностью),
можно реализовать или установить расширение, которое предоставляет эту функцию.
Что дальше
В дополнение к информации о каждом виде API для управления рабочей нагрузкой вы можете прочитать,
как выполнять конкретные задачи:
Чтобы узнать о механизмах отделения кода от конфигурации в Kubernetes, посетите
раздел Configuration.
Есть два вспомогательных концепта, которые дают представление о том,
как Kubernetes управляет подами для приложений:
После запуска вашего приложения можно сделать его доступным в интернете
с помощью Service или, только в случае веб-приложения,
используя Ingress.
4.1 - Ресурсы рабочей нагрузки
Kubernetes предоставляет несколько встроенных API для декларативного управления
рабочими нагрузками
и их компонентами.
В конечном счете, приложения работают в качестве контейнеров внутри
подов, однако управление каждым подом по отдельности требует больших усилий.
Например, если под выходит из строя, вам, вероятно, надо будет
запустить новый под, чтобы заменить его. Kubernetes может сделать это за вас.
С помощью Kubernetes API можно создавать
объект рабочей нагрузки на более высоком уровне абстракции, чем под, а затем уже слой управления Kubernetes
будет автоматически управлять подами, руководствуясь спецификацией этого объекта.
Встроенные API для управления рабочими нагрузками:
Деплоймент (Deployment) (и, косвенно, ReplicaSet) — это наиболее распространенный способ запуска приложения в кластере.
Deployment хорошо подходит для управления неизменной (stateless) рабочей нагрузкой в кластере, где
любой под в деплойменте не содержит изменяемых данных и может быть заменен при необходимости
(Deployments — замена устаревшего ресурса
ReplicationController API).
StatefulSet позволяет управлять одним или несколькими подами,
в которых работает одно и то же приложение, для случаев, когда все эти поды требуют четкой идентичности (т.е. являются stateful).
Это отличается от деплоймента, в котором предполагается, что поды могут быть взаимозаменяемыми.
Наиболее распространенное использование StatefulSet — возможность установить
связь между его подами и их постоянным хранилищем (persistent storage).
Например, можно запустить StatefulSet, который связывает каждый под с PersistentVolume. Если один из подов в StatefulSet выходит из строя,
Kubernetes создает заменяющий под, подключенный к тому же PersistentVolume.
DaemonSet создает поды, которые предоставляют локальные инструменты для
узлов;
пример — драйвер, который позволяет контейнерам на узле получить доступ к системе хранения.
DaemonSet используется, когда драйвер или сервис должен быть запущен на определенном узле.
Каждый под в DaemonSet выполняет роль, аналогичную системному демону на классическом сервере Unix/POSIX.
DaemonSet может иметь основополагающее значение для работы кластера,
например, для плагина, позволяющего узлу получить доступ к
сети кластера.
Он может помочь управлять узлом или предоставить менее важные функции,
улучшающие работу используемой контейнерной платформы.
DaemonSet'ы (и их поды) можно запускать на каждом узле кластера или только на некоторых из них
(например, можно установить драйвер ускорителя GPU только на узлах, на которых установлен GPU).
Job и/или
CronJob используются, чтобы определять задачи,
которые выполняются по отдельному запуску до их завершения, а затем останавливаются. Job представляет собой разовую задачу,
тогда как CronJob повторяется по расписанию.
Другие темы в этом разделе:
4.1.1 - CronJob
CronJob запускает одноразовые задания по повторяющемуся расписанию
СТАТУС ФИЧИ: Kubernetes v1.21 [stable]
CronJob создает задания (Jobs), которые повторяются по расписанию.
CronJob предназначен для выполнения регулярных заданий по расписанию, таких как резервное копирование, создание отчетов,
и так далее. Один CronJob объект — это как одна строка файла crontab (cron table) в Unix-системе.
Он периодически запускает задание по заданному расписанию, составленному в формате формате
Cron.
У CronJob'a есть свои ограничения и особенности.
Например, при определенных обстоятельствах один CronJob может создавать несколько параллельных заданий. См. раздел Ограничения ниже.
Когда управляющий слой (control plane) создает новые задания и (косвенно) поды для CronJob'а, поле .metadata.name в CronJob
является частью основы для наименования этих подов. Имя CronJob должно быть действительным
значением поддомена DNS, но это может привести к неожиданным результатам для имен хостов подов. Для наилучшей совместимости имя должно соответствовать более строгим правилам
имен меток DNS.
Даже если имя является поддоменом DNS, оно не должно превышать 52 символов. Это связано с тем, что контроллер CronJob автоматически добавляет
11 символов к указанному вами имени и существует ограничение на то, что
длина имени задания (Job) не должна превышать 63 символа.
Пример
Этот пример манифеста CronJob печатает текущее время и сообщение hello каждую минуту:
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
(Выполнение автоматических заданий с помощью CronJob
более подробно рассматривает этот пример.)
Написание спецификации CronJob'a
Синтаксис расписания
Поле .spec.schedule является обязательным. Значение этого поля соответствует синтаксису Cron:
# ┌───────────── минута (0 - 59)
# │ ┌───────────── час (0 - 23)
# │ │ ┌───────────── день месяца (1 - 31)
# │ │ │ ┌───────────── месяц (1 - 12)
# │ │ │ │ ┌───────────── день недели (0 - 6) (воскресенье - суббота)
# │ │ │ │ │ ИЛИ sun, mon, tue, wed, thu, fri, sat
# │ │ │ │ │
# * * * * *
Например, 0 0 13 * 5 указывает, что задание должно запускаться каждую пятницу в полночь, а также 13 числа каждого месяца в полночь.
Формат также включает расширенные значения шагов "Vixie cron". Как объясняется в
инструкции для FreeBSD:
Значения шагов можно использовать в сочетании с диапазонами. Если после диапазона указать /<число>, то это означает
пропуск значения числа в диапазоне. Например, 0-23/2 можно использовать, чтобы указать выполнение команды
каждый второй час (альтернативой в стандарте V7 является
0,2,4,6,8,10,12,14,16,18,20,22). Шаги также разрешены после звездочки, так что если
нужно указать "каждые два часа", можно использовать */2.
Примечание:
Вопросительный знак (?) в расписании обозначает то же, что и звездочка *, то есть любое из доступных значений для данного поля.
Помимо стандартного синтаксиса можно также использовать макросы вроде @monthly:
| Запись |
Описание |
Эквивалент |
| @yearly (или @annually) |
Запускается один раз в год в полночь 1 января |
0 0 1 1 * |
| @monthly |
Запускается раз в месяц в полночь первого дня месяца |
0 0 1 * * |
| @weekly |
Запускается раз в неделю в полночь в воскресенье утром |
0 0 * * 0 |
| @daily (или @midnight) |
Запускается один раз в день в полночь |
0 0 * * * |
| @hourly |
Запускается раз в час в начале часа |
0 * * * * |
Для создания CronJob-расписания можно также использовать такие веб-инструменты, как crontab.guru.
Шаблон задания
Поле .spec.jobTemplate определяет шаблон для заданий, которые создает CronJob, и является обязательным.
Он имеет точно такой же вид, как и Job, за исключением того,
что является вложенным и не имеет полей apiVersion и kind.
Можно указать типичные метаданные для шаблонных заданий (Jobs), такие как
метки или
аннотации.
О том, как написать .spec для Job, см. Написание спецификации Job.
Дедлайн задержки начала задания
Поле .spec.startingDeadlineSeconds является необязательным.
В этом поле задается крайний срок (в целых секундах) для запуска задания (Job), если оно по какой-либо причине
не успевает к назначенному времени.
Если дедлайн пропущен, CronJob пропускает этот вызов задания (последующие выполнения по-прежнему запланированы).
Например, если задание резервного копирования выполняется дважды в день, можно разрешить ему
запускаться с опозданием до 8 часов, но не позже, поскольку резервная копия,
сделанная позже, не будет полезной: лучше дождаться следующего запуска по расписанию.
Задания, которые не успели выполниться в установленный срок, Kubernetes рассматривает как неудачные.
Если не указать startingDeadlineSeconds для CronJob, то задания не будут иметь дедлайн.
Если поле .spec.startingDeadlineSeconds установлено (не является нулевым), контроллер CronJob
измеряет время между моментом, когда задание должно быть создано, и реальным временем.
Если разница превышает указанный предел, он пропустит этот вызов задания.
Например, если установлено значение 200, задание может быть создано в период до 200 секунд позже фактического расписания.
Политика параллелизма (concurrency policy)
Поле .spec.concurrencyPolicy также является необязательным.
Оно определяет, как обращаться с одновременным выполнением заданий, созданных этим CronJob.
В этой спецификации может быть указана только одна из следующих политик параллелизма:
Allow (по умолчанию): CronJob разрешает одновременное выполнение заданий.Forbid: CronJob не разрешает одновременное выполнение заданий; если пришло время для выполнения нового задания,
а предыдущее еще не завершилось, CronJob пропускает новое задание.Replace: Если пришло время для выполнения нового задания, а предыдущее еще не завершилось,
CronJob заменит текущее задание на новое.
Заметьте, что принцип параллелизма применяется только к заданиям, созданным одним и тем же Cronjob'ом.
Если есть несколько CronJob'ов, их соответствующие задания всегда могут выполняться одновременно.
Остановка выполнения заданий по расписанию
Можно приостановить выполнение CronJob-заданий, присвоив необязательному полю .spec.suspend значение true.
По умолчанию это поле имеет значение false.
Эта настройка не влияет на задания, которые уже были запущены CronJob'ом.
Если установить это поле как true, все последующие выполнения будут приостановлены
(они остаются запланированными, но CronJob-контроллер не запускает задания для выполнения),
пока вы не отмените приостановку CronJob'a.
Внимание:
Работы, приостановленные во время запланированного выполнения, считаются пропущенными.
Когда
.spec.suspend изменяется с
true на
false для существующего CronJob'a без
дедлайна задержки начала задания, пропущенные задания планируются немедленно.
Лимиты на историю заданий
Поля .spec.successfulJobsHistoryLimit и .spec.failedJobsHistoryLimit являются необязательными.
В этих полях указывается, сколько завершенных и неудачных заданий должно быть сохранено в истории.
По умолчанию они установлены на 3 и 1 соответственно. Установка предела в 0 будет означать,
что никакие задания соответствующего типа не сохранятся после их завершения.
Другой способ автоматической очистки заданий см. в разделе Автоматическая очистка завершенных заданий.
Часовые пояса
СТАТУС ФИЧИ: Kubernetes v1.27 [stable]
Для CronJob'a, в которых не указан часовой пояс, kube-controller-manager
интерпретирует расписания относительно своего локального часового пояса.
Можно указать часовой пояс для CronJob'a, присвоив .spec.timeZone имя действительного
часового пояса.
Например, установка .spec.timeZone: "Etc/UTC" инструктирует Kubernetes интерпретировать расписание
относительно всемирного координированного времени.
База данных часовых поясов из стандартной библиотеки Go включена в бинарные файлы и используется в качестве запасного варианта на случай, если внешняя база данных недоступна в системе.
Ограничения CronJob
Неподдерживаемая спецификация TimeZone
Установка часового пояса с помощью переменных CRON_TZ или TZ в .spec.schedule
не поддерживается официально (и никогда не поддерживалась).
Начиная с Kubernetes 1.29, если попытаться задать расписание,
включающее спецификацию часового пояса TZ или CRON_TZ,
Kubernetes не сможет создать ресурс, выдав ошибку валидации.
Обновления для CronJobs, уже использующих TZ или CRON_TZ, будут продолжать выдавать
предупреждение клиенту.
Модификация задания CronJob
По своей структуре CronJob содержит шаблон для новых заданий.
Если изменить существующее задание CronJob, внесенные изменения будут
применены к новым заданиям, которые начнут выполняться после завершения
модификации. Задания (и их поды), которые уже были запущены, продолжат выполняться без изменений.
То есть CronJob не обновляет существующие задания, даже если они остаются запущенными.
Создание заданий
CronJob создает объект задания (Job) примерно один раз за время выполнения своего расписания.
Расписание является приблизительным, поскольку есть определенные обстоятельства,
при которых могут быть созданы два задания или не создано ни одного.
Kubernetes старается избегать таких ситуаций, но не может полностью предотвратить их. Поэтому
задания, которые вы определяете, должны быть идемпотентными.
Если в поле startingDeadlineSeconds задано большое значение или оно не определено (по умолчанию),
а также при условии, что concurrencyPolicy имеет значение Allow, задания всегда будут выполняться по крайней мере один раз.
Внимание:
Если startingDeadlineSeconds имеет значение меньше 10 секунд, задание CronJob, возможно, не будет запланировано. Это происходит потому, что CronJob выполняет проверку каждые 10 секунд.
Для каждого задания CronJob контроллер проверяет, сколько расписаний он пропустил за время, прошедшее с последнего расписания до настоящего момента. Если пропущено более 100 расписаний, то задание не запускается и фиксируется ошибка.
Cannot determine if job needs to be started. Too many missed start time (> 100). Set or decrease .spec.startingDeadlineSeconds or check clock skew.
Важно отметить, что если поле startingDeadlineSeconds установлено (не равно nil), контроллер считает, сколько пропущенных заданий произошло с момента значения startingDeadlineSeconds до настоящего момента, а не с момента последнего запланированного задания до настоящего момента. Например, если startingDeadlineSeconds равно 200, контроллер подсчитывает, сколько пропущенных заданий произошло за последние 200 секунд.
Задание CronJob считается пропущенным, если оно не было создано в запланированное время. Например, если для concurrencyPolicy установлено значение Forbid, и CronJob пытался быть запланирован, когда предыдущее расписание еще выполнялось, то он будет считаться пропущенным.
Например, предположим, что задание CronJob настроено на планирование нового задания каждую минуту, начиная с 08:30:00, а его поле поле startingDeadlineSeconds не установлено.
Если контроллер CronJob не функционирует с 08:29:00 до 10:21:00, задание не будет запущено, так как количество пропущенных заданий, которые не успели выполнить свое расписание, больше 100.
Чтобы подробнее проиллюстрировать эту концепцию, предположим, что задание CronJob настроено на планирование нового задания каждую одну минуту, начиная с 08:30:00, и его параметр startingDeadlineSeconds установлен на 200 секунд. Если контроллер CronJob вдруг не функционирует в течение того же периода, что и в предыдущем примере (с 08:29:00 по 10:21:00), задание все равно начнется в 10:22:00. Это происходит потому, что контроллер в данном случае проверяет, сколько пропущенных запланированных заданий было за последние 200 секунд (т. е. 3 пропущенных расписания), а не с момента последнего запланированного времени до настоящего момента.
CronJob отвечает только за создание заданий (Jobs), соответствующих его расписанию, а задание, в свою очередь, отвечает за управление подами, которые оно представляет.
Что дальше
- Ознакомьтесь с Подами и
Заданиями — двумя концепциями, на которые опираются CronJobs.
- Ознакомьтесь с подробным форматом
полей CronJob
.spec.schedule.
