Version imprimable multipages. Cliquer ici pour imprimer.
Architecture de Kubernetes
1 - Noeuds
Un nœud est une machine de travail dans Kubernetes, connue auparavant sous le nom de minion.
Un nœud peut être une machine virtuelle ou une machine physique, selon le cluster.
Chaque nœud contient les services nécessaires à l'exécution de pods et est géré par les composants du master.
Les services sur un nœud incluent le container runtime, kubelet et kube-proxy.
Consultez la section Le Nœud Kubernetes dans le document de conception de l'architecture pour plus de détails.
Statut du nœud
Le statut d'un nœud contient les informations suivantes:
Chaque section est décrite en détail ci-dessous.
Adresses
L'utilisation de ces champs varie en fonction de votre fournisseur de cloud ou de votre configuration physique.
- HostName: Le nom d'hôte tel que rapporté par le noyau du nœud. Peut être remplacé via le paramètre kubelet
--hostname-override. - ExternalIP: En règle générale, l'adresse IP du nœud pouvant être routé en externe (disponible de l'extérieur du cluster).
- InternalIP: En règle générale, l'adresse IP du nœud pouvant être routé uniquement dans le cluster.
Condition
Le champ conditions décrit le statut de tous les nœuds Running.
| Node Condition | Description |
|---|---|
OutOfDisk |
True si l'espace disponible sur le nœud est insuffisant pour l'ajout de nouveaux pods, sinon False |
Ready |
True si le noeud est sain et prêt à accepter des pods, False si le noeud n'est pas sain et n'accepte pas de pods, et Unknown si le contrôleur de noeud n'a pas reçu d'information du noeud depuis node-monitor-grace-period (la valeur par défaut est de 40 secondes) |
MemoryPressure |
True s'il existe une pression sur la mémoire du noeud, c'est-à-dire si la mémoire du noeud est faible; autrement False |
PIDPressure |
True s'il existe une pression sur le nombre de processus, c'est-à-dire s'il y a trop de processus sur le nœud; autrement False |
DiskPressure |
True s'il existe une pression sur la taille du disque, c'est-à-dire si la capacité du disque est faible; autrement False |
NetworkUnavailable |
True si le réseau pour le noeud n'est pas correctement configuré, sinon False |
La condition de noeud est représentée sous la forme d'un objet JSON. Par exemple, la réponse suivante décrit un nœud sain.
"conditions": [
{
"type": "Ready",
"status": "True"
}
]
Si le statut de l'état Ready reste Unknown ou False plus longtemps que pod-eviction-timeout, un argument est passé au kube-controller-manager et les pods sur le nœud sont programmés pour être supprimés par le contrôleur du nœud.
Le délai d’expulsion par défaut est de cinq minutes..
Dans certains cas, lorsque le nœud est inaccessible, l'apiserver est incapable de communiquer avec le kubelet sur le nœud.
La décision de supprimer les pods ne peut pas être communiquée au kublet tant que la communication avec l'apiserver n'est pas rétablie.
Entre-temps, les pods dont la suppression est planifiée peuvent continuer à s'exécuter sur le nœud inaccessible.
Dans les versions de Kubernetes antérieures à 1.5, le contrôleur de noeud forcait la suppression de ces pods inaccessibles de l'apiserver.
Toutefois, dans la version 1.5 et ultérieure, le contrôleur de noeud ne force pas la suppression des pods tant qu'il n'est pas confirmé qu'ils ont cessé de fonctionner dans le cluster.
Vous pouvez voir que les pods en cours d'exécution sur un nœud inaccessible sont dans l'état Terminating ou Unknown.
Dans les cas où Kubernetes ne peut pas déduire de l'infrastructure sous-jacente si un nœud a définitivement quitté un cluster, l'administrateur du cluster peut avoir besoin de supprimer l'objet nœud à la main.
La suppression de l'objet nœud de Kubernetes entraîne la suppression de tous les objets Pod exécutés sur le nœud de l'apiserver et libère leurs noms.
Dans la version 1.12, la fonctionnalité TaintNodesByCondition est promue en version bêta, ce qui permet au contrôleur de cycle de vie du nœud de créer automatiquement des marquages (taints en anglais) qui représentent des conditions.