- Для инструкции по созданию и работе с CronJob, а также для примера
CronJob-манифеста см. раздел Выполнение автоматизированных задач с помощью CronJob.
CronJob является частью Kubernetes REST API.
Для получения более подробной информации прочтите справочник по
CronJob API.
5 - Планирование, приоритизация и вытеснение
В Kubernetes под планированием понимается поиск подходящих узлов, на которых kubelet сможет запустить Pod'ы. Приоритизация — процесс завершения работы Pod'ов с более низким приоритетом и высвобождения места для Pod'ов с более высоким приоритетом. Вытеснение — это проактивное завершение работы одного или нескольких Pod'ов на узлах с дефицитом ресурсов.
В Kubernetes под планированием понимается поиск узлов, подходящих для размещения Pod'ов так, чтобы kubelet
мог их запустить. Приоритизация (упреждение; preemption) — процесс завершения работы Pod'ов
с более низким приоритетом с освобождением места для Pod'ов с более высоким приоритетом. Вытеснение (eviction) — завершение работы одного или нескольких Pod'ов на узлах.
Планирование
Завершение работы Pod'ов
Нарушение работы Pod'ов (Pod disruption) — процесс,
в ходе которого происходит плановое или внеплановое (принудительное) завершение работы Pod'ов на узлах.
Плановое завершение работы Pod'ов инициируется владельцами приложений или администраторами
кластера. Внеплановое завершение работы обычно вызвано непредвиденными обстоятельствами различной природы,
например, с недостатком ресурсов на узлах или случайными удалениями.
5.1 - Распределение подов по узлам
Можно настроить под так, чтобы тот мог запускаться только на определенном(-ых) узле(-ах) или предпочитал определенную группу узлов.
Сделать это можно несколькими способами, при этом все рекомендуемые подходы используют селекторы лейблов для выбора.
Зачастую нужды в подобных ограничениях нет; планировщик автоматически размещает поды оптимальным образом (например, распределяет их по узлам, чтобы они не оказались все на одном узле с дефицитом ресурсов).
Однако в некоторых обстоятельствах возможность контролировать, куда именно попадет под, может пригодиться. Например, она поможет запланировать под на узел с быстрым SSD-хранилищем или разместить два активно взаимодействующих друг с другом пода в одной зоне доступности.
Для планирования подов на определенные узлы можно использовать любой из методов:
Лейблы узлов
Как и у многих других объектов Kubernetes, у узлов есть лейблы. Их можно навешивать вручную.
Kubernetes также навешивает стандартный набор лейблов на все узлы кластера.
Примечание:
Значения этих лейблов зависят от облачного провайдера, поэтому на них нельзя полагаться.
Например, в одних окружениях значение kubernetes.io/hostname может совпадать с именем узла, в других — отличаться.
Изоляция узла/ограничение его использования
Лейблы узлов позволяют размещать поды на определенные узлы или группы узлов. С их помощью можно планировать поды на узлы с определенными требованиями к изоляции, безопасности или соответствию нормативным положениям.
При использовании лейблов для изоляции узлов следует выбирать ключи лейблов, которые kubelet не может изменить. В этом случае взломанный узел не сможет навесить на себя эти лейблы в надежде, что планировщик разместит на него рабочие нагрузки.
Admission-плагин NodeRestriction не позволяет kubelet'у устанавливать или изменять лейблы с префиксом node-restriction.kubernetes.io/.
Чтобы использовать этот префикс для изоляции узла:
- Убедитесь, что используется авторизатор узлов и включен admission-плагин
NodeRestriction.
- Добавьте лейблы с префиксом
node-restriction.kubernetes.io/ к узлам и используйте их в селекторах узлов. Например, example.com.node-restriction.kubernetes.io/fips=true или example.com.node-restriction.kubernetes.io/pci-dss=true.
nodeSelector
nodeSelector — простейшая рекомендуемая форма настроек выбора узлов.
Можно добавить поле nodeSelector в спецификацию пода и перечислить в нем лейблы узлов, которые подходят для развертывания пода. В этом случае Kubernetes будет планировать под только на узлы со всеми указанными лейблами.
Дополнительную информацию см. в разделе Размещение подов на узлах.
Правила совместного/раздельного существования (affinity и anti-affinity)
nodeSelector — самый простой способ развернуть поды на узлах с определенными лейблами. Правила совместного/раздельного существования расширяют типы ограничений, которые можно накладывать. Вот некоторые из их преимуществ:
- Язык правил affinity/anti-affinity более выразителен.
nodeSelector выбирает узлы только со всеми указанными лейблами. Правила affinity/anti-affinity расширяют логику выбора и делают ее более гибкой.
- Правило может быть мягким (soft) или предпочтительным (preferred). В этом случае планировщик все равно запланирует под, даже если подходящего узла для него не найдется.
- При планировании пода планировщик может учитывать лейблы других подов, запущенных на узле (или в иной топологической области), а не только лейблы самого узла. Это позволяет формулировать правила, определяющие сосуществование подов на узле.
Правила совместного существования (affinity) бывают двух типов:
- Правила для узлов (node affinity) работают подобно полю
nodeSelector, но более выразительны. Кроме того, можно задавать мягкие правила.
- Правила для подов (inter-pod affinity и anti-affinity) позволяют при планировании учитывать лейблы других подов.
Правила совместного существования для узлов (node affinity)
Правила совместного существования для узлов концептуально похожи на nodeSelector. С помощью лейблов они позволяют ограничивать список узлов, на которые может быть запланирован под. Существует два типа таких правил:
requiredDuringSchedulingIgnoredDuringExecution: Планировщик не может запланировать под, если правило не выполнено. Работает как nodeSelector, но с более выразительным синтаксисом.preferredDuringSchedulingIgnoredDuringExecution: Планировщик пытается найти узел, который соответствует правилу. Если подходящий узел не удается найти, планировщик все равно планирует под.
Примечание:
В типах выше IgnoredDuringExecution означает, что под продолжит свою работу, если лейблы узлов изменятся после того, как Kubernetes запланировал его.
Задавать правила совместного существования для узлов можно с помощью поля .spec.affinity.nodeAffinity в спецификации пода.
В качестве примера рассмотрим следующую спецификацию пода:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0
В этом примере применяются следующие правила:
- У узла должен быть лейбл с ключом
topology.kubernetes.io/zone, и значение этого лейбла должно быть либо antarctica-east1, либо antarctica-west1.
- Предпочтительно, чтобы у узла был лейбл с ключом
another-node-label-key и значением another-node-label-value.
Можно использовать поле operator для указания логического оператора, который Kubernetes будет применять при интерпретации правил. Доступны In, NotIn, Exists, DoesNotExist, Gt и Lt.
Узнать больше о том, как они работают, можно в подразделе Операторы.
NotIn и DoesNotExist позволяют задавать правила раздельного существования (anti-affinity) для узла.
Кроме того, можно использовать taint'ы узлов, чтобы "отвадить" поды от определенных узлов.
Примечание:
Когда указаны и nodeSelector, и nodeAffinity, под будет запланирован на узел только в том случае, если оба этих условия удовлетворены.
Если указать несколько условий nodeSelectorTerms, привязанных к типам nodeAffinity, то под может быть запланирован на узел, если удовлетворяется одно из указанных условий nodeSelectorTerms. К условиям применяется логическое ИЛИ.
Если задать несколько выражений в поле matchExpressions для одного условия nodeSelectorTerms, под будет запланирован на узел только если удовлетворены все выражения matchExpressions. К условиям применяется логическое И.
Дополнительную информацию см. в разделе Размещаем поды на узлы с помощью Node Affinity.
Вес правил совместного существования
Для каждого правила типа preferredDuringSchedulingIgnoredDuringExecution можно указать вес weight в диапазоне от 1 до 100. Найдя несколько узлов, удовлетворяющих всем остальным требованиям для планирования пода, планировщик перебирает предпочтительные правила, которым удовлетворяет узел, и суммирует их веса.
Итоговая сумма добавляется к оценке, полученной при анализе других параметров, влияющих на приоритет узла. Принимая решение о размещении пода, планировщик отдает предпочтение узлам с наибольшей суммарной оценкой.
В качестве примера рассмотрим следующую спецификацию пода:
apiVersion: v1
kind: Pod
metadata:
name: with-affinity-anti-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: label-1
operator: In
values:
- key-1
- weight: 50
preference:
matchExpressions:
- key: label-2
operator: In
values:
- key-2
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0
Если правилу preferredDuringSchedulingIgnoredDuringExecution соответствуют два узла (один — с лейблом label-1:key-1, другой — с label-2:key-2), планировщик считает вес weight каждого узла и добавляет его к другим оценкам для этого узла. Под планируется на узел с наивысшей итоговой оценкой.
Примечание:
Чтобы Kubernetes смог запланировать поды в этом примере, необходимо, чтобы существовали узлы с лейблом kubernetes.io/os=linux.
Правила совместного существования и профили планирования
СТАТУС ФИЧИ: Kubernetes v1.20 [beta]
При настройке нескольких профилей планирования можно связать профиль с правилами совместного существования для узлов (это удобно, когда профиль применяется к определенному набору узлов). Для этого необходимо добавить addedAffinity в поле args плагина NodeAffinity в конфигурации планировщика. Например:
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
- schedulerName: foo-scheduler
pluginConfig:
- name: NodeAffinity
args:
addedAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: scheduler-profile
operator: In
values:
- foo
Правило addedAffinity применяется ко всем подам с полем .spec.schedulerName, имеющим значение foo-scheduler, в дополнение к NodeAffinity, заданному в PodSpec. Таким образом, подходящие для пода узлы должны удовлетворять параметрам addedAffinity и правилам .spec.NodeAffinity пода.
Поскольку конечные пользователи не видят addedAffinity, результат применения этих правил может быть для них неожиданным. Используйте лейблы узлов, которые однозначно соотносятся с именем профиля планировщика.
Примечание:
Контроллер DaemonSet,
создающий поды для DaemonSet'ов, не поддерживает профили планирования. Контроллер DaemonSet создает поды, а штатный планировщик Kubernetes, размещая их, следит за соблюдением правил
nodeAffinity.
Правила совместного/раздельного существования подов
Правила совместного/раздельного существования подов позволяют выбирать узлы для планирования в зависимости от лейблов подов, которые уже на этих узлах работают (вместо лейблов самих узлов).
Алгоритм работы правил совместного/раздельного существования подов можно описать так: "данный под должен (или не должен в случае раздельного (anti-affinity) существования) размещаться на X, если на нем уже работает один или несколько подов, удовлетворяющих правилу Y", где X — топологический домен, например, узел, стойка, зона/регион облачного провайдера и т. п., а Y — правило, которое Kubernetes пытается удовлетворить.
Для задания правил Y используются селекторы лейблов с необязательным связанным списком пространств имен. Для подов в Kubernetes указываются пространства имен, соответственно, их лейблы также оказываются неявно связаны с этими же пространствами имен. Любые селекторы лейблов для лейблов подов должны содержать пространства имен, в которых Kubernetes должен искать эти лейблы.
Топологический домен X задается с помощью topologyKey — ключа для лейбла узла, который система использует для обозначения домена. Примеры см. в разделе Типичные лейблы, аннотации и taint'ы.
Примечание:
Обработка правил совместного/раздельного существования подов требует значительных ресурсов и может значительно замедлить планирование в больших кластерах. Их не рекомендуется использовать в кластерах, число узлов в которых превышает несколько сотен.
Примечание:
Правила раздельного существования для подов требуют согласованности лейблов узлов. Другими словами, у каждого узла в кластере должен быть лейбл, относящий его к определенному ключу topologyKey. Отсутствие лейблов topologyKey у некоторых или всех узлов в кластере может привести к непредсказуемому поведению.
Типы правил совместного/раздельного существования подов
По аналогии c правилами для узлов существует два типа правил для подов:
requiredDuringSchedulingIgnoredDuringExecutionpreferredDuringSchedulingIgnoredDuringExecution
Например, с помощью правила совместного существования requiredDuringSchedulingIgnoredDuringExecution можно заставить планировщик размещать поды, относящиеся к разным сервисам, в одной зоне облачного провайдера, поскольку они активно обмениваются данными друг с другом.
Аналогичным образом можно использовать правило раздельного существования preferredDuringSchedulingIgnoredDuringExecution для распределения подов по нескольким зонам облачного провайдера.
Для задания правил совместного существования предназначено поле affinity.podAffinity в спецификации пода.
Для задания правил раздельного существования предназначено поле affinity.podAntiAffinity в спецификации пода.
Планирование группы подов, связанных правилами совместного существования
Если планируемый под — первый в серии подов, связанных правилами совместного существования,
он может быть запланирован, если удовлетворит всем остальным правилам совместного существования. Чтобы подтвердить, что этот под — действительно первый,
проводится проверка, которая должна показать, что пространство имен и селектор этого пода уникальны в кластере (то есть нет других таких подов). Кроме того,
под должен соответствовать своим собственным правилам, а выбранный узел — всем запрошенным топологиям.
Это предотвращает тупиковую ситуацию, когда поды не могут запланироваться из-за того, что все они связаны правилами совместного существования.
Пример правил совместного/раздельного существования для пода
Рассмотрим следующую спецификацию пода:
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: registry.k8s.io/pause:2.0
В примере задается одно правило совместного существования подов, и одно — раздельного. Для совместного правила используется жесткий тип requiredDuringSchedulingIgnoredDuringExecution, для раздельного — мягкий preferredDuringSchedulingIgnoredDuringExecution.
Правило совместного существования гласит, что планировщик может разместить под на узел, только если тот находится в зоне с одним или более подами с лейблом security=S1.
Например, если есть кластер с выделенной зоной, назовем ее "V",
состоящей из узлов с лейблом topology.kubernetes.io/zone=V, планировщик может
назначить под на любой узел зоны V только если в этой зоне уже есть хотя бы один под
с лейблом security=S1. И наоборот, если в зоне V нет подов с лейблом security=S1,
планировщик не сможет назначить под на какой-либо из узлов в этой зоне.
Правило раздельного существования гласит, что планировщик при возможности не должен размещать под на узел, если тот находится в зоне с одним или более подами с лейблом security=S2.
Например, если есть кластер с выделенной зоной, назовем ее "R",
состоящей из узлов с лейблами topology.kubernetes.io/zone=R. Планировщик должен избегать
назначать поды на узлы из зоны R, если в ней уже есть по крайней мере один под
с лейблом security=S2. Соответственно, если в зоне R нет подов с лейблами security=S2,
правило раздельного существования не будет влиять на планирование подов в эту зону.
Больше примеров правил совместного/раздельного существования для подов можно найти в рабочей документации.
Поле operator пода поддерживает значения In, NotIn, Exists и DoesNotExist при задании правил совместного/раздельного существования.
Узнать больше о том, как они работают, можно в подразделе Операторы.
В принципе, topologyKey может быть любым разрешенным лейблом-ключом со следующими исключениями по соображениям производительности и безопасности:
- При задании правил совместного/раздельного существования для подов пустое поле
topologyKey не допускается как для requiredDuringSchedulingIgnoredDuringExecution, так и для preferredDuringSchedulingIgnoredDuringExecution.
- Для правил раздельного существования типа
requiredDuringSchedulingIgnoredDuringExecution admission-контроллер разрешает использовать только kubernetes.io/hostname в качестве topologyKey. Для работы с кастомными топологиями admission-контроллер можно дополнить или совсем отключить его.
В дополнение к labelSelector и topologyKey можно опционально указать список пространств имен, которые должен выбирать labelSelector, с помощью поля namespaces на том же уровне, что labelSelector и topologyKey. Если поле namespaces опущено или пусто, по умолчанию выбирается пространство имен пода, в котором задаются правила совместного/раздельного существования.
Селектор пространств имен
СТАТУС ФИЧИ: Kubernetes v1.24 [stable]
Подходящие пространства имен также можно выбрать с помощью namespaceSelector, который попытается найти лейбл в наборе пространств имен.
Условия совместного существования применяются к пространствам имен, выбранным как селектором namespaceSelector, так и полем namespaces.
Обратите внимание, что пустой селектор namespaceSelector ({}) выбирает все пространства имен, в то время как пустой или null-список namespaces и null-селектор namespaceSelector выбирает пространство имен пода, в котором правило задано.
matchLabelKeys
СТАТУС ФИЧИ: Kubernetes v1.29 [alpha]
Примечание:
Поле matchLabelKeys является полем альфа-уровня и по умолчанию отключено в
Kubernetes 1.30.
Включить его можно с помощью переключателя функциональности
(feature gate) MatchLabelKeysInPodAffinity.
Kubernetes включает необязательное поле matchLabelKeys для правил совместного (раздельного) существования подов.
В нем указываются ключи для лейблов, которые должны совпадать с лейблами входящего пода,
чтобы правила совместного (раздельного) существования выполнялись.
Ключи используются для поиска значений в лейблах подов; эти ключи-лейблы объединяются (с помощью AND)
с ограничениями, задаваемыми с помощью поля labelSelector. Такая комбинированная фильтрация позволяет отобрать
набор существующих подов, которые приниматься в расчет при обработке правил совместного (раздельного) существования.
Обычно matchLabelKeys используется вместе с pod-template-hash (задается для подов,
которые управляются как часть деплоймента, где значение уникально для каждой ревизии).
Использование pod-template-hash в matchLabelKeys позволяет нацеливаться на поды, принадлежащие
к той же ревизии, что и входящий под. Таким образом, что скользящее обновление не нарушит правила совместного существования.
apiVersion: apps/v1
kind: Deployment
metadata:
name: application-server
...
spec:
template:
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- database
topologyKey: topology.kubernetes.io/zone
# При расчете affinity подов учитываются только поды из определенного выката.
# При обновлении Deployment'а новые поды будут следовать своим собственным правилам совместного существования
# (если они заданы в новом шаблоне подов)
matchLabelKeys:
- pod-template-hash
mismatchLabelKeys
СТАТУС ФИЧИ: Kubernetes v1.29 [alpha]
Примечание:
Поле mismatchLabelKeys является полем альфа-уровня и по умолчанию отключено в
Kubernetes 1.30.
Включить его можно с помощью переключателя функциональности
(feature gate) MatchLabelKeysInPodAffinity.
Kubernetes включает необязательное поле mismatchLabelKeys для определения правил совместного (раздельного) существования подов.
В поле указываются ключи для лейблов, которые не должны совпадать с лейблами входящего пода,
чтобы правила совместного (раздельного) существования подов удовлетворялись.
Один из примеров использования — размещение подов определенной группы пользователей (tenant'ов) или команды в конкретном топологическом домене (узле, зоне и т. д.).
То есть идея в том, чтобы избежать одновременного запуска подов от разных групп пользователей в одном топологическом домене.
apiVersion: v1
kind: Pod
metadata:
labels:
# Assume that all relevant Pods have a "tenant" label set
tenant: tenant-a
...
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
# следим за тем, чтобы поды, связанные с этим тенантом, попадали на нужный пул узлов
- matchLabelKeys:
- tenant
topologyKey: node-pool
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
# следим за тем, чтобы поды, связанные с этим тенантом, не смогли планироваться на узлы для другого тенанта
- mismatchLabelKeys:
- tenant # значение лейбла "tenant" этого пода будет предотвращать
# планирование на узлы в пулах, на которых работают поды
# другого тенанта
labelSelector:
# Должен быть labelSelector, который выбирает поды с лейблом tenant,
# иначе этот под также будет "ненавидеть" поды из daemonset'ов, например,
# те, у которых нет лейбла tenant.
matchExpressions:
- key: tenant
operator: Exists
topologyKey: node-pool
Другие примеры использования
Правила совместного/раздельного существования для подов особенно удобны, когда используются совместно с абстракциями более высокого уровня, такими как ReplicaSet, StatefulSet, Deployment и т. д. Эти правила позволяют настроить размещение рабочих нагрузок с учетом имеющейся топологии; например, пара связанных подов будет планироваться на один и тот же узел.
Представьте кластер, состоящий из трех узлов. Он используется для запуска веб-приложения и как in-memory-кэш (например, Redis). Предположим, что задержка между веб-приложением и кэшем должна быть минимальной. Правила совместного/раздельного существования для подов позволяют настроить планировщик так, чтобы тот размещал веб-серверы как можно ближе к кэшу.
В приведенном ниже примере конфигурации деплоймента с Redis его реплики получают лейбл app=store. Правило podAntiAffinity запрещает планировщику размещать несколько реплик с лейблом app=store на одном узле. В результате каждый узел получает по отдельной кэш-реплике.
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
Конфигурация деплоймента, приведенная ниже, создает три реплики веб-сервера с лейблом app=web-store.
Правило совместного существования предписывает планировщику размещать каждую реплику на узле, на котором уже имеется под с лейблом app=store. В то же время правило раздельного существования запрещает планировщику размещать несколько серверов с лейблом app=web-store на одном узле.
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: web-store
replicas: 3
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.16-alpine
Развертывание ресурсов в соответствии с приведенными выше конфигурациями приведет к созданию кластера, в котором на каждом узле будет по одному веб-серверу и одной реплике Redis (всего три отдельных узла):
| узел 1 |
узел 2 |
узел 3 |
| webserver-1 |
webserver-2 |
webserver-3 |
| cache-1 |
cache-2 |
cache-3 |
В итоге к каждому инстансу Redis'а, скорее всего, будет обращаться клиент, который работает с ним на том же узле. Подобный подход позволит минимизировать как перекос (дисбаланс нагрузки), так и задержки.
Правила совместного/раздельного существования для подов можно использовать и в других случаях.
См., например, руководство по ZooKeeper. В нем с помощью правил раздельного существования StatefulSet настраивается так, чтобы обеспечить высокую доступность (используется подход, аналогичный тому, что применен выше).
nodeName
Поле nodeName в спецификации пода — более непосредственный способ выбора узлов по сравнению с правилами совместного существования или селектором nodeSelector. Если поле nodeName не пустое, планировщик игнорирует под, а kubelet на узле с соответствующим именем пытается разместить под на этом узле. Приоритет поля nodeName выше, чем селектора nodeSelector или правил совместного/раздельного существования.
Однако у nodeName имеются и некоторые недостатки:
- Если узел с заданным именем не существует, под не будет запущен. Кроме того, в некоторых случаях он может быть автоматически удален.
- Если на узле с заданным именем недостаточно ресурсов для работы пода, последний будет остановлен; соответствующая причина (например, OutOfmemory или OutOfcpu) будет указана.
- В облачных окружениях имена узлов не всегда предсказуемы или стабильны.
Примечание:
Поле
nodeName предназначено для использования в кастомных планировщиках или в продвинутых случаях,
когда необходимо обойти настроенные планировщики. Обход планировщиков может привести к тому, что поды не будут запущены,
если целевые узлы окажутся перегруженными. С помощью правила
совместного существования (affinity) узла или поля
nodeselector под можно назначить на определенный узел, не обходя планировщики с помощью
nodeName.
Ниже приведен пример спецификации пода с полем nodeName:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: kube-01
Такой под будет работать только на узле с именем kube-01.
Ограничения на топологию распределения подов
С помощью ограничений на топологию распределения (topology spread constraints) можно настроить размещение подов в кластере по failure-доменам, таким как регионы, зоны, узлы, или любым другим заданным топологическим конфигурациям. Это позволяет повысить производительность, ожидаемую доступность или эффективность использования ресурсов.
Дополнительные сведения о принципах их работы читайте в разделе Ограничения на топологию распределения подов.
Операторы
Ниже приведены все логические операторы, которые можно использовать в поле operator для nodeAffinity и podAffinity.
| Оператор |
Действие |
In |
Значение лейбла присутствует в предоставленном наборе строк |
NotIn |
Значение лейбла отсутствует в предоставленном наборе строк |
Exists |
Лейбл с таким ключом существует для объекта |
DoesNotExist |
У объекта не существует лейбла с таким ключом |
Следующие операторы могут использоваться только с nodeAffinity.
| Оператор |
Действие |
Gt |
Введенное значение будет обработано как целое число, и это целое число меньше, чем целое число, полученное в результате обработки значения лейбла, указанного этим селектором |
Lt |
Введенное значение будет обработано как целое число, и это целое число больше, чем целое число, полученное в результате обработки значения лейбла, указанного этим селектором |
Примечание:
Операторы Gt и Lt не работают с нецелыми значениями. Если заданное значение
не является целым числом, под не будет запланирован. Кроме того, Gt и Lt
недоступны для podAffinity.
Что дальше
5.2 - Вытеснение, инициированное через API
Вытеснение, инициированное через API — процесс, при котором с помощью Eviction API
создается объект Eviction, который запускает корректное завершение работы Pod'а.
Вытеснение можно инициировать напрямую с помощью Eviction API или программно,
используя клиент API-сервера
(например, командой kubectl drain). В результате будет создан объект Eviction,
который запустит процесс контролируемого завершения работы Pod'а.
Вытеснения, инициированные через API, учитывают настройки PodDisruptionBudget
и terminationGracePeriodSeconds.
Создание с помощью API объекта Eviction для Pod'а аналогично выполнению
операции DELETE
для этого Pod'а, которая контролируется политикой.
Вызов API Eviction
Для доступа к API Kubernetes и создания объекта Eviction можно воспользоваться клиентской библиотекой. Необходимая операция оформляется в виде POST-запроса (см. пример ниже):
Примечание:
Вытеснение с версией policy/v1 доступно начиная с v1.22. Для более ранних релизов используйте policy/v1beta1.
{
"apiVersion": "policy/v1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
Примечание:
Признана устаревшей в v1.22; заменена на policy/v1.
{
"apiVersion": "policy/v1beta1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
Также можно попытаться выполнить операцию вытеснения,
обратившись к API с помощью curl или wget, как показано в следующем примере:
curl -v -H 'Content-type: application/json' https://your-cluster-api-endpoint.example/api/v1/namespaces/default/pods/quux/eviction -d @eviction.json
Как работает вытеснение, инициированное через API
При вытеснении, инициированном через API, сервер API выполняет admission-проверки
и отвечает одним из следующих способов:
200 OK: вытеснение разрешено, подресурс Eviction создан,
Pod удален (аналогично отправке запроса DELETE на URL Pod'а).429 Too Many Requests: вытеснение в данный момент не разрешено из-за настроек
PodDisruptionBudget.
Попытку вытеснения можно повторить позже. Такой ответ также может быть вызван
работой механизма по ограничению частоты запросов к API.500 Internal Server Error: вытесение запрещено из-за неправильной конфигурации;
например, несколько PodDisruptionBudget'ов могут ссылаться на один и тот же Pod.
Если Pod, предназначенный для вытеснения, не является частью рабочей нагрузки
с настроенным PodDisruptionBudget'ом, сервер API всегда возвращает 200 OK и
разрешает вытеснение.
В случае, если вытеснение разрешено, процесс удаления Pod'а выглядит следующим образом:
- К ресурсу
Pod на сервере API добавляется метка времени удаления,
после чего сервер API считает ресурс Pod завершенным (terminated). Ресурс Pod также помечается
настроенным grace-периодом.
- kubelet на узле, где запущен
локальный Pod, замечает, что ресурс
Pod помечен на удаление, и приступает к
корректному завершению работы локального Pod'а.
- Пока kubelet завершает работу Pod'а, управляющий слой удаляет Pod из объектов
Endpoint и
EndpointSlice.
В результате контроллеры больше не рассматривают Pod как валидный объект.
- После истечения периода корректного завершения работы (grace-периода) kubelet
принудительно завершает работу локального Pod'а.
- kubelet передает API-серверу информацию о необходимости удалить ресурс
Pod.
- Сервер API удаляет ресурс
Pod.
Зависшие вытеснения
В некоторых ситуациях сбой приводит к тому, что API Eviction начинает возвращать
исключительно ответы 429 или 500. Такое может случиться, если, например,
за создание Pod'ов для приложения отвечает ReplicaSet, однако новые Pod'ы не
переходят в состояние Ready. Подобное поведение также может наблюдаться в случаях,
когда у последнего вытесненного Pod'а слишком долгий период завершения работы (grace-период).
Одно из следующих решений может помочь решить проблему:
- Прервите или приостановите автоматическую операцию, вызвавшую сбой.
Перед повторным запуском операции внимательно изучите сбойное приложение.
- Подождите некоторое время, затем напрямую удалите Pod из управляющего слоя
кластера вместо того, чтобы пытаться удалить его с помощью Eviction API.
Что дальше
6 - Администрирование кластера
Lower-level detail relevant to creating or administering a Kubernetes cluster.
Обзор администрирования кластера предназначен для всех, кто создает или администрирует кластер Kubernetes. Это предполагает некоторое знакомство с основными концепциями Kubernetes.
Планирование кластера
См. Руководства в разделе настройка для получения примеров того, как планировать, устанавливать и настраивать кластеры Kubernetes. Решения, перечисленные в этой статье, называются distros.
Примечание:
не все дистрибутивы активно поддерживаются. Выбирайте дистрибутивы, протестированные с последней версией Kubernetes.
Прежде чем выбрать руководство, вот некоторые соображения:
- Вы хотите опробовать Kubernetes на вашем компьютере или собрать много узловой кластер высокой доступности? Выбирайте дистрибутивы, наиболее подходящие для ваших нужд.
- Будете ли вы использовать размещенный кластер Kubernetes, такой, как Google Kubernetes Engine или разместите собственный кластер?
- Будет ли ваш кластер в помещении или в облаке (IaaS)? Kubernetes не поддерживает напрямую гибридные кластеры. Вместо этого вы можете настроить несколько кластеров.
- Если вы будете настраивать Kubernetes в помещении (локально), подумайте, какая сетевая модель подходит лучше всего.
- Будете ли вы запускать Kubernetes на оборудований "bare metal" или на виртуальных машинах (VMs)?