De même, l'ordonnanceur ignore les conditions lors de la prise en compte d'un nœud; au lieu de cela, il regarde les taints du nœud et les tolérances d'un pod.
Les utilisateurs peuvent désormais choisir entre l'ancien modèle de planification et un nouveau modèle de planification plus flexible. Un pod qui n’a aucune tolérance est programmé selon l’ancien modèle. Mais un pod qui tolère les taints d'un nœud particulier peut être programmé sur ce nœud.
Avertissement:
L'activation de cette fonctionnalité crée un léger délai entre le moment où une condition est observée et le moment où une taint est créée. Ce délai est généralement inférieur à une seconde, mais il peut augmenter le nombre de pods programmés avec succès mais rejetés par le kubelet.Capacité
Décrit les ressources disponibles sur le nœud: CPU, mémoire et nombre maximal de pods pouvant être planifiés sur le nœud.
Info
Informations générales sur le noeud, telles que la version du noyau, la version de Kubernetes (versions de kubelet et kube-proxy), la version de Docker (si utilisée), le nom du système d'exploitation. Les informations sont collectées par Kubelet à partir du noeud.
Gestion
Contrairement aux pods et aux services, un nœud n'est pas créé de manière inhérente par Kubernetes: il est créé de manière externe par un cloud tel que Google Compute Engine, ou bien il existe dans votre pool de machines physiques ou virtuelles. Ainsi, lorsque Kubernetes crée un nœud, il crée un objet qui représente le nœud. Après la création, Kubernetes vérifie si le nœud est valide ou non. Par exemple, si vous essayez de créer un nœud à partir du contenu suivant:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}
Kubernetes crée un objet noeud en interne (la représentation) et valide le noeud en vérifiant son intégrité en fonction du champ metadata.name.
Si le nœud est valide, c'est-à-dire si tous les services nécessaires sont en cours d'exécution, il est éligible pour exécuter un pod.
Sinon, il est ignoré pour toute activité de cluster jusqu'à ce qu'il devienne valide.
Note:
Kubernetes conserve l'objet pour le nœud non valide et vérifie s'il devient valide. Vous devez explicitement supprimer l'objet Node pour arrêter ce processus.Actuellement, trois composants interagissent avec l'interface de noeud Kubernetes: le contrôleur de noeud, kubelet et kubectl.
Contrôleur de nœud
Le contrôleur de noeud (node controller en anglais) est un composant du master Kubernetes qui gère divers aspects des noeuds.
Le contrôleur de nœud a plusieurs rôles dans la vie d'un nœud. La première consiste à affecter un bloc CIDR au nœud lorsqu’il est enregistré (si l’affectation CIDR est activée).
La seconde consiste à tenir à jour la liste interne des nœuds du contrôleur de nœud avec la liste des machines disponibles du fournisseur de cloud. Lorsqu'il s'exécute dans un environnement de cloud, chaque fois qu'un nœud est en mauvaise santé, le contrôleur de nœud demande au fournisseur de cloud si la machine virtuelle de ce nœud est toujours disponible. Sinon, le contrôleur de nœud supprime le nœud de sa liste de nœuds.
La troisième est la surveillance de la santé des nœuds. Le contrôleur de noeud est responsable de la mise à jour de la condition NodeReady de NodeStatus vers ConditionUnknown lorsqu'un noeud devient inaccessible (le contrôleur de noeud cesse de recevoir des heartbeats pour une raison quelconque, par exemple en raison d'une panne du noeud), puis de l'éviction ultérieure de tous les pods du noeud. (en utilisant une terminaison propre) si le nœud continue d’être inaccessible. (Les délais d'attente par défaut sont de 40 secondes pour commencer à signaler ConditionUnknown et de 5 minutes après cela pour commencer à expulser les pods.)
Le contrôleur de nœud vérifie l'état de chaque nœud toutes les --node-monitor-period secondes.
Dans les versions de Kubernetes antérieures à 1.13, NodeStatus correspond au heartbeat du nœud.
À partir de Kubernetes 1.13, la fonctionnalité de bail de nœud (node lease en anglais) est introduite en tant que fonctionnalité alpha (feature gate NodeLease, KEP-0009).