- Вы хотите запустить кластер или планируете активно разворачивать код проекта Kubernetes? В последнем случае выберите активно разрабатываемый дистрибутив. Некоторые дистрибутивы используют только двоичные выпуски, но предлагают более широкий выбор.
- Ознакомьтесь с компонентами необходимые для запуска кластера.
Управление кластером
Обеспечение безопасности кластера
Обеспечение безопасности kubelet
Дополнительные кластерные услуги
6.1 - Сертификаты
Чтобы узнать, как генерировать сертификаты для кластера, см. раздел Сертификаты.
6.2 - Управление ресурсами
Итак, вы развернули приложение и настроили доступ к нему с помощью сервиса. Что дальше? Kubernetes предоставляет ряд инструментов, помогающих управлять развертыванием приложений, включая их масштабирование и обновление. Среди особенностей, которые мы обсудим более подробно, — конфигурационные файлы и лейблы.
Организация конфигураций ресурсов
Многие приложения требуют создания нескольких ресурсов типа Deployment и Service. Управление ими можно упростить, сгруппировав в один YAML-файл (со строкой "---" в качестве разделителя). Например:
apiVersion: v1
kind: Service
metadata:
name: my-nginx-svc
labels:
app: nginx
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Можно создавать сразу несколько ресурсов:
kubectl apply -f https://k8s.io/examples/application/nginx-app.yaml
service/my-nginx-svc created
deployment.apps/my-nginx created
Ресурсы будут создаваться в порядке, в котором они описаны в файле. Таким образом, первым лучше всего описать сервис — это позволит планировщику распределять Pod'ы этого сервиса по мере их создания контроллером (контроллерами), например, Deployment'ом.
kubectl apply также может принимать сразу несколько аргументов -f:
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-svc.yaml -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
Кроме того, можно указывать директории вместо отдельных файлов или в дополнение ним:
kubectl apply -f https://k8s.io/examples/application/nginx/
kubectl прочитает все файлы с расширениями .yaml, .yml или .json.
Рекомендуется размещать ресурсы, имеющие отношение к одному микросервису или уровню приложения, в одном файле, а также группировать все файлы, связанные с приложением, в одной директории. Если уровни вашего приложения связываются друг с другом через DNS, можно развернуть все компоненты стека совместно.
Также в качестве источника конфигурации можно указать URL — это удобно при создании/настройке с использованием конфигурационных файлов, размещенных на GitHub:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/website/main/content/en/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx created
Пакетные операции в kubectl
Создание ресурсов — не единственная операция, которую kubectl может выполнять в рамках одной команды. Этот инструмент также способен извлекать имена ресурсов из конфигурационных файлов для выполнения других операций, в частности, для удаления созданных ресурсов:
kubectl delete -f https://k8s.io/examples/application/nginx-app.yaml
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
В случае двух ресурсов их можно перечислить в командной строке, используя синтаксис вида resource/name:
kubectl delete deployments/my-nginx services/my-nginx-svc
При большем количестве ресурсов удобнее указать селектор (запрос по лейблу) с помощью -l или --selector, который отфильтрует ресурсы по их лейблам:
kubectl delete deployment,services -l app=nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
Поскольку kubectl выводит имена ресурсов в том же синтаксисе, что и получает, можно выстраивать цепочки операций с помощью $() или xargs:
kubectl get $(kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service)
kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service | xargs -i kubectl get {}
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
Приведенные выше команды сначала создают ресурсы в разделе examples/application/nginx/, выводят о них информацию в формате -o name (то есть в виде пары resource/name). Затем в результатах производится поиск по "service" (grep), и информация о найденных ресурсах выводится с помощью kubectl get.
Если ресурсы хранятся в нескольких поддиректориях в пределах одной директории, можно рекурсивно выполнять операции и в этих поддиректориях, указав --recursive или -R наряду с флагом --filename, -f.
Предположим, что существует директория project/k8s/development, в которой хранятся все манифесты, необходимые для dev-окружения, организованные по типу ресурсов:
project/k8s/development
├── configmap
│ └── my-configmap.yaml
├── deployment
│ └── my-deployment.yaml
└── pvc
└── my-pvc.yaml
По умолчанию при выполнении массовых операций над project/k8s/development команда остановится на первом уровне, не обрабатывая поддиректории. К примеру, попытка создать ресурсы, описанные в этой директории, приведет к ошибке:
kubectl apply -f project/k8s/development
error: you must provide one or more resources by argument or filename (.json|.yaml|.yml|stdin)
Вместо этого следует указать флаг --recursive или -R с флагом --filename, -f:
kubectl apply -f project/k8s/development --recursive
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
Флаг --recursive работает с любыми операциями, принимающими флаг --filename, -f, например: kubectl {create, get, delete, describe, rollout} и т.д.
Флаг --recursive также работает для нескольких аргументов -f:
kubectl apply -f project/k8s/namespaces -f project/k8s/development --recursive
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
В разделе Инструмент командной строки kubectl доступна дополнительная информация о kubectl.
Эффективное использование лейблов
Во всех примерах, рассмотренных до этого момента, к ресурсам прикреплялся лишь один лейбл. Однако существуют сценарии, когда необходимо использовать несколько лейблов, чтобы отличить наборы ресурсов друг от друга.
Например, разные приложения могут использовать разные значения для лейбла app, а в случае многоуровневого приложения вроде гостевой книги лейблы могут указывать на соответствующий уровень. Например, у фронтенда могут быть следующие лейблы:
labels:
app: guestbook
tier: frontend
в то время как у master'а и slave'а Redis будут лейблы tier и, возможно, даже дополнительный лейбл role:
labels:
app: guestbook
tier: backend
role: master
и
labels:
app: guestbook
tier: backend
role: slave
Лейблы позволяют группировать ресурсы по любому параметру с соответствующим лейблом:
kubectl apply -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE APP TIER ROLE
guestbook-fe-4nlpb 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-ght6d 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-jpy62 1/1 Running 0 1m guestbook frontend <none>
guestbook-redis-master-5pg3b 1/1 Running 0 1m guestbook backend master
guestbook-redis-slave-2q2yf 1/1 Running 0 1m guestbook backend slave
guestbook-redis-slave-qgazl 1/1 Running 0 1m guestbook backend slave
my-nginx-divi2 1/1 Running 0 29m nginx <none> <none>
my-nginx-o0ef1 1/1 Running 0 29m nginx <none> <none>
kubectl get pods -lapp=guestbook,role=slave
NAME READY STATUS RESTARTS AGE
guestbook-redis-slave-2q2yf 1/1 Running 0 3m
guestbook-redis-slave-qgazl 1/1 Running 0 3m
Канареечные развертывания
Еще один сценарий, в котором применение нескольких лейблов как нельзя кстати, — дифференциация развертываний отдельных релизов или конфигураций одного и того же компонента. Как правило, новая версия приложения (указанная с помощью тега образа в шаблоне Pod'а) запускается в так называемом канареечном (canary) развертывании параллельно с предыдущей версией. Далее на нее направляется часть реального production-трафика.
В примере ниже лейбл track помогает различить релизы.
У основного, стабильного релиза он будет иметь значение stable:
name: frontend
replicas: 3
...
labels:
app: guestbook
tier: frontend
track: stable
...
image: gb-frontend:v3
У нового релиза фронтенда гостевой книги значение этого лейбла будет другим (canary), чтобы два набора Pod'ов не пересекались:
name: frontend-canary
replicas: 1
...
labels:
app: guestbook
tier: frontend
track: canary
...
image: gb-frontend:v4
Чтобы охватить оба набора реплик, сервис фронтенда следует настроить на выбор общего подмножества их лейблов (т.е. опустить лейбл track). В результате трафик будет поступать на обе версии приложения:
selector:
app: guestbook
tier: frontend
При этом число стабильных и канареечных реплик можно менять, регулируя долю production-трафика, которую будет получать каждая версия приложения (три к одному в нашем случае). Убедившись в стабильности новой версии, можно поменять значение ее лейбла track с canary на stable.
Более подробный пример доступен в руководстве по развертыванию Ghost.
Обновление лейблов
Иногда возникает необходимость поменять лейблы у существующих Pod'ов и других ресурсов перед созданием новых. Сделать это можно с помощью команды kubectl label. Например, чтобы промаркировать все Pod'ы NGINX как имеющие отношение к фронтенду, выполните следующую команду:
kubectl label pods -l app=nginx tier=fe
pod/my-nginx-2035384211-j5fhi labeled
pod/my-nginx-2035384211-u2c7e labeled
pod/my-nginx-2035384211-u3t6x labeled
Сначала она выберет все Pod'ы с лейблом app=nginx, а затем пометит их лейблом tier=fe. Чтобы просмотреть список этих Pod'ов, выполните:
kubectl get pods -l app=nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
Будут выведены все Pod'ы app=nginx с дополнительным столбцом tier (задается с помощью -L или --label-columns).
Дополнительную информацию можно найти в разделах Лейблы и kubectl label.
Обновление аннотаций
Иногда возникает потребность навесить на ресурсы аннотации. Аннотации — это произвольные неидентифицирующие метаданные для извлечения клиентами API (инструментами, библиотеками и т.п.). Добавить аннотацию можно с помощью команды kubectl annotate. Например:
kubectl annotate pods my-nginx-v4-9gw19 description='my frontend running nginx'
kubectl get pods my-nginx-v4-9gw19 -o yaml
apiVersion: v1
kind: pod
metadata:
annotations:
description: my frontend running nginx
...
Для получения дополнительной информации обратитесь к разделу Аннотации и описанию команды kubectl annotate.
Масштабирование приложения
Для масштабирования приложения можно воспользоваться инструментом kubectl. Например, следующая команда уменьшит число реплик с 3 до 1:
kubectl scale deployment/my-nginx --replicas=1
deployment.apps/my-nginx scaled
После ее применения количество Pod'ов под управлением соответствующего объекта Deployment сократится до одного:
kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
Чтобы система автоматически выбирала необходимое количество реплик NGINX в диапазоне от 1 до 3, выполните следующую команду:
kubectl autoscale deployment/my-nginx --min=1 --max=3
horizontalpodautoscaler.autoscaling/my-nginx autoscaled
Теперь количество реплик NGINX будет автоматически увеличиваться и уменьшаться по мере необходимости.
Для получения дополнительной информации см. разделы kubectl scale, kubectl autoscale и horizontal pod autoscaler.
Обновление ресурсов "на месте"
Иногда возникает необходимость внести мелкие обновления в созданные ресурсы, не требующие их пересоздания.
kubectl apply
Хранить конфигурационные файлы рекомендуемтся в системе контроля версий (см. конфигурация как код). В этом случае их можно будет поддерживать и версионировать вместе с кодом ресурсов, которые те конфигурируют. Далее с помощью команды kubectl apply изменения, внесенные в конфигурацию, можно применить к кластеру.
Она сравнит новую версию конфигурации с предыдущей и применит внесенные изменения, не меняя параметры, установленные автоматически, не затронутые новой редакцией конфигурации.
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx configured
Обратите внимание, что kubectl apply добавляет к ресурсу аннотацию, помогающую отслеживать изменения в конфигурации с момента предыдущего вызова. При вызове kubectl apply проводит трехстороннее сравнение (three-way diff) предыдущей конфигурации, ее текущей и новой версий, которое определяет, какие правки следует внести в ресурс.
На данный момент ресурсы в Kubernetes создаются без данной аннотации, поэтому при первом вызове kubectl apply проведет двустороннее сравнение входных данных и текущей конфигурации ресурса. Кроме того, она не cможет определить, какие свойства, заданные при создании ресурса, требуют удаления (соответственно, не будет их удалять).
При всех последующих вызовах kubectl apply и других команд, меняющих конфигурацию, таких как kubectl replace и kubectl edit, аннотация будет обновляться. В результате kubectl apply сможет проводить трехстороннее сравнение (three-way diff), определяя, какие свойства требуют удаления, и удалять их.
kubectl edit
Ресурсы также можно обновлять с помощью команды kubectl edit:
kubectl edit deployment/my-nginx
По сути, kubectl edit объединяет в себе логику нескольких команд, упрощая жизнь пользователям: сначала она получает (get) ресурс, вызывает текстовый редактор, а затем применяет (apply) обновленную конфигурацию:
kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
vi /tmp/nginx.yaml
# внесите правки и сохраните файл
kubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
rm /tmp/nginx.yaml
Обратите внимание, что задать предпочитаемый текстовый редактор можно с помощью переменных окружения EDITOR или KUBE_EDITOR.
За дополнительной информацией обратитесь к разделу kubectl edit.
kubectl patch
Команда kubectl patch обновляет объекты API "на месте". Она поддерживает форматы JSON patch, JSON merge patch и strategic merge patch. См. разделы Обновление объектов API "на месте" с помощью kubectl patch и kubectl patch.
Обновления, требующие перерыва в работе
Иногда может понадобиться обновить поля ресурса, которые нельзя изменить после инициализации, или возникнет необходимость немедленно внести рекурсивные изменения, например, "починить" сбойные Pod'ы, созданные Deployment'ом. Для этого можно воспользоваться командой replace --force, которая удалит и пересоздаст ресурс. Вот как можно внести правки в исходный файл конфигурации в нашем примере:
kubectl replace -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml --force
deployment.apps/my-nginx deleted
deployment.apps/my-nginx replaced
Обновление приложения без перерыва в работе
В какой-то момент возникнет необходимость обновить развернутое приложение. Обычно это делают, указывая новый образ или тег образа, как в приведенном выше сценарии канареечного развертывания. kubectl поддерживает несколько видов обновлений, каждый из которых подходит для разных сценариев.
Ниже будет рассказано, как создавать и обновлять приложения с помощью объектов Deployment.
Предположим, что в кластере используется версия NGINX 1.14.2:
kubectl create deployment my-nginx --image=nginx:1.14.2
deployment.apps/my-nginx created
с тремя репликами (чтобы старые и новые ревизии могли сосуществовать):
kubectl scale deployment my-nginx --current-replicas=1 --replicas=3
deployment.apps/my-nginx scaled
Чтобы перейти на версию 1.16.1, измените значение параметра .spec.template.spec.containers[0].image с nginx:1.14.2 на nginx:1.16.1:
kubectl edit deployment/my-nginx
Вот и все! Deployment декларативно обновит развернутое приложение NGINX "за кулисами". При этом Kubernetes проследит, чтобы число недоступных реплик в каждый момент времени не превышало определенного значения, а также за тем, чтобы количество новых реплик не превышало определенного предела, установленного для желаемого числа Pod'ов. Более подробную информацию об этом можно получить в разделе Deployment.
Что дальше
6.3 - Сеть в кластере
Сеть — важная часть Kubernetes, но понять, как именно она работает, бывает непросто. Существует 4 уникальных сетевых проблемы, которые требуют внимнаия:
- Высокосвязанные коммуникации между контейнерами: решается организацией коммуникации между Pod'ами и
localhost.