Lorsque la fonction de node lease est activée, chaque noeud a un objet Lease associé dans le namespace kube-node-lease qui est renouvelé périodiquement par le noeud, et NodeStatus et le node lease sont traités comme des heartbeat du noeud.
Les node leases sont renouvelés fréquemment lorsque NodeStatus est signalé de nœud à master uniquement lorsque des modifications ont été apportées ou que suffisamment de temps s'est écoulé (la valeur par défaut est 1 minute, ce qui est plus long que le délai par défaut de 40 secondes pour les nœuds inaccessibles).
Étant donné qu'un node lease est beaucoup plus léger qu'un NodeStatus, cette fonctionnalité rends le heartbeat d'un nœud nettement moins coûteux, tant du point de vue de l'évolutivité que des performances.
Dans Kubernetes 1.4, nous avons mis à jour la logique du contrôleur de noeud afin de mieux gérer les cas où un grand nombre de noeuds rencontrent des difficultés pour atteindre le master (par exemple parce que le master a un problème de réseau). À partir de la version 1.4, le contrôleur de noeud examine l’état de tous les noeuds du cluster lorsqu’il prend une décision concernant l’éviction des pods.
Dans la plupart des cas, le contrôleur de noeud limite le taux d’expulsion à --node-eviction-rate (0,1 par défaut) par seconde, ce qui signifie qu’il n’expulsera pas les pods de plus d’un nœud toutes les 10 secondes.
Le comportement d'éviction de noeud change lorsqu'un noeud d'une zone de disponibilité donnée devient défaillant.
Le contrôleur de nœud vérifie quel pourcentage de nœuds de la zone est défaillant (la condition NodeReady est ConditionUnknown ou ConditionFalse) en même temps.
Si la fraction de nœuds défaillant est au moins --unhealthy-zone-threshold (valeur par défaut de 0,55), le taux d'expulsion est réduit: si le cluster est petit (c'est-à-dire inférieur ou égal à --large-cluster-size-threshold noeuds - valeur par défaut 50) puis les expulsions sont arrêtées, sinon le taux d'expulsion est réduit à --secondary-node-eviction-rate (valeur par défaut de 0,01) par seconde.
Ces stratégies sont implémentées par zone de disponibilité car une zone de disponibilité peut être partitionnée à partir du master, tandis que les autres restent connectées. Si votre cluster ne s'étend pas sur plusieurs zones de disponibilité de fournisseur de cloud, il n'existe qu'une seule zone de disponibilité (la totalité du cluster).
L'une des principales raisons de la répartition de vos nœuds entre les zones de disponibilité est de pouvoir déplacer la charge de travail vers des zones saines lorsqu'une zone entière tombe en panne.
Par conséquent, si tous les nœuds d’une zone sont défaillants, le contrôleur de nœud expulse à la vitesse normale --node-eviction-rate.
Le cas pathologique se produit lorsque toutes les zones sont complètement défaillantes (c'est-à-dire qu'il n'y a pas de nœuds sains dans le cluster).
Dans ce cas, le contrôleur de noeud suppose qu'il existe un problème de connectivité au master et arrête toutes les expulsions jusqu'à ce que la connectivité soit restaurée.
À partir de Kubernetes 1.6, NodeController est également responsable de l'expulsion des pods s'exécutant sur des noeuds avec des marques NoExecute, lorsque les pods ne tolèrent pas ces marques.
De plus, en tant que fonctionnalité alpha désactivée par défaut, NodeController est responsable de l'ajout de marques correspondant aux problèmes de noeud tels que les noeuds inaccessibles ou non prêts.
Voir cette documentation pour plus de détails sur les marques NoExecute et cette fonctionnalité alpha.
À partir de la version 1.8, le contrôleur de noeud peut être chargé de créer des tâches représentant les conditions de noeud. Ceci est une fonctionnalité alpha de la version 1.8.
Auto-enregistrement des nœuds
Lorsque l'indicateur de kubelet --register-node est à true (valeur par défaut), le kubelet tente de s'enregistrer auprès du serveur d'API.
C'est le modèle préféré, utilisé par la plupart des distributions Linux.