- Связь Pod'ов друг с другом (Pod-to-Pod): именно ей уделяется основное внимание в этом документе.
- Связь Pod'ов с сервисами (Pod-to-Service): подробнее об этом можно почитать в разделе Сервисы.
- Связь внешних систем с сервисами (External-to-Service): информация о данных коммуникациях также приведена в разделе Сервисы.
Суть Kubernetes — в организации совместного использования хостов приложениями. Обычно совместное использование подразумевает, что два приложения не могут задействовать одни и те же порты. Создать единую глобальную схему использования портов очень сложно. В результате пользователи рискуют получить сложноустранимые проблемы на уровне кластера.
Динамическое распределение портов значительно усложняет систему: каждое приложение должно уметь принимать порты в виде флагов-параметров, серверы API должны уметь вставлять динамические номера портов в конфигурационные блоки, сервисы должны знать, как найти друг друга и т.п. Вместо того чтобы пытаться разобраться со всем этим, Kubernetes использует иной подход.
Больше узнать о сетевой модели Kubernetes можно в соответствующем разделе.
Реализация сетевой модели Kubernetes
Сетевая модель реализуется средой исполнения для контейнеров на узлах. Наиболее распространенные среды исполнения используют плагины Container Network Interface (CNI) для управления сетью и обеспечения безопаснояти коммуникаций. Существует множество различных плагинов CNI от разных разработчиков. Некоторые из них предлагают только базовые функции, такие как добавление и удаление сетевых интерфейсов. Другие позволяют проводить интеграцию с различныеми системами оркестрации контейнеров, поддерживают запуск нескольких CNI-плагинов/расширенные функции IPAM и т.д.
Неполный список сетевых аддонов, поддерживаемых Kubernetes, приведен на соответствующей странице в разделе "Сеть и сетевая политика".
Что дальше
Подробнее о разработке сетевой модели, принципах, лежащих в ее основе, и некоторых планах на будущее можно узнать из соответствующего документа.
6.4 - Архитектура для сбора логов
Логи помогают понять, что происходит внутри приложения. Они особенно полезны для отладки проблем и мониторинга деятельности кластера. У большинства современных приложений имеется тот или иной механизм сбора логов. Контейнерные движки в этом смысле не исключение. Самый простой и наиболее распространенный метод сбора логов для контейнерных приложений задействует потоки stdout и stderr.
Однако встроенной функциональности контейнерного движка или среды исполнения обычно недостаточно для организации полноценного решения по сбору логов.
Например, может возникнуть необходимость просмотреть логи приложения при аварийном завершении работы Pod'а, его вытеснении (eviction) или "падении" узла.
В кластере у логов должно быть отдельное хранилище и жизненный цикл, не зависящий от узлов, Pod'ов или контейнеров. Эта концепция называется сбор логов на уровне кластера.
Архитектуры для сбора логов на уровне кластера требуют отдельного бэкенда для их хранения, анализа и выполнения запросов. Kubernetes не имеет собственного решения для хранения такого типа данных. Вместо этого существует множество продуктов для сбора логов, которые прекрасно с ним интегрируются. В последующих разделах описано, как обрабатывать логи и хранить их на узлах.
Основы сбора логов в Kubernetes
В примере ниже используется спецификация Pod с контейнером для отправки текста в стандартный поток вывода раз в секунду.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Запустить его можно с помощью следующей команды:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
Результат будет таким:
Получить логи можно с помощью команды kubectl logs, как показано ниже:
Результат будет таким:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
Команда kubectl logs --previous позволяет извлечь логи из предыдущего воплощения контейнера. Если в Pod'е несколько контейнеров, выбрать нужный для извлечения логов можно с помощью флага -c:
kubectl logs counter -c count
Для получения дополнительной информации см. документацию по kubectl logs.
Сбор логов на уровне узла
Среда исполнения для контейнера обрабатывает и перенаправляет любой вывод в потоки stdout и stderr приложения. Docker Engine, например, перенаправляет эти потоки драйверу журналирования, который в Kubernetes настроен на запись в файл в формате JSON.
Примечание:
JSON-драйвер Docker для сбора логов рассматривает каждую строку как отдельное сообщение. В данном случае поддержка многострочных сообщений отсутствует. Обработка многострочных сообщений должна выполняться на уровне лог-агента или выше.
По умолчанию, если контейнер перезапускается, kubelet сохраняет один завершенный контейнер с его логами. Если Pod вытесняется с узла, все соответствующие контейнеры также вытесняются вместе с их логами.
Важным моментом при сборе логов на уровне узла является их ротация, чтобы логи не занимали все доступное место на узле. Kubernetes не отвечает за ротацию логов, но способен развернуть инструмент для решения этой проблемы. Например, в кластерах Kubernetes, развертываемых с помощью скрипта kube-up.sh, имеется инструмент logrotate, настроенный на ежечасный запуск. Также можно настроить среду исполнения контейнера на автоматическую ротацию логов приложения.
Подробную информацию о том, как kube-up.sh настраивает логирование для образа COS на GCP, можно найти в соответствующем скрипте configure-helper.
При использовании среды исполнения контейнера CRI kubelet отвечает за ротацию логов и управление структурой их директории. kubelet передает данные среде исполнения контейнера CRI, а та сохраняет логи контейнера в указанное место. С помощью параметров containerLogMaxSize и containerLogMaxFiles в конфигурационном файле kubelet'а можно настроить максимальный размер каждого лог-файла и максимальное число таких файлов для каждого контейнера соответственно.
При выполнении команды kubectl logs (как в примере из раздела про основы сбора логов) kubelet на узле обрабатывает запрос и считывает данные непосредственно из файла журнала. Затем он возвращает его содержимое.
Примечание:
Если ротацию выполнила внешняя система или используется среда исполнения контейнера CRI, команде kubectl logs будет доступно содержимое только последнего лог-файла. Например, имеется файл размером 10 МБ, logrotate выполняет ротацию, и получается два файла: первый размером 10 МБ, второй - пустой. В этом случае kubectl logs вернет второй лог-файл (пустой).
Логи системных компонентов
Существует два типа системных компонентов: те, которые работают в контейнере, и те, которые работают за пределами контейнера. Например:
- планировщик Kubernetes и kube-proxy выполняются в контейнере;
- kubelet и среда исполнения контейнера работают за пределами контейнера.
На машинах с systemd среда исполнения и kubelet пишут в journald. Если systemd отсутствует, среда исполнения и kubelet пишут в файлы .log в директории /var/log. Системные компоненты внутри контейнеров всегда пишут в директорию /var/log, обходя механизм ведения логов по умолчанию. Они используют библиотеку для сбора логов klog. Правила сбора логов и рекомендации можно найти в соответствующей документации.
Как и логи контейнеров, логи системных компонентов в директории /var/log необходимо ротировать. В кластерах Kubernetes, созданных с помощью скрипта kube-up.sh, эти файлы настроены на ежедневную ротацию с помощью инструмента logrotate или при достижении 100 МБ.
Архитектуры для сбора логов на уровне кластера
Kubernetes не имеет собственного решения для сбора логов на уровне кластера, но есть общие подходы, которые можно рассмотреть. Вот некоторые из них:
- использовать агент на уровне узлов (запускается на каждом узле);
- внедрить в Pod с приложением специальный sidecar-контейнер для сбора логов;
- отправлять логи из приложения непосредственно в бэкенд.
Использование агента на уровне узлов
Сбор логов на уровне кластера можно реализовать, запустив node-level-агент на каждом узле. Лог-агент — это специальный инструмент, который предоставляет доступ к логам или передает их бэкенду. Как правило, лог-агент представляет собой контейнер с доступом к директории с файлами логов всех контейнеров приложений на этом узле.
Поскольку лог-агент должен работать на каждом узле, рекомендуется запускать его как DaemonSet.
Сбор логов на уровне узла предусматривает запуск одного агента на узел и не требует изменений в приложениях, работающих на узле.
Контейнеры пишут в stdout и stderr, но без согласованного формата. Агент на уровне узла собирает эти логи и направляет их на агрегацию.
Сбор логов с помощью sidecar-контейнера с лог-агентом
Sidecar-контейнер можно использовать одним из следующих способов:
- sidecar-контейнер транслирует логи приложений на свой собственный
stdout;
- в sidecar-контейнере работает агент, настроенный на сбор логов из контейнера приложения.
Транслирующий sidecar-контейнер
Настроив sidecar-контейнеры на вывод в их собственные потоки stdout и stderr, можно воспользоваться преимуществами kubelet и лог-агента, которые уже работают на каждом узле. Sidecar-контейнеры считывают логи из файла, сокета или journald. Затем каждый из них пишет логи в собственный поток stdout или stderr.
Такой подход позволяет разграничить потоки логов от разных частей приложения, некоторые из которых могут не поддерживать запись в stdout или stderr. Логика, управляющая перенаправлением логов, проста и не требует значительных ресурсов. Кроме того, поскольку stdout и stderr обрабатываются kubelet'ом, можно использовать встроенные инструменты вроде kubectl logs.
Предположим, к примеру, что в Pod'е работает один контейнер, который пишет логи в два разных файла в двух разных форматах. Вот пример конфигурации такого Pod'а:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Не рекомендуется писать логи разных форматов в один и тот же поток, даже если удалось перенаправить оба компонента в stdout контейнера. Вместо этого можно создать два sidecar-контейнера. Каждый из них будет забирать определенный лог-файл с общего тома и перенаправлять логи в свой stdout.
Вот пример конфигурации Pod'а с двумя sidecar-контейнерами:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Доступ к каждому потоку логов такого Pod'а можно получить отдельно, выполнив следующие команды:
kubectl logs counter count-log-1
Результат будет таким:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
Результат будет таким:
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
Агент на уровне узла, установленный в кластере, подхватывает эти потоки логов автоматически без дополнительной настройки. При желании можно настроить агент на парсинг логов в зависимости от контейнера-источника.
Обратите внимание: несмотря на низкое использование процессора и памяти (порядка нескольких milliCPU для процессора и пары мегабайт памяти), запись логов в файл и их последующая потоковая передача в stdout может вдвое увеличить нагрузку на диск. Если приложение пишет в один файл, рекомендуется установить /dev/stdout в качестве адресата, нежели использовать подход с транслирующим контейнером.
Sidecar-контейнеры также можно использовать для ротации файлов логов, которые не могут быть ротированы самим приложением. В качестве примера можно привести небольшой контейнер, периодически запускающий logrotate. Однако рекомендуется использовать stdout и stderr напрямую, а управление политиками ротации и хранения оставить kubelet'у.
Sidecar-контейнер с лог-агентом
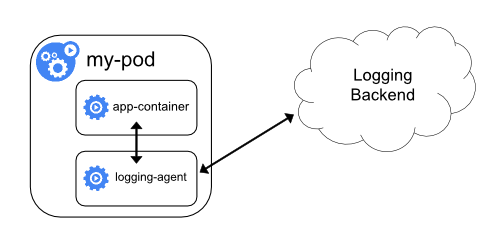
Если лог-агент на уровне узла недостаточно гибок для ваших потребностей, можно создать sidecar-контейнер с отдельным лог-агентом, специально настроенным на работу с приложением.
Примечание:
Работа лог-агента в sidecar-контейнере может привести к значительному потреблению ресурсов. Более того, доступ к этим журналам с помощью kubectl logs будет невозможен, поскольку они не контролируются kubelet'ом.
Ниже приведены два файла конфигурации sidecar-контейнера с лог-агентом. Первый содержит ConfigMap для настройки fluentd.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Примечание:
За информацией о настройке fluentd обратитесь к его
документации.
Второй файл описывает Pod с sidecar-контейнером, в котором работает fluentd. Pod монтирует том с конфигурацией fluentd.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
В приведенных выше примерах fluentd можно заменить на другой лог-агент, считывающий данные из любого источника в контейнере приложения.
Прямой доступ к логам из приложения
Сбор логов приложения на уровне кластера, при котором доступ к ним осуществляется напрямую, выходит за рамки Kubernetes.
6.5 - Логи системных компонентов
Логи системных компонентов регистрируют события, происходящие в кластере, что может быть очень полезно при отладке. Степень детализации логов настраивается. Так, в логах низкой детализации будет содержаться только информация об ошибках внутри компонента, в то время как логи высокой детализации будут содержать пошаговую трассировку событий (доступ по HTTP, изменения состояния Pod'а, действия контроллера, решения планировщика).
Klog
klog — библиотека Kubernetes для сбора логов. Отвечает за генерацию соответствующих сообщений для системных компонентов оркестратора.
Дополнительные сведения о настройке klog можно получить в Справке по CLI.
В настоящее время ведется работа по упрощению процесса сбора логов в компонентах Kubernetes. Приведенные ниже флаги командной строки klog устарели, начиная с версии Kubernetes 1.23, и будут удалены в одном из будущих релизов:
--add-dir-header--alsologtostderr--log-backtrace-at--log-dir--log-file--log-file-max-size--logtostderr--one-output--skip-headers--skip-log-headers--stderrthreshold
Вывод всегда будет записываться в stderr независимо от его формата. Перенаправление вывода должно осуществляться компонентом, который вызывает компонент Kubernetes, например, POSIX-совместимой командной оболочкой или инструментом вроде systemd.
Иногда эти опции недоступны — например, в случае контейнера без дистрибутива (distroless) или системной службы Windows. Тогда kube-log-runner можно использовать в качестве обертки вокруг компонента Kubernetes для перенаправления вывода. Его предварительно собранный исполняемый файл включен в некоторые базовые образы Kubernetes под старым именем /go-runner, а в актуальных бинарных релизах архивов с kubernetes-server и kubernetes-node он называется kube-log-runner.
В таблице ниже показаны соответствия между вызовами kube-log-runner и логикой перенаправления командной оболочки:
| Использование |
Оболочка POSIX (например, Bash) |
kube-log-runner <options> <cmd> |
| Объединить stderr и stdout, вывести в stdout |
2>&1 |
kube-log-runner (default behavior) |
| Перенаправить оба потока в файл лога |
1>>/tmp/log 2>&1 |
kube-log-runner -log-file=/tmp/log |
| Скопировать в файл лога и в stdout |
2>&1 | tee -a /tmp/log |
kube-log-runner -log-file=/tmp/log -also-stdout |
| Перенаправить только stdout в файл лога |
>/tmp/log |
kube-log-runner -log-file=/tmp/log -redirect-stderr=false |
Вывод klog
Пример оригинального "родного" формата klog:
I1025 00:15:15.525108 1 httplog.go:79] GET /api/v1/namespaces/kube-system/pods/metrics-server-v0.3.1-57c75779f-9p8wg: (1.512ms) 200 [pod_nanny/v0.0.0 (linux/amd64) kubernetes/$Format 10.56.1.19:51756]
Сообщение может содержать переносы строк:
I1025 00:15:15.525108 1 example.go:79] This is a message
which has a line break.
Структурированное логирование
СТАТУС ФИЧИ: Kubernetes v1.23 [beta]
Предупреждение:
Переход на структурированное логирование — продолжающийся процесс. Не все сообщения структурированы в текущей версии Kubernetes. При парсинге файлов логов необходимо также обрабатывать неструктурированные сообщения.