Pour l'auto-enregistrement (self-registration en anglais), le kubelet est lancé avec les options suivantes:
--kubeconfig- Chemin d'accès aux informations d'identification pour s'authentifier auprès de l'apiserver.--cloud-provider- Comment lire les métadonnées d'un fournisseur de cloud sur lui-même.--register-node- Enregistrement automatique avec le serveur API.--register-with-taints- Enregistrez le noeud avec la liste donnée de marques (séparés par des virgules<key>=<value>:<effect>). Sans effet siregister-nodeest à false.--node-ip- Adresse IP du noeud.--node-labels- Labels à ajouter lors de l’enregistrement du noeud dans le cluster (voir Restrictions des labels appliquées par le plugin NodeRestriction admission dans les versions 1.13+).--node-status-update-frequency- Spécifie la fréquence à laquelle kubelet publie le statut de nœud sur master.
Quand le mode autorisation de nœud et plugin NodeRestriction admission sont activés, les kubelets sont uniquement autorisés à créer / modifier leur propre ressource de noeud.
Administration manuelle de noeuds
Un administrateur de cluster peut créer et modifier des objets de nœud.
Si l'administrateur souhaite créer des objets de noeud manuellement, définissez l'argument de kubelet: --register-node=false.
L'administrateur peut modifier les ressources du nœud (quel que soit le réglage de --register-node).
Les modifications comprennent la définition de labels sur le nœud et son marquage comme non programmable.
Les étiquettes sur les nœuds peuvent être utilisées avec les sélecteurs de nœuds sur les pods pour contrôler la planification. Par exemple, pour contraindre un pod à ne pouvoir s'exécuter que sur un sous-ensemble de nœuds.
Marquer un nœud comme non planifiable empêche la planification de nouveaux pods sur ce nœud, mais n'affecte pas les pods existants sur le nœud. Ceci est utile comme étape préparatoire avant le redémarrage d'un nœud, etc. Par exemple, pour marquer un nœud comme non programmable, exécutez la commande suivante:
kubectl cordon $NODENAME
Note:
Les pods créés par un contrôleur DaemonSet contournent le planificateur Kubernetes et ne respectent pas l'attribut unschedulable sur un nœud. Cela suppose que les démons appartiennent à la machine même si celle-ci est en cours de vidage des applications pendant qu'elle se prépare au redémarrage.Capacité de nœud
La capacité du nœud (nombre de CPU et quantité de mémoire) fait partie de l’objet Node. Normalement, les nœuds s'enregistrent et indiquent leur capacité lors de la création de l'objet Node. Si vous faites une administration manuelle de nœud, alors vous devez définir la capacité du nœud lors de l'ajout d'un nœud.
Le scheduler Kubernetes veille à ce qu'il y ait suffisamment de ressources pour tous les pods d'un noeud. Il vérifie que la somme des demandes des conteneurs sur le nœud n'est pas supérieure à la capacité du nœud. Cela inclut tous les conteneurs lancés par le kubelet, mais pas les conteneurs lancés directement par le conteneur runtime, ni aucun processus exécuté en dehors des conteneurs.
Si vous souhaitez réserver explicitement des ressources pour des processus autres que Pod, suivez ce tutoriel pour: réserver des ressources pour les démons système.
API Object
L'objet Node est une ressource de niveau supérieur dans l'API REST de Kubernetes. Plus de détails sur l'objet API peuvent être trouvés à l'adresse suivante: Node API object.
2 - Communication Master-Node
Ce document répertorie les canaux de communication entre l'API du noeud maître (apiserver of master node en anglais) et le reste du cluster Kubernetes. L'objectif est de permettre aux utilisateurs de personnaliser leur installation afin de sécuriser la configuration réseau, de sorte que le cluster puisse être exécuté sur un réseau non approuvé (ou sur des adresses IP entièrement publiques d'un fournisseur de cloud).
Communication du Cluster vers le Master
Tous les canaux de communication du cluster au master se terminent à l'apiserver (aucun des autres composants principaux n'est conçu pour exposer des services distants). Dans un déploiement typique, l'apiserver est configuré pour écouter les connexions distantes sur un port HTTPS sécurisé (443) avec un ou plusieurs types d'authentification client. Une ou plusieurs formes d'autorisation devraient être activées, notamment si les requêtes anonymes ou jeton de compte de service sont autorisés.
Le certificat racine public du cluster doit être configuré pour que les nœuds puissent se connecter en toute sécurité à l'apiserver avec des informations d'identification client valides. Par exemple, dans un déploiement GKE par défaut, les informations d'identification client fournies au kubelet sont sous la forme d'un certificat client. Consultez amorçage TLS de kubelet pour le provisioning automatisé des certificats de client Kubelet.
Les pods qui souhaitent se connecter à l'apiserver peuvent le faire de manière sécurisée en utilisant un compte de service afin que Kubernetes injecte automatiquement le certificat racine public et un jeton de support valide dans le pod lorsqu'il est instancié.
Le service kubernetes (dans tous les namespaces) est configuré avec une adresse IP virtuelle redirigée (via kube-proxy) vers le point de terminaison HTTPS sur l'apiserver.
Les composants du master communiquent également avec l'apiserver du cluster via le port sécurisé.
Par conséquent, le mode de fonctionnement par défaut pour les connexions du cluster (nœuds et pods s'exécutant sur les nœuds) au master est sécurisé par défaut et peut s'exécuter sur des réseaux non sécurisés et/ou publics.
Communication du Master vers le Cluster
Il existe deux voies de communication principales du master (apiserver) au cluster. La première est du processus apiserver au processus kubelet qui s'exécute sur chaque nœud du cluster. La seconde part de l'apiserver vers n'importe quel nœud, pod ou service via la fonctionnalité proxy de l'apiserver.
Communication de l'apiserver vers le kubelet
Les connexions de l'apiserver au kubelet sont utilisées pour:
- Récupérer les logs des pods.
- S'attacher (via kubectl) à des pods en cours d'exécution.
- Fournir la fonctionnalité de transfert de port du kubelet.
Ces connexions se terminent au point de terminaison HTTPS du kubelet. Par défaut, l'apiserver ne vérifie pas le certificat du kubelet, ce qui rend la connexion sujette aux attaques de type "man-in-the-middle", et non sûre sur des réseaux non approuvés et/ou publics.
Pour vérifier cette connexion, utilisez l'argument --kubelet-certificate-authority pour fournir à l'apiserver un ensemble de certificats racine à utiliser pour vérifier le certificat du kubelet.
Si ce n'est pas possible, utilisez SSH tunneling entre l'apiserver et le kubelet si nécessaire pour éviter la connexion sur un réseau non sécurisé ou public.
Finalement, l'authentification et/ou autorisation du Kubelet devrait être activée pour sécuriser l'API kubelet.
apiserver vers nodes, pods et services
Les connexions de l'apiserver à un nœud, à un pod ou à un service sont définies par défaut en connexions HTTP.
Elles ne sont donc ni authentifiées ni chiffrées.
Elles peuvent être exécutées sur une connexion HTTPS sécurisée en préfixant https: au nom du nœud, du pod ou du service dans l'URL de l'API.
Cependant ils ne valideront pas le certificat fourni par le point de terminaison HTTPS ni ne fourniront les informations d'identification du client.
De plus, aucune garantie d'intégrité n'est fournie.
Ces connexions ne sont actuellement pas sûres pour fonctionner sur des réseaux non sécurisés et/ou publics.
SSH Tunnels
Kubernetes prend en charge les tunnels SSH pour protéger les communications master -> cluster. Dans cette configuration, l'apiserver initie un tunnel SSH vers chaque nœud du cluster (en se connectant au serveur ssh sur le port 22) et transmet tout le trafic destiné à un kubelet, un nœud, un pod ou un service via un tunnel. Ce tunnel garantit que le trafic n'est pas exposé en dehors du réseau dans lequel les nœuds sont en cours d'exécution.
Les tunnels SSH étant actuellement obsolètes, vous ne devriez pas choisir de les utiliser à moins de savoir ce que vous faites. Un remplacement pour ce canal de communication est en cours de conception.