Формат логов и сериализация значений могут измениться в будущем.
Структурированное логирование придает определенную структуру сообщениям логов, упрощая программное извлечение информации и сокращая затраты и усилия на их обработку. Код, который генерирует сообщение лога, определяет, используется ли обычный неструктурированный вывод klog или структурированное логирование.
По умолчанию структурированные сообщения форматируются как текст, при этом его формат обратно совместим с традиционным форматом klog:
<klog header> "<message>" <key1>="<value1>" <key2>="<value2>" ...
Пример:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
Строки заключаются в кавычки. Другие значения форматируются с помощью %+v. В результате сообщение может продолжиться на следующей строке в зависимости от типа данных.
I1025 00:15:15.525108 1 example.go:116] "Example" data="This is text with a line break\nand \"quotation marks\"." someInt=1 someFloat=0.1 someStruct={StringField: First line,
second line.}
Контекстное логирование
СТАТУС ФИЧИ: Kubernetes v1.24 [alpha]
Контекстное логирование базируется на структурированном логировании. Речь идет в первую очередь о том, как разработчики используют лог-вызовы: код, основанный на этой концепции, более гибок и поддерживает дополнительные сценарии использования (см. Contextual Logging KEP).
При использовании в компонентах дополнительных функций, таких как WithValues или WithName, записи лога содержат дополнительную информацию, которая передается в функции вызывающей стороной.
В настоящее время за включение контекстного логирования отвечает переключатель функционала StructuredLogging. По умолчанию оно отключено. Соответствующая инфраструктура появилась в версии 1.24 и она не потребовала изменений в компонентах. Команда component-base/logs/example показывает, как использовать новые лог-вызовы и как ведет себя компонент, поддерживающий контекстное логирование.
$ cd $GOPATH/src/k8s.io/kubernetes/staging/src/k8s.io/component-base/logs/example/cmd/
$ go run . --help
...
--feature-gates mapStringBool A set of key=value pairs that describe feature gates for alpha/experimental features. Options are:
AllAlpha=true|false (ALPHA - default=false)
AllBeta=true|false (BETA - default=false)
ContextualLogging=true|false (ALPHA - default=false)
$ go run . --feature-gates ContextualLogging=true
...
I0404 18:00:02.916429 451895 logger.go:94] "example/myname: runtime" foo="bar" duration="1m0s"
I0404 18:00:02.916447 451895 logger.go:95] "example: another runtime" foo="bar" duration="1m0s"
Префикс example и foo="bar" были добавлены вызовом функции, которая пишет в лог сообщение runtime и значение duration="1m0s", при этом вносить изменения в эту функцию не потребовалось.
При отключенном контекстном логировании WithValues и WithName ничего не делают, а вызовы журнала проходят через глобальный логгер klog. Соответственно, эта дополнительная информация более не отображается в логе:
$ go run . --feature-gates ContextualLogging=false
...
I0404 18:03:31.171945 452150 logger.go:94] "runtime" duration="1m0s"
I0404 18:03:31.171962 452150 logger.go:95] "another runtime" duration="1m0s"
Логи в формате JSON
СТАТУС ФИЧИ: Kubernetes v1.19 [alpha]
Предупреждение:
Вывод в формате JSON не поддерживает многие стандартные флаги klog. Список неподдерживаемых флагов klog см. в Справочнике по CLI.
Кроме того, запись в формате JSON не гарантируется (например, во время запуска процесса). Таким образом, если планируется дальнейший парсинг логов, убедитесь, что ваш парсер способен обрабатывать строки лога, которые не являются JSON.
Имена полей и сериализация JSON могут измениться в будущем.
Флаг --logging-format=json переключает формат логов с родного формата klog на JSON. Пример лога в формате JSON (стилистически отформатированном):
{
"ts": 1580306777.04728,
"v": 4,
"msg": "Pod status updated",
"pod":{
"name": "nginx-1",
"namespace": "default"
},
"status": "ready"
}
Специальные ключи:
ts — временная метка в формате времени Unix (обязательный параметр, float);v — детализация (для общей информации — не для сообщений об ошибках, int);err — ошибка (опциональный параметр, string);msg — сообщение (обязательный параметр, string).
Список компонентов, поддерживающих формат JSON:
Уровень детализации лога
Флаг -v задает степень детализации лога. Увеличение значения увеличивает количество регистрируемых событий. Уменьшение значения уменьшает количество регистрируемых событий. Увеличение детализации приводит к тому, что регистрируются все менее значимые события. При уровне детализации, равном 0, регистрируются только критические события.
Местоположение лога
Существует два типа системных компонентов: те, которые работают в контейнере, и те, которые работают за пределами контейнера. Например:
На машинах с systemd среда исполнения и kubelet пишут в journald. В противном случае ведется запись в файлы .log в директории /var/log. Системные компоненты внутри контейнеров всегда пишут в файлы .log в директории /var/log, обходя механизм логирования по умолчанию. Как и логи контейнеров, логи системных компонентов в /var/log нуждаются в ротации. В кластерах Kubernetes, созданных с использованием скрипта kube-up.sh, ротация логов настраивается с помощью инструмента logrotate. logrotate ротирует логи ежедневно или при достижении ими размера в 100 МБ.
Что дальше
6.6 - Типы прокси-серверов в Kubernetes
На этой странице рассказывается о различных типах прокси-серверов, которые используются в Kubernetes.
Прокси-серверы
При работе с Kubernetes можно столкнуться со следующими типами прокси-серверов:
-
kubectl:
- работает на локальной машине или в Pod'е;
- поднимает канал связи от локальной машины к интерфейсу API-сервера Kubernetes;
- данные от клиента к прокси-серверу передаются по HTTP;
- данные от прокси к серверу API передаются по HTTPS;
- отвечает за обнаружение сервера API;
- добавляет заголовки аутентификации.
-
Прокси-сервер API:
- бастион, встроенный в API-сервер;
- подключает пользователя за пределами кластера к IP-адресам кластера, которые в ином случае могут оказаться недоступными;
- входит в процессы сервера API;
- данные от клиента к прокси-серверу передаются по HTTPS (или по HTTP, если сервер API настроен соответствующим образом);
- данные от прокси-сервера к цели передаются по HTTP или HTTPS в зависимости от настроек прокси;
- используется для доступа к узлам, Pod'ам или сервисам;
- при подключении к сервису выступает балансировщиком нагрузки.
-
kube proxy:
- работает на каждом узле;
- обрабатывает трафик UDP, TCP и SCTP;
- "не понимает" HTTP;
- выполняет функции балансировщика нагрузки;
- используется только для доступа к сервисам.
-
Прокси-сервер/балансировщик нагрузки перед API-сервером(-ами):
- наличие и тип (например, nginx) определяется конфигурацией кластера;
- располагается между клиентами и одним или несколькими серверами API;
- балансирует запросы при наличии нескольких серверов API.
-
Облачные балансировщики нагрузки на внешних сервисах:
- предоставляются некоторыми облачными провайдерами (например, AWS ELB, Google Cloud Load Balancer);
- создаются автоматически для сервисов Kubernetes с типом
LoadBalancer;
- как правило, поддерживают только UDP/TCP;
- наличие поддержки SCTP зависит от реализации балансировщика нагрузки облачного провайдера;
- реализация варьируется в зависимости от поставщика облачных услуг.
Пользователи Kubernetes, как правило, в своей работе сталкиваются только с прокси-серверами первых двух типов. За настройку остальных типов обычно отвечает администратор кластера.
Запросы на перенаправления
На смену функциям перенаправления (редиректам) пришли прокси-серверы. Перенаправления устарели.
6.7 - Равноправный доступ к API
СТАТУС ФИЧИ: Kubernetes v1.20 [beta]
Контроль за поведением API-сервера Kubernetes в условиях высокой нагрузки — ключевая задача для администраторов кластера. В kube-apiserver имеются некоторые механизмы управления (например, флаги командной строки --max-requests-inflight и --max-mutating-requests-inflight) для ограничения нагрузки на сервер. Они предотвращают наплыв входящих запросов и потенциальный отказ сервера API, но не позволяют гарантировать прохождение наиболее важных запросов в периоды высокой нагрузки.
Функция регулирования приоритета и обеспечения равноправного доступа к API (API Priority and Fairness), или РДА, — отличная альтернатива флагам. Она оптимизирует вышеупомянутые ограничения на максимальное количество запросов. РДА тщательнее классифицирует запросы и изолирует их. Также она поддерживает механизм очередей, который помогает обрабатывать запросы при краткосрочных всплесках нагрузки. Отправка запросов из очередей осуществляется на основе метода организации равноправных очередей, поэтому плохо работающий контроллер не будет мешать работе других (даже с аналогичным уровнем приоритета).
Эта функция предназначена для корректной работы со стандартными контроллерами, которые используют информеры и реагируют на неудачные API-запросы, экспоненциально увеличивая выдержку (back-off) между ними, а также клиентами, устроенными аналогичным образом.
Внимание:
Запросы, отнесенные к категории "long-running" — в первую очередь следящие, — не подпадают под действие фильтра функции равноправного доступа к API. Это также верно для флага --max-requests-inflight без включенной функции РДА.
Включение/отключение равноправного доступа к API
Управление РДА осуществляется с помощью переключателя функционала (feature gate); по умолчанию функция включена. В разделе Переключатели функционала приведено их общее описание и способы включения/отключения. В случае РДА соответствующий переключатель называется "APIPriorityAndFairness". Данная функция также включает группу API, при этом: (a) версия v1alpha1 по умолчанию отключена, (b) версии v1beta1 и v1beta2 по умолчанию включены. Чтобы отключить РДА и бета-версии групп API, добавьте следующие флаги командной строки в вызов kube-apiserver:
kube-apiserver \
--feature-gates=APIPriorityAndFairness=false \
--runtime-config=flowcontrol.apiserver.k8s.io/v1beta1=false,flowcontrol.apiserver.k8s.io/v1beta2=false \
# …и остальные флаги, как обычно
Кроме того, версию v1alpha1 группы API можно включить с помощью --runtime-config=flowcontrol.apiserver.k8s.io/v1alpha1=true.
Флаг командной строки --enable-priority-and-fairness=false отключит функцию равноправного доступа к API, даже если другие флаги ее активировали.
Основные понятия
Функция равноправного доступа к API в своей работе использует несколько базовых понятий/механизмов. Входящие запросы классифицируются по атрибутам с помощью т.н. FlowSchemas, после чего им присваиваются уровни приоритета. Уровни приоритета обеспечивают некоторую степень изоляции, обеспечивая различные пределы параллелизма, предотвращая влияние запросов с разными уровнями приоритета друг на друга. В пределах одного приоритета алгоритм равнодоступного формирования очереди предотвращает взаимное влияние запросов из разных потоков и формирует очередь запросов, снижая число неудачных запросов во время всплесков трафика при приемлемо низкой средней нагрузке.
Уровни приоритета
Без включенного равноправного доступа к API управление общим параллелизмом в API-сервере осуществляется флагами --max-requests-inflight и --max-mutating-requests-inflight для kube-apiserver. При включенном равноправном доступе к API пределы параллелизма, заданные этими флагами, суммируются, а затем сумма распределяется по настраиваемому набору уровней приоритета. Каждому входящему запросу присваивается определенный уровень приоритета, причем каждый уровень приоритета может отправлять только такое количество параллельных запросов, которое прописано в его конфигурации.
Конфигурация по умолчанию, например, предусматривает отдельные уровни приоритета для запросов на выборы лидера, запросов от встроенных контроллеров и запросов от Pod'ов. Это означает, что Pod, ведущий себя некорректно и переполняющий API-сервер запросами, не сможет помешать выборам лидера или оказать влияние на действия встроенных контроллеров.
Очереди
Каждый уровень приоритета может включать большое количество различных источников трафика. Во время перегрузки важно предотвратить негативное влияние одного потока запросов на остальные (например, в идеале один сбойный клиент, переполняющий kube-apiserver своими запросами, не должен оказывать заметного влияния на других клиентов). Для этого при обработке запросов с одинаковым уровнем приоритета используется алгоритм равнодоступной очереди. Каждый запрос приписывается к потоку, который идентифицируется по имени соответствующей FlowSchema и дифференциатору потока: пользователю-источнику запроса, пространству имен целевого ресурса или пустым значением. Система старается придать примерно равный вес запросам в разных потоках с одинаковым уровнем приоритета.
Для раздельной обработки различных инстансов контроллеры с большим их числом должны аутентифицироваться под разными именами пользователей.
Распределив запрос в некоторый поток, РДА приписывает его к очереди. Этот процесс базируется на методе, известном как shuffle sharding (тасование между шардами), который относительно эффективно изолирует потоки низкой интенсивности от потоков высокой интенсивности с помощью очередей.
Параметры алгоритма постановки в очередь можно настраивать для каждого уровня приоритетов. В результате администратор может выбирать между использованием памяти, равнодоступностью (свойством, которое обеспечивает продвижение независимых потоков, когда совокупный трафик превышает пропускную способность), толерантностью к всплескам трафика и дополнительной задержкой, вызванной постановкой в очередь.
Запросы-исключения
Некоторые запросы считаются настолько важными, что на них не распространяется ни одно из ограничений, налагаемых этой функцией. Механизм исключений не позволяет ошибочно настроенной конфигурации управления потоком полностью вывести сервер API из строя.
Ресурсы
API управления потоками включает в себя два вида ресурсов. PriorityLevelConfigurations определяет доступные классы изоляции, долю доступного бюджета параллелизма, которая выделяется для каждого класса, и позволяет выполнять тонкую настройку работы с очередями. FlowSchema используется для классификации отдельных входящих запросов, сопоставляя каждый из них с одной из конфигураций PriorityLevelConfiguration. Кроме того, существует версия v1alpha1 данной группы API, с аналогичными Kinds с теми же синтаксисом и семантикой.
PriorityLevelConfiguration
PriorityLevelConfiguration представляет отдельный класс изоляции. У каждой конфигурации PriorityLevelConfiguration имеется независимый предел на количество активных запросов и ограничения на число запросов в очереди.
Пределы параллелизма для PriorityLevelConfigurations указываются не в виде абсолютного количества запросов, а в виде "долей параллелизма" (concurrency shares). Совокупный объем ресурсов API-сервера, доступных для параллелизма, распределяется между существующими PriorityLevelConfigurations пропорционально этим долям. Администратор кластера может увеличить или уменьшить совокупный объем трафика на сервер, просто перезапустив kube-apiserver с другим значением --max-requests-inflight (или --max-mutating-requests-inflight). В результате пропускная способность каждой PriorityLevelConfigurations возрастет (или снизится) соразмерно ее доле.
Внимание:
При включенной функции Priority and Fairness суммарный предел параллелизма для сервера равен сумме --max-requests-inflight и --max-mutating-requests-inflight. При этом мутирующие и не мутирующие запросы рассматриваются вместе; чтобы обрабатывать их независимо для некоторого ресурса, создайте отдельные FlowSchemas для мутирующих и не мутирующих действий (verbs).