3 - Concepts sous-jacents au Cloud Controller Manager
Le concept de cloud controller manager (CCM) (ne pas confondre avec le binaire) a été créé à l'origine pour permettre au code de fournisseur spécifique de cloud et au noyau Kubernetes d'évoluer indépendamment les uns des autres. Le gestionnaire de contrôleur de cloud fonctionne aux côtés d'autres composants principaux, tels que le gestionnaire de contrôleur Kubernetes, le serveur d'API et le planificateur. Il peut également être démarré en tant qu’addon Kubernetes, auquel cas il s’exécute sur Kubernetes.
La conception du gestionnaire de contrôleur de cloud repose sur un mécanisme de plugin qui permet aux nouveaux fournisseurs de cloud de s'intégrer facilement à Kubernetes à l'aide de plugins. Des plans sont en place pour intégrer de nouveaux fournisseurs de cloud sur Kubernetes et pour migrer les fournisseurs de cloud de l'ancien modèle vers le nouveau modèle CCM.
Ce document discute des concepts derrière le cloud controller manager et donne des détails sur ses fonctions associées.
Voici l'architecture d'un cluster Kubernetes sans le cloud controller manager:
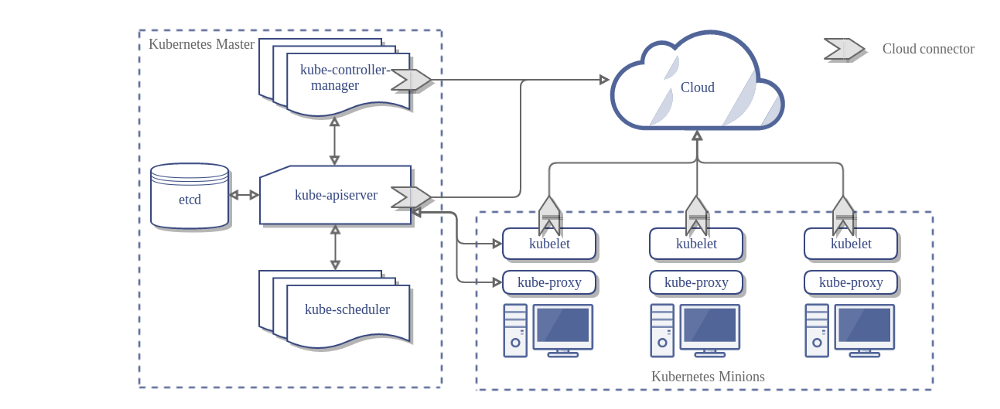
Conception
Dans le diagramme précédent, Kubernetes et le fournisseur de cloud sont intégrés via plusieurs composants différents:
- Kubelet
- Kubernetes controller manager
- Kubernetes API server
Le CCM consolide toute la logique dépendante du cloud des trois composants précédents pour créer un point d’intégration unique avec le cloud. La nouvelle architecture avec le CCM se présente comme suit:
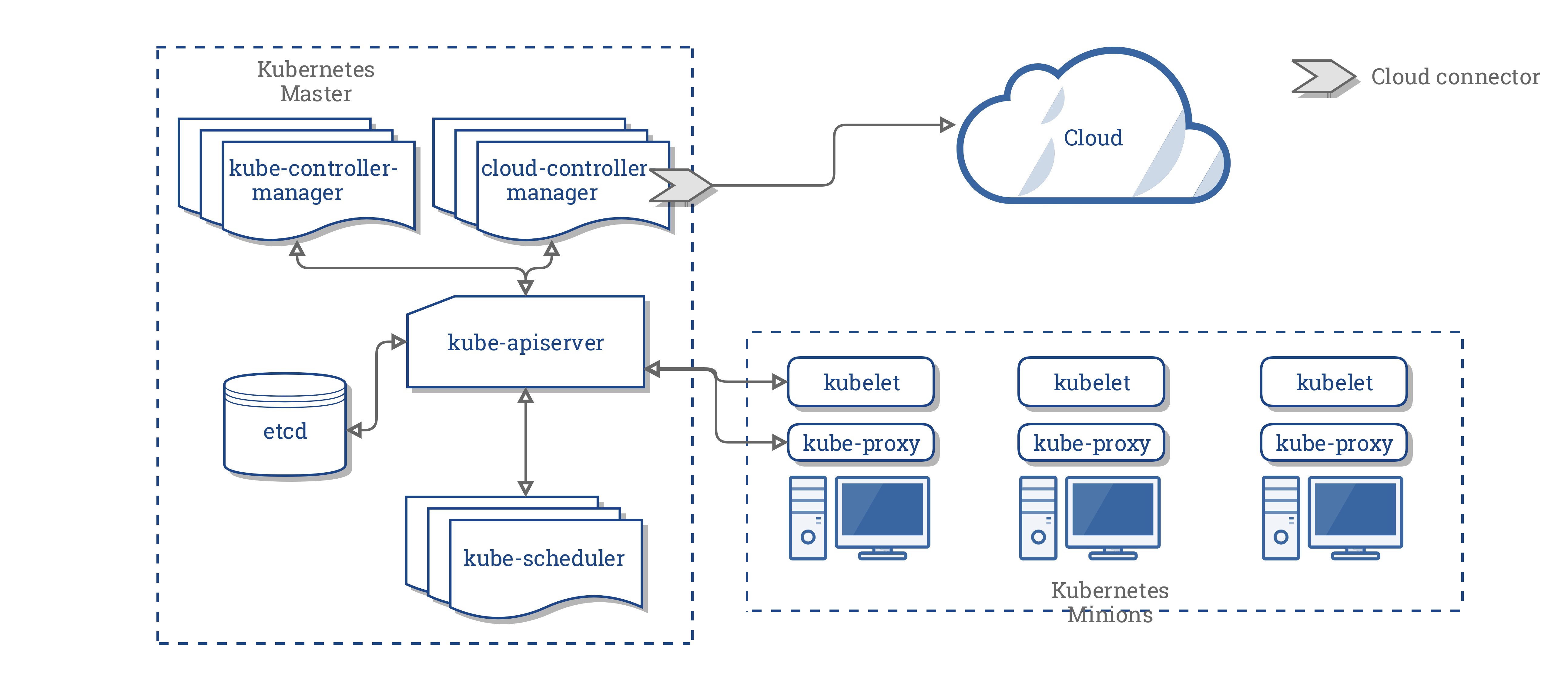
Composants du CCM
Le CCM rompt certaines fonctionnalités du Kubernetes Controller Manager (KCM) et les exécute en tant que processus séparé. Plus précisément, il sépare les contrôleurs du KCM qui dépendent du cloud. Le KCM comporte les boucles de contrôle dépendant du cloud suivantes:
- Contrôleur de nœud
- Contrôleur de volume
- Contrôleur de route
- Contrôleur de service
Dans la version 1.9, le CCM exécute les contrôleurs suivants de la liste précédente:
- Contrôleur de nœud
- Contrôleur de route
- Contrôleur de service
Note:
Le contrôleur de volume a été délibérément choisi pour ne pas faire partie de CCM. En raison de la complexité du processus et des efforts déployés pour supprimer la logique de volume spécifique au fournisseur, il a été décidé que le contrôleur de volume ne serait pas déplacé vers CCM.Le plan initial de prise en charge des volumes à l'aide de CCM consistait à utiliser des volumes Flex pour prendre en charge des volumes pouvant être connectés. Cependant, un effort concurrentiel appelé CSI est prévu pour remplacer Flex.
Compte tenu de cette dynamique, nous avons décidé d'avoir une mesure de transition intermédiaire jusqu'à ce que le CSI soit prêt.
Fonctions du CCM
Le CCM hérite ses fonctions des composants de Kubernetes qui dépendent d'un fournisseur de cloud. Cette section est structurée en fonction de ces composants.
1. Kubernetes controller manager
La majorité des fonctions du CCM sont dérivées du KCM. Comme indiqué dans la section précédente, le CCM exécute les boucles de contrôle suivantes:
- Contrôleur de nœud
- Contrôleur de route
- Contrôleur de service
Contrôleur de nœud
Le contrôleur de noeud est responsable de l'initialisation d'un noeud en obtenant des informations sur les noeuds s'exécutant dans le cluster auprès du fournisseur de cloud. Le contrôleur de noeud exécute les fonctions suivantes:
- Il initialise le nœud avec des labels de zone/région spécifiques au cloud.