Поле type спецификации PriorityLevelConfiguration определяет судьбу избыточных запросов, когда их объем, отнесенный к одной PriorityLevelConfiguration, превышает ее допустимый уровень параллелизма. Тип Reject означает, что избыточный трафик будет немедленно отклонен с ошибкой HTTP 429 (Too Many Requests). Тип Queue означает, что запросы, превышающие пороговое значение, будут поставлены в очередь, при этом для балансировки прогресса между потоками запросов будут использоваться методы тасования между шардами и равноправных очередей.
Конфигурация очередей позволяет настроить алгоритм равноправных очередей для каждого уровня приоритета. Подробности об алгоритме можно узнать из предложения по улучшению; если вкратце:
-
Увеличение queues снижает количество конфликтов между различными потоками за счет повышенного использования памяти. При единице логика равнодоступной очереди отключается, но запросы все равно могут быть поставлены в очередь.
-
Увеличение длины очереди (queueLengthLimit) позволяет выдерживать большие всплески трафика без потери запросов за счет увеличения задержек и повышенного потребления памяти.
-
Изменение handSize позволяет регулировать вероятность конфликтов между различными потоками и общий параллелизм, доступный для одного потока в условиях чрезмерной нагрузки.
Примечание:
Больший handSize снижает вероятность конфликта двух отдельных потоков (и, следовательно, вероятность того, что один из них подавит другой), но повышает вероятность того, что малое число потоков загрузят API-сервер. Больший handSize также потенциально увеличивает задержку, которую может вызвать один поток с высоким трафиком. Максимальное возможное количество запросов в очереди от одного потока равно handSize * queueLengthLimit.
Ниже приведена таблица с различными конфигурациями, показывающая вероятность того, что "мышь" (поток низкой интенсивности) будет раздавлена "слонами" (потоками высокой интенсивности) в зависимости от числа "слонов" при тасовании потоков между шардами. Скрипт для расчета таблицы доступен по ссылке.
Конфигурации shuffle sharding
handSize |
Число очередей |
1 слон |
4 слона |
16 слонов |
| 12 |
32 |
4.428838398950118e-09 |
0.11431348830099144 |
0.9935089607656024 |
| 10 |
32 |
1.550093439632541e-08 |
0.0626479840223545 |
0.9753101519027554 |
| 10 |
64 |
6.601827268370426e-12 |
0.00045571320990370776 |
0.49999929150089345 |
| 9 |
64 |
3.6310049976037345e-11 |
0.00045501212304112273 |
0.4282314876454858 |
| 8 |
64 |
2.25929199850899e-10 |
0.0004886697053040446 |
0.35935114681123076 |
| 8 |
128 |
6.994461389026097e-13 |
3.4055790161620863e-06 |
0.02746173137155063 |
| 7 |
128 |
1.0579122850901972e-11 |
6.960839379258192e-06 |
0.02406157386340147 |
| 7 |
256 |
7.597695465552631e-14 |
6.728547142019406e-08 |
0.0006709661542533682 |
| 6 |
256 |
2.7134626662687968e-12 |
2.9516464018476436e-07 |
0.0008895654642000348 |
| 6 |
512 |
4.116062922897309e-14 |
4.982983350480894e-09 |
2.26025764343413e-05 |
| 6 |
1024 |
6.337324016514285e-16 |
8.09060164312957e-11 |
4.517408062903668e-07 |
FlowSchema
FlowSchema сопоставляется со входящими запросами; по результатам данного действия тем приписывается определенный уровень приоритета. Каждый входящий запрос по очереди проверяется на соответствие каждой FlowSchema, начиная с тех, у которых наименьшее численное значение matchingPrecedence (т.е., логически наивысший приоритет). Проверка ведется до первого совпадения.
Внимание:
Учитывается только первая подходящая FlowSchema для данного запроса. Если одному входящему запросу соответствует несколько FlowSchemas, он попадет в ту, у которой наивысший matchingPrecedence. Если несколько FlowSchema с одинаковым matchingPrecedence соответствуют одному запросу, предпочтение будет отдано той, у которой лексикографически меньшее имя (name). Впрочем, лучше не полагаться на это, а убедиться, что matchingPrecedence уникален для всех FlowSchema.
Схема FlowSchema подходит определенному запросу, если хотя бы одно из ее правил (rules) подходит ему. В свою очередь, правило соответствует запросу, если ему соответствует хотя бы один из его субъектов (subjects) и хотя бы одно из его правил resourceRules или nonResourceRules (в зависимости от того, является ли входящий запрос ресурсным или нересурсным URL).
Для поля name в субъектах (subjects) и полей verbs, apiGroups, resources, namespaces и nonResourceURLs в ресурсных и нересурсных правилах может быть указан универсальный символ *, который будет соответствовать всем значениям для данного поля, фактически исключая его из рассмотрения.
Параметр distinguisherMethod.type схемы FlowSchema определяет, как запросы, соответствующие этой схеме, будут разделяться на потоки. Он может быть либо ByUser (в этом случае один запрашивающий пользователь не сможет лишить других пользователей ресурсов), либо ByNamespace (в этом случае запросы на ресурсы в одном пространстве имен не смогут помешать запросам на ресурсы в других пространствах имен), либо он может быть пустым (или distinguisherMethod может быть опущен) (в этом случае все запросы, соответствующие данной FlowSchema, будут считаться частью одного потока). Правильный выбор для определенной FlowSchema зависит от ресурса и конкретной среды.
Значения по умолчанию
kube-apiserver поддерживает два вида объектов конфигурации РДА: обязательные и рекомендуемые.
Обязательные объекты конфигурации
Четыре обязательных объекта конфигурации отражают защитное поведение, встроенное в серверы. Оно реализуется независимо от этих объектов; параметры последних просто его отражают.
-
Обязательный уровень приоритета exempt используется для запросов, которые вообще не подчиняются контролю потока: они всегда будут доставляться немедленно. Обязательная FlowSchema exempt относит к этому уровню приоритета все запросы из группы system:masters. При необходимости можно задать другие FlowSchemas, которые будут наделять другие запросы данным уровнем приоритета.
-
Обязательный уровень приоритета catch-all используется в сочетании с обязательной FlowSchema catch-all, гарантируя, что каждый запрос получит какую-либо классификацию. Как правило, полагаться на эту универсальную конфигурацию не следует. Рекомендуется создать свои собственные универсальные FlowSchema и PriorityLevelConfiguration (или использовать опциональный уровень приоритета global-default, доступный по умолчанию). Поскольку предполагается, что обязательный уровень приоритета catch-all будет использоваться редко, его доля параллелизма невысока, кроме того, он не ставит запросы в очередь.
Опциональные объекты конфигурации
Опциональные объекты FlowSchemas и PriorityLevelConfigurations образуют оптимальную конфигурацию по умолчанию. При желании их можно изменить и/или создать дополнительные объекты конфигурации. Если велика вероятность высокой нагрузки на кластер, следует решить, какая конфигурация будет работать лучше всего.
Опциональная конфигурация группирует запросы по шести уровням приоритета:
-
Уровень приоритета node-high предназначен для проверки здоровья узлов.
-
Уровень приоритета system предназначен для запросов от группы system:nodes, не связанных с состоянием узлов, а именно: от kubelet'ов, которые должны иметь возможность связываться с сервером API для планирования рабочих нагрузок.
-
Уровень приоритета leader-election предназначен для запросов на выборы лидера от встроенных контроллеров (в частности, запросы на объекты типа Endpoint, ConfigMap или Lease, поступающие от пользователей system:kube-controller-manager или system:kube-scheduler и служебных учетных записей в пространстве имен kube-system). Их важно изолировать от другого трафика, поскольку сбои при выборе лидеров приводят к перезагрузкам контроллеров. Соответственно, новые контроллеры потребляют трафик, синхронизируя свои информеры.
-
Уровень приоритета workload-high предназначен для прочих запросов от встроенных контроллеров.
-
Уровень приоритета workload-low предназначен для запросов от остальных учетных записей служб, которые обычно включают все запросы от контроллеров, работающих в Pod'ах.
-
Уровень приоритета global-default обрабатывает весь остальной трафик, например, интерактивные команды kubectl, выполняемые непривилегированными пользователями.
Опциональные FlowSchemas служат для направления запросов на вышеуказанные уровни приоритета и здесь не перечисляются.
Обслуживание обязательных и опциональных объектов конфигурации
Каждый kube-apiserver самостоятельно обслуживает обязательные и опциональные объекты конфигурации, используя стратегию начальных/периодических проходов. Таким образом, в ситуации с серверами разных версий может возникнуть пробуксовка (thrashing) из-за разного представления серверов о правильном содержании этих объектов.
Каждый kube-apiserver выполняет начальный проход по обязательным и опциональным объектам конфигурации, а затем периодически (раз в минуту) обходит их.
Для обязательных объектов обслуживание заключается в проверке того, что объект существует и имеет надлежащую спецификацию (spec). Сервер не разрешает создавать или обновлять объекты со spec, которая не соответствует его защитному поведению.
Обслуживание опциональных объектов конфигурации предусматривает возможность переопределения их спецификации (spec). Кроме того, удаление носит непостоянный характер: объект будет восстановлен в процессе обслуживания. Если опциональный объект конфигурации не нужен, его не нужно удалять, но достаточно настроить spec'и так, чтобы последствия были минимальными. Обслуживание опциональных объектов также рассчитано на поддержку автоматической миграции при выходе новой версии kube-apiserver, при этом вероятны конфликты (thrashing), пока группировка серверов остается смешанной.
Обслуживание опционального объекта конфигурации предусматривает его создание — с рекомендуемой спецификацией сервера — если тот не существует. В то же время, если объект уже существует, поведение при обслуживании зависит от того, кто им управляет — kube-apiserver'ы или пользователи. В первом случае сервер гарантирует, что спецификация объекта соответствует рекомендуемой; во втором случае спецификация не анализируется.
Чтобы узнать, кто управляет объектом, необходимо найти аннотацию с ключом apf.kubernetes.io/autoupdate-spec. Если такая аннотация существует и ее значение равно true, то объект контролируется kube-apiserver'ами. Если аннотация существует и ее значение равно false, объект контролируется пользователями. Если ни одно из этих условий не выполняется, выполняется обращение к metadata.generation объекта. Если этот параметр равен 1, объект контролируется kube-apiserver'ами. В противном случае объект контролируют пользователи. Эти правила были введены в версии 1.22, и использование metadata.generation обусловлено переходом от более простого предыдущего поведения. Пользователи, желающие контролировать опциональный объект конфигурации, должны убедиться, что его аннотация apf.kubernetes.io/autoupdate-spec имеет значение false.
Обслуживание обязательного или опционального объекта конфигурации также предусматривает проверку наличия у него аннотации apf.kubernetes.io/autoupdate-spec, которая позволяет понять, контролируют ли его kube-apiserver'ы.
Обслуживание также предусматривает удаление объектов, которые не являются ни обязательными, ни опциональными, но имеют аннотацию apf.kubernetes.io/autoupdate-spec=true.
Освобождение проверок работоспособности от параллелизма
Опциональная конфигурация не предусматривает особого отношения к health check-запросам на kube-apiserver'ы от их локальных kubelet'ов. В данном случае обычно используется защищенный порт, но учетные данные не передаются. В опциональной конфигурации такие запросы относятся к FlowSchema global-default и соответствующему уровню приоритета global-default, где другой трафик может мешать их прохождению.
Чтобы освободить такие запросы от частотных ограничений, можно добавить FlowSchema, приведенную ниже.
Внимание:
Добавление данной FlowSchema позволит злоумышленникам отправлять удовлетворяющие ей health-check-запросы в любом количестве. При наличии фильтра веб-трафика или аналогичного внешнего механизма безопасности для защиты API-сервера кластера от интернет-трафика можно настроить правила для блокировки любых health-check-запросов, поступающих из-за пределов кластера.
apiVersion: flowcontrol.apiserver.k8s.io/v1beta3
kind: FlowSchema
metadata:
name: health-for-strangers
spec:
matchingPrecedence: 1000
priorityLevelConfiguration:
name: exempt
rules:
- nonResourceRules:
- nonResourceURLs:
- "/healthz"
- "/livez"
- "/readyz"
verbs:
- "*"
subjects:
- kind: Group
group:
name: system:unauthenticated
Диагностика
Каждый HTTP-ответ от сервера API с включенной функцией РДА содержит два дополнительных заголовка: X-Kubernetes-PF-FlowSchema-UID и X-Kubernetes-PF-PriorityLevel-UID. В них указываются схема потока и уровень приоритета соответственно. Имена объектов API не включаются в эти заголовки на случай, если запрашивающий пользователь не обладает правами на их просмотр, поэтому при отладке можно использовать команду типа:
kubectl get flowschemas -o custom-columns="uid:{metadata.uid},name:{metadata.name}"
kubectl get prioritylevelconfigurations -o custom-columns="uid:{metadata.uid},name:{metadata.name}"
чтобы привязать UID к именам для FlowSchemas и PriorityLevelConfigurations.
Наблюдаемость
Метрики
Примечание:
В Kubernetes до версии v1.20 лейблы flow_schema и priority_level также могли называться flowSchema и priorityLevel, соответственно. При использовании Kubernetes v1.19 и более ранних версий обратитесь к документации для соответствующей версии.
При включении функции равноправного доступа к API kube-apiserver начинает экспортировать дополнительные метрики. Их мониторинг помогает выявить негативное влияние (throttling) текущей конфигурации на важный трафик или найти неэффективные рабочие нагрузки, которые вредят здоровью системы.
-
apiserver_flowcontrol_rejected_requests_total — вектор-счетчик (кумулятивный с момента запуска сервера) запросов, которые были отклонены, с разбивкой по лейблам flow_schema (указывает на FlowSchema у запросов, попавших под соответствие), priority_level (уровень приоритета, который был присвоен этим запросам) и reason. Лейбл reason будет иметь одно из следующих значений:
queue-full — в очереди уже слишком много запросов;concurrency-limit — PriorityLevelConfiguration настроена на отклонение, а не на постановку в очередь избыточных запросов;time-out — запрос все еще находился в очереди, когда истек его лимит ожидания.
-
apiserver_flowcontrol_dispatched_requests_total — вектор-счетчик (кумулятивный с момента запуска сервера) запросов, которые начали выполняться, сгруппированный по лейблам flow_schema (указывает на FlowSchema у запросов, попавших под соответствие) и priority_level (уровень приоритета, который был присвоен этим запросам).
-
apiserver_current_inqueue_requests — вектор предыдущего максимума числа запросов в очереди, сгруппированных по лейблу request_kind, значение которого mutating или readOnly. Эти максимумы описывают наибольшее число, наблюдавшееся в последнем завершенном односекундном окне. Они дополняют более старый вектор apiserver_current_inflight_requests, который показывает максимум активно обслуживаемых запросов в последнем окне.
-
apiserver_flowcontrol_read_vs_write_request_count_samples — вектор-гистограмма наблюдений за тогда-текущим количеством запросов с разбивкой по лейблам phase (принимает значения waiting и executing) и request_kind (принимает значения mutating и readOnly). Наблюдения проводятся периодически с высокой частотой. Каждое наблюдаемое значение представляет собой число в диапазоне от 0 до 1, равное отношению числа запросов к соответствующему ограничению на их количество (ограничение длины очереди в случае ожидания и лимит параллелизма в случае выполнения).
-
apiserver_flowcontrol_read_vs_write_request_count_watermarks — вектор-гистограмма максимумов или минимумов количества запросов (число запросов, деленное на соответствующее ограничение) с разбивкой по лейблам phase (принимает значения waiting и executing) и request_kind (принимает значения mutating и readOnly); лейбл mark принимает значения high и low. Минимумы и максимумы собираются в окнах, ограниченных временем, когда наблюдение было добавлено в apiserver_flowcontrol_read_vs_write_request_count_samples. Эти экстремумы помогают определить разброс диапазона значений, наблюдавшийся в разных сэмплах.
-
apiserver_flowcontrol_current_inqueue_requests — gauge-вектор, содержащий количество стоящих в очереди (не выполняющихся) запросов в каждый момент с разбивкой по лейблам priority_level и flow_schema.
-
apiserver_flowcontrol_current_executing_requests — gauge-вектор, содержащий количество исполняемых (не ожидающих в очереди) запросов в каждый момент с разбивкой по лейблам priority_level и flow_schema.
-
apiserver_flowcontrol_request_concurrency_in_use — gauge-вектор, содержащий количество занятых мест в каждый момент с разбивкой по лейблам priority_level и flow_schema.
-
apiserver_flowcontrol_priority_level_request_count_samples — вектор-гистограмма наблюдений за текущим-на-тот-момент количеством запросов с разбивкой по лейблам phase (принимает значения waiting и executing) и priority_level. Каждая гистограмма получает наблюдения, сделанные периодически, вплоть до последней активности соответствующего рода. Наблюдения проводятся с высокой частотой. Каждое наблюдаемое значение представляет собой число в диапазоне от 0 до 1, равное отношению числа запросов к соответствующему ограничению на их количество (ограничение длины очереди в случае ожидания и лимит параллелизма в случае выполнения).
-
apiserver_flowcontrol_priority_level_request_count_watermarks — вектор-гистограмма максимумов или минимумов количества запросов с разбивкой по лейблам phase (принимает значения waiting и executing) и priority_level; лейбл mark принимает значения high и low. Минимумы и максимумы собираются в окнах, ограниченных временем, когда наблюдение было добавлено в apiserver_flowcontrol_priority_level_request_count_samples. Эти экстремумы показывают диапазон значений, наблюдавшийся в разных сэмплах.
-
apiserver_flowcontrol_priority_level_seat_count_samples — вектор-гистограмма наблюдений за использованием лимита параллелизма для уровня приоритета с разбивкой по priority_level. Использование — отношение (количество занятых мест) / (предел параллелизма). Метрика учитывает все стадии выполнения (как обычную, так и дополнительную задержку в конце записи для покрытия соответствующей работы по уведомлению) всех запросов, кроме WATCHes; для этих запросов учитывается только начальная стадия по доставке уведомлений о ранее существующих объектах. Каждая гистограмма в векторе также помечена лейблом phase: executing (количество мест для фазы ожидания не ограничено). Каждая гистограмма получает наблюдения, сделанные периодически, вплоть до последней активности соответствующего рода. Наблюдения производятся с высокой частотой.
-
apiserver_flowcontrol_priority_level_seat_count_watermarks — вектор-гистограмма минимумов и максимумов использования предела параллелизма для уровня приоритета с разбивкой по priority_leve и mark (принимает значения high и low). Каждая гистограмма в векторе также помечена лейблом phase: executing (для фазы ожидания предел на места отсутствует). Максимумы и минимумы собираются в окнах, ограниченных временем, когда наблюдение было добавлено в apiserver_flowcontrol_priority_level_seat_count_samples. Эти экстремумы помогают определить разброс диапазона значений, наблюдавшийся в разных сэмплах.
-
apiserver_flowcontrol_request_queue_length_after_enqueue — вектор-гистограмма длины очереди для очередей с разбивкой по лейблам priority_level и flow_schema как выборки по поставленным в очередь запросам. Каждый запрос при постановке в очередь вносит один сэмпл в гистограмму, сообщая о длине очереди сразу после добавления запроса. Обратите внимание, что это дает иную статистику, чем при объективном исследовании.
Примечание:
В данном случае выброс в гистограмме означает, что, скорее всего, один поток (т.е. запросы от одного пользователя или для одного пространства имен, в зависимости от конфигурации) переполняет сервер API и "срезается" (throttled). И наоборот, если гистограмма одного уровня приоритета показывает, что все очереди для этого уровня приоритета длиннее, чем для других уровней приоритета, возможно, следует увеличить долю параллелизма для этого уровня приоритета в PriorityLevelConfiguration.
-
apiserver_flowcontrol_request_concurrency_limit — gauge-вектор, содержащий вычисленный лимит параллелизма (основанный на общем лимите параллелизма сервера API и долях параллелизма PriorityLevelConfigurations), с разбивкой по лейблу priority_level.
-
apiserver_flowcontrol_request_wait_duration_seconds — вектор-гистограмма времени ожидания запросов в очереди с разбивкой по лейблам flow_schema (указывает, какая схема соответствует запросу), priority_level (указывает, к какому уровню был отнесен запрос) и execute (указывает, начал ли запрос выполняться).
Примечание:
Поскольку каждая FlowSchema всегда относит запросы к одному PriorityLevelConfiguration, можно сложить гистограммы для всех FlowSchema для одного уровня приоритета, чтобы получить эффективную гистограмму для запросов, отнесенных к этому уровню приоритета.
-
apiserver_flowcontrol_request_execution_seconds — вектор-гистограмма времени, затраченного на выполнение запросов, с разбивкой по по лейблам flow_schema (указывает, какая схема соответствует запросу) и priority_level (указывает, к какому уровню был отнесен запрос).
-
apiserver_flowcontrol_watch_count_samples — вектор-гистограмма количества активных запросов WATCH, относящихся к данной записи, с разбивкой по flow_schema и priority_level.
-
apiserver_flowcontrol_work_estimated_seats — вектор-гистограмма количества предполагаемых мест (максимум начального и конечного этапа выполнения), связанных с запросами, с разбивкой по flow_schema и priority_level.
-
apiserver_flowcontrol_request_dispatch_no_accommodation_total — вектор-счетчик количества событий, которые в принципе могли бы привести к отправке запроса, но не привели из-за отсутствия доступного параллелизма, с разбивкой по flow_schema и priority_level. Соответствующими событиями являются поступление запроса и завершение запроса.
Отладочные endpoint'ы
При включении функции равноправного доступа к API kube-apiserver предоставляет следующие дополнительные пути на своих HTTP[S]-портах.
-
/debug/api_priority_and_fairness/dump_priority_levels — список всех уровней приоритета и текущее состояние каждого из них. Получить его можно следующим образом:
kubectl get --raw /debug/api_priority_and_fairness/dump_priority_levels
Вывод выглядит примерно так:
PriorityLevelName, ActiveQueues, IsIdle, IsQuiescing, WaitingRequests, ExecutingRequests,
workload-low, 0, true, false, 0, 0,
global-default, 0, true, false, 0, 0,
exempt, <none>, <none>, <none>, <none>, <none>,
catch-all, 0, true, false, 0, 0,
system, 0, true, false, 0, 0,
leader-election, 0, true, false, 0, 0,
workload-high, 0, true, false, 0, 0,
-
/debug/api_priority_and_fairness/dump_queues — список всех очередей и их текущее состояние. Получить его можно следующим образом:
kubectl get --raw /debug/api_priority_and_fairness/dump_queues
Вывод выглядит примерно так:
PriorityLevelName, Index, PendingRequests, ExecutingRequests, VirtualStart,
workload-high, 0, 0, 0, 0.0000,
workload-high, 1, 0, 0, 0.0000,
workload-high, 2, 0, 0, 0.0000,
...
leader-election, 14, 0, 0, 0.0000,
leader-election, 15, 0, 0, 0.0000,
-
/debug/api_priority_and_fairness/dump_requests — список всех запросов, которые в настоящее время ожидают в очереди. Получить его можно следующим образом:
kubectl get --raw /debug/api_priority_and_fairness/dump_requests
Вывод выглядит примерно так:
PriorityLevelName, FlowSchemaName, QueueIndex, RequestIndexInQueue, FlowDistingsher, ArriveTime,
exempt, <none>, <none>, <none>, <none>, <none>,
system, system-nodes, 12, 0, system:node:127.0.0.1, 2020-07-23T15:26:57.179170694Z,
В дополнение к запросам, стоящим в очереди, вывод включает одну фантомную строку для каждого уровня приоритета, на которую не распространяется ограничение.
Более подробный список можно получить с помощью следующей команды:
kubectl get --raw '/debug/api_priority_and_fairness/dump_requests?includeRequestDetails=1'
Вывод выглядит примерно так:
PriorityLevelName, FlowSchemaName, QueueIndex, RequestIndexInQueue, FlowDistingsher, ArriveTime, UserName, Verb, APIPath, Namespace, Name, APIVersion, Resource, SubResource,
system, system-nodes, 12, 0, system:node:127.0.0.1, 2020-07-23T15:31:03.583823404Z, system:node:127.0.0.1, create, /api/v1/namespaces/scaletest/configmaps,
system, system-nodes, 12, 1, system:node:127.0.0.1, 2020-07-23T15:31:03.594555947Z, system:node:127.0.0.1, create, /api/v1/namespaces/scaletest/configmaps,
Что дальше
Для получения подробной информации о функции равноправного доступа к API см. предложение по улучшению (KEP). Предложения и запросы функционала принимаются через SIG API Machinery или в специализированном канале Slack.
6.8 - Установка дополнений
Примечание: Этот раздел ссылается на сторонние проекты, реализующие функциональность, которая требуется Kubernetes. Авторы Kubernetes не несут ответственность за проекты, представленные здесь в алфавитном порядке. Чтобы добавить проект к этому списку, ознакомьтесь с
руководством по контенту перед публикацией изменений.
Подробнее.
Надстройки расширяют функциональность Kubernetes.
На этой странице перечислены некоторые из доступных надстроек и ссылки на соответствующие инструкции по установке.
Сеть и сетевая политика
- ACI обеспечивает интегрированную сеть контейнеров и сетевую безопасность с помощью Cisco ACI.
- Antrea работает на уровне 3, обеспечивая сетевые службы и службы безопасности для Kubernetes, используя Open vSwitch в качестве уровня сетевых данных.
- Calico Calico поддерживает гибкий набор сетевых опций, поэтому вы можете выбрать наиболее эффективный вариант для вашей ситуации, включая сети без оверлея и оверлейные сети, с или без BGP. Calico использует тот же механизм для обеспечения соблюдения сетевой политики для хостов, модулей и (при использовании Istio и Envoy) приложений на уровне сервисной сети (mesh layer).
- Canal объединяет Flannel и Calico, обеспечивая сеть и сетевую политику.
- Cilium - это плагин сети L3 и сетевой политики, который может прозрачно применять политики HTTP/API/L7. Поддерживаются как режим маршрутизации, так и режим наложения/инкапсуляции, и он может работать поверх других подключаемых модулей CNI.
- CNI-Genie позволяет Kubernetes легко подключаться к выбору плагинов CNI, таких как Calico, Canal, Flannel, Romana или Weave.
- Contrail, основан на Tungsten Fabric, представляет собой платформу для виртуализации мультиоблачных сетей с открытым исходным кодом и управления политиками. Contrail и Tungsten Fabric интегрированы с системами оркестрации, такими как Kubernetes, OpenShift, OpenStack и Mesos, и обеспечивают режимы изоляции для виртуальных машин, контейнеров/подов и рабочих нагрузок без операционной системы.
- Flannel - это поставщик оверлейной сети, который можно использовать с Kubernetes.
- Knitter - это плагин для поддержки нескольких сетевых интерфейсов Kubernetes подов.
- Multus - это плагин Multi для работы с несколькими сетями в Kubernetes, который поддерживает большинство самых популярных CNI (например: Calico, Cilium, Contiv, Flannel), в дополнение к рабочим нагрузкам основанных на SRIOV, DPDK, OVS-DPDK и VPP в Kubernetes.
- OVN-Kubernetes - это сетевой провайдер для Kubernetes основанный на OVN (Open Virtual Network), реализация виртуальной сети, появившийся в результате проекта Open vSwitch (OVS). OVN-Kubernetes обеспечивает сетевую реализацию на основе наложения для Kubernetes, включая реализацию балансировки нагрузки и сетевой политики на основе OVS.
- OVN4NFV-K8S-Plugin - это подключаемый модуль контроллера CNI на основе OVN для обеспечения облачной цепочки сервисных функций (SFC), несколько наложенных сетей OVN, динамического создания подсети, динамического создания виртуальных сетей, сети поставщика VLAN, сети прямого поставщика и подключаемого к другим Multi Сетевые плагины, идеально подходящие для облачных рабочих нагрузок на периферии в сети с несколькими кластерами.
- NSX-T плагин для контейнера (NCP) обеспечивающий интеграцию между VMware NSX-T и контейнерами оркестраторов, таких как Kubernetes, а так же интеграцию между NSX-T и контейнеров на основе платформы CaaS/PaaS, таких как Pivotal Container Service (PKS) и OpenShift.
- Nuage - эта платформа SDN, которая обеспечивает сетевое взаимодействие на основе политик между Kubernetes подами и не Kubernetes окружением, с отображением и мониторингом безопасности.
- Romana - это сетевое решение уровня 3 для сетей подов, которое также поддерживает NetworkPolicy API. Подробности установки Kubeadm доступны здесь.
- Weave Net предоставляет сеть и обеспечивает сетевую политику, будет работать на обеих сторонах сетевого раздела и не требует внешней базы данных.
Обнаружение служб
- CoreDNS - это гибкий, расширяемый DNS-сервер, который может быть установлен в качестве внутрикластерного DNS для подов.
Визуализация и контроль
- Dashboard - это веб-интерфейс панели инструментов для Kubernetes.
- Weave Scope - это инструмент для графической визуализации ваших контейнеров, подов, сервисов и т.д. Используйте его вместе с учетной записью Weave Cloud или разместите пользовательский интерфейс самостоятельно.
Инфраструктура
- KubeVirt - это дополнение для запуска виртуальных машин в Kubernetes. Обычно работает на bare-metal кластерах.
Legacy Add-ons
В устаревшем каталоге cluster/addons задокументировано несколько других дополнений.
Ссылки на те, в хорошем состоянии, должны быть здесь. Пул реквесты приветствуются!