- Il initialise le nœud avec des détails d'instance spécifiques au cloud, tels que le type et la taille de l'instance.
- Il obtient les adresses réseau et le nom d'hôte du nœud.
- Si un nœud ne répond plus, le controlleur vérifie avec le cloud pour voir s'il a été supprimé du cloud. Si le nœud a été supprimé du cloud, le controlleur supprime l'objet Kubernetes Node.
Contrôleur de route
Le contrôleur de route est responsable de la configuration appropriée des itinéraires dans le cloud afin que les conteneurs situés sur différents nœuds du cluster Kubernetes puissent communiquer entre eux. Le contrôleur de route ne s'applique qu'aux clusters Google Compute Engine.
Contrôleur de service
Le contrôleur de service est chargé d'écouter les événements de création, de mise à jour et de suppression de service. En fonction de l'état actuel des services dans Kubernetes, il configure les équilibreurs de charge dans le cloud (tels que ELB, Google LB ou Oracle Cloud Infrastructure LB) pour refléter l'état des services dans Kubernetes. De plus, cela garantit que les services de base des services pour les load balancers dans le cloud sont à jour.
2. Kubelet
Le contrôleur de noeud contient les fonctionnalités du kubelet dépendant du cloud. Avant l'introduction du CCM, la sous-unité était responsable de l'initialisation d'un nœud avec des détails spécifiques au cloud, tels que les adresses IP, les étiquettes de région / zone et les informations de type d'instance. L’introduction du CCM a déplacé cette opération d’initialisation du kubelet vers le CCM.
Dans ce nouveau modèle, le kubelet initialise un nœud sans informations spécifiques au cloud. Cependant, il ajoute un marquage au nœud nouvellement créé, qui rend le nœud non planifiable jusqu'à ce que le CCM initialise le nœud avec des informations spécifiques au cloud. Il supprime ensuite ce marquage.
Mécanisme de plugin
Le cloud controller manager utilise des interfaces Go pour autoriser la mise en œuvre d'implémentations depuis n'importe quel cloud. Plus précisément, il utilise l'interface CloudProvider définie ici.
La mise en œuvre des quatre contrôleurs partagés soulignés ci-dessus, ainsi que certaines configurations ainsi que l'interface partagée du fournisseur de cloud, resteront dans le noyau Kubernetes. Les implémentations spécifiques aux fournisseurs de cloud seront construites en dehors du noyau et implémenteront les interfaces définies dans le noyau.
Pour plus d’informations sur le développement de plugins, consultez Developing Cloud Controller Manager.
Autorisation
Cette section détaille les accès requis par le CCM sur divers objets API pour effectuer ses opérations.
Contrôleur de nœud
Le contrôleur de noeud ne fonctionne qu'avec les objets de noeud. Il nécessite un accès complet aux objets Node via get, list, create, update, patch, watch et delete.
v1/Node:
- Get
- List
- Create
- Update
- Patch
- Watch
- Delete
Contrôleur de route
Le contrôleur de route écoute les évenements de création d'objet Node et configure les routes de manière appropriée. Cela nécessite un accès get aux objets Node.
v1/Node:
- Get
Contrôleur de Service
Le contrôleur de service écoute les évenements de création, suppression et mises à jour des objets Service et configure les endpoints pour ces Services de manière appropriée.
Pour accéder aux Services, il faut les accès list et watch. Pour mettre à jour les Services, il faut les accès patch et update.
Pour configurer des points de terminaison pour les services, vous devez avoir accès au create, list, get, watch, et update.
v1/Service:
- List
- Get
- Watch
- Patch
- Update
Autres
La mise en œuvre du CCM nécessite un accès pour créer des événements, et pour garantir un fonctionnement sécurisé, un accès est nécessaire pour créer ServiceAccounts.
v1/Event:
- Create
- Patch
- Update
v1/ServiceAccount:
- Create
Le ClusterRole RBAC pour le CCM ressemble à ceci:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
Implémentations des fournisseurs de cloud
Les fournisseurs de cloud suivants ont implémenté leur CCM:
Administration de cluster
Des instructions complètes pour la configuration et l'exécution du CCM sont fournies ici